
Apple在每年的WWDC都會發表自己的新技術,其中機器學習方面有Core ML與訓練用的Create ML等。其中Create ML讓開發者不需要了解太多機器學習的原理就可以訓練出自己的AI模型,輸出的模型可以用在iPhone、iPad、Mac、Apple Watch、Apple TV等各種平台上,只要簡單的Swift程式碼就可以在App中使用。
本篇文章教學如何在MacBook、Mac mini、Mac Studio等頻果Mac裝置上使用Create ML訓練一個文字分類的AI模型,然後搭配Swift語言與Core ML示範如何在App中使用你自己訓練出來的模型。其中訓練階段你可以完全不會寫任何程式碼就訓練好一個文字模型,還可以在Preview頁面中不寫程式碼直接使用這個模型來分類任何文字,因此不會程式語言的朋友們也能體驗機器學習的魅力。

前置作業
Mac電腦
這邊我使用的是M2版MacBook Air,但就算是最便宜的18,900元的Mac mini也能輕鬆應付文字分類的學習。後來我又試了一台2020年的Intel版MacBook Pro也是數秒內訓練完,幾百則的文字分類訓練毫無壓力。
下載Xcode
Xcode的下載方式很多,最快的方式是直接上App Store搜尋Xcode來下載,這樣只能下載最新版的。第二個方式是上蘋果的開發者網站(https://developer.apple.com/xcode/)挑選喜歡的版本,到網站下載跟上App Store一樣要有蘋果的帳號,初次登入開發者網站要點選同意開發者網站的一些規範。
需要注意Apple的Xcode改版的蠻快的,有時候連官方的教學文件都跟不上Xcode的改版。我寫這篇使用的是Xcode 14.1,在這個版本中到Playground輸入import CreateML已經不能使用,看著Apple的開發者文件操作會報錯。Xcode 14靠圖形界面來完成訓練,因此訓練階段你完全不用寫程式碼。雖然訓練上很方便,但有完全不能用程式碼好像又少了點彈性。
標註資料
這個步驟需要建立有label與text兩個欄位的CSV檔,可以使用VS Code、純文字編輯器、使用Excel也可以,但是既然都用了Mac可以試試看蘋果內建的Numbers,不用另外花錢畫面也很好看。我使用Numbers將原始資料儲存成Numbers專用的格式,方便排序與搜尋等,要訓練時再輸出成CSV檔案,Numbers會幫忙把有換行的、有半型逗號的內容處理好。
在本篇教學中我會以簡訊分類為例,將我收過的簡訊內容分為五類,分別是廣告、購物訂單、帳務資訊、OTP、未接來電。以下是CSV範例。
label,text
OTP,Your https://klab.tw/ verification code is: 888000
OTP,您的驗證碼為000888,請三分鐘內輸入,逾期失效
購物訂單,已接到您的訂單:klab.tw_0001可至顧客中心查詢。
廣告,使用阿里山銀行信用卡繳納綜合所得稅,繳稅不限金額享0.3%現金回饋上限1千元,可同享分期0利率優惠!
帳務通知,中央山脈電信通知您:111年12月電子帳單已寄送,貴客戶0900888888電信費為200元。以上這樣的資料要準備兩份,根據Apple的推薦兩份文件要各有50筆以上的文字,兩份檔案的文字可以類似但不要一樣。我的習慣是用一個Numbers直接整理好一百筆文字,然後輸出成一個CSV檔再自己切兩份檔案。注意每一個CSV檔案的開頭都必須是「label,text」才行。
我將整理好的兩份CSV檔案分別命名為message.csv與message_test.csv。
順便補充說明,訓練AI的時候其實會需要三份資料,分別是訓練資料、驗證資料、測試資料。但是訓練與驗證的資料可以混在一起交給電腦自己抽選,因此我們只需要兩份CSV檔案。
訓練模型
建立CreateML專案
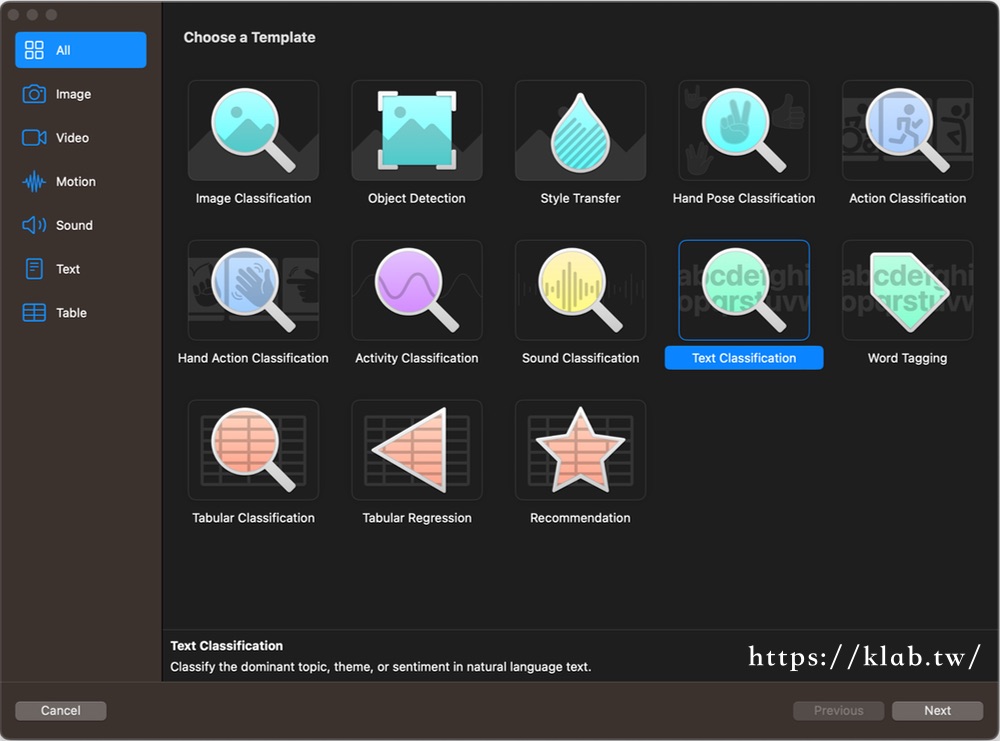
開啟Xcode,點選最上面的選單的「Xcode」,然後點選「Open Developer Tool」的「Create ML」。然後建立一個新的Project,Template選擇「Text Classification」,名稱看各位自己決定,我輸入「MessageClassifier」,再按下「Next」選擇你要儲存此專案的地方就完成了。
訓練與測試
在Setting頁籤會要我們選擇Training Data(訓練資料)、Validation Data(驗證資料)、Testing Data(測試資料),在Training Data選擇message.csv,Validation Data保留Auto不動,然後Testing Data選擇message_test.csv。
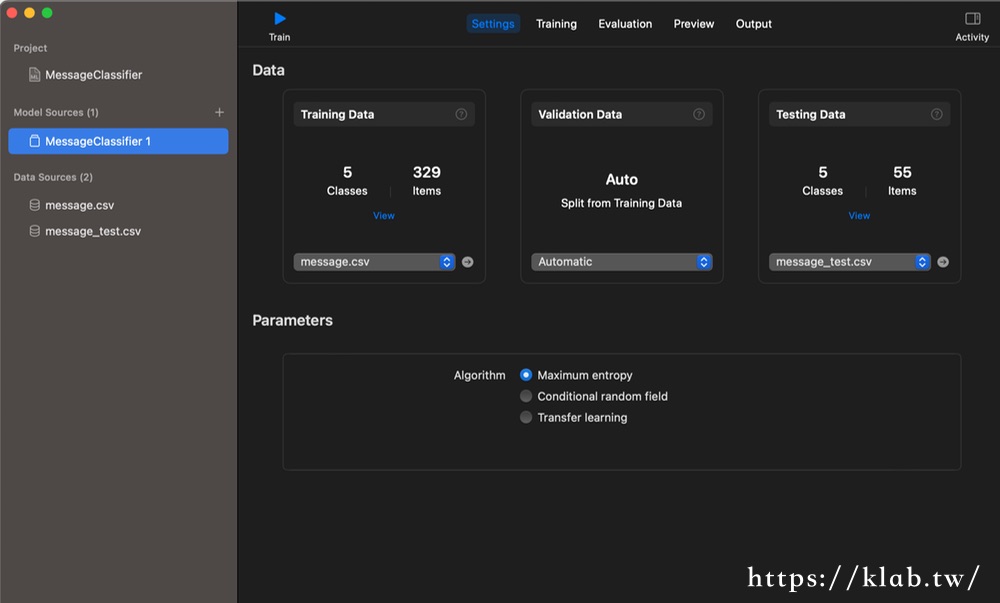
補充一下上圖中左側有一個「Model Sources (1)」,這代表目前設定的訓練資料與測試資料集,可以按下加號在同一個專案內使用不同的訓練與測試資料集來訓練,然後比較不同的Model。
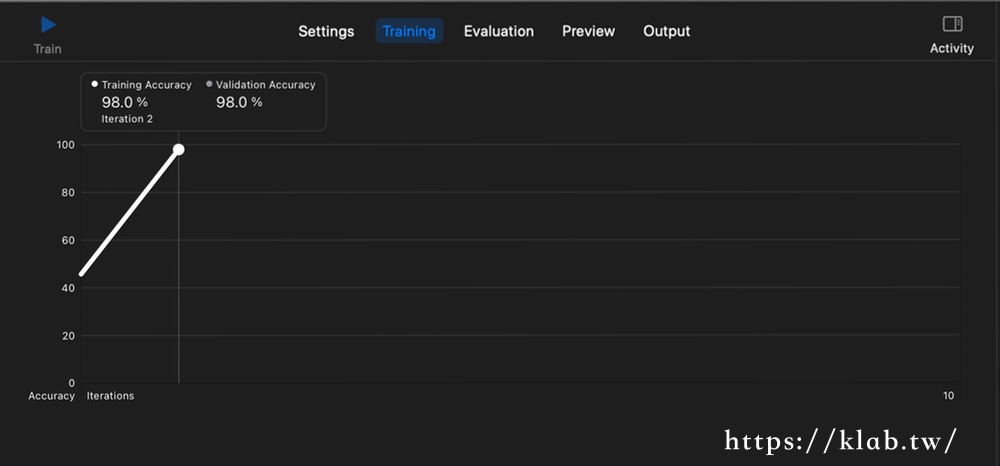
接下來點選左上角的「Train」按鈕就會開始訓練了,訓練中會跳到Training頁籤,從畫面上看到經過2輪的訓練後正確率達到98%,因此自動結束了。
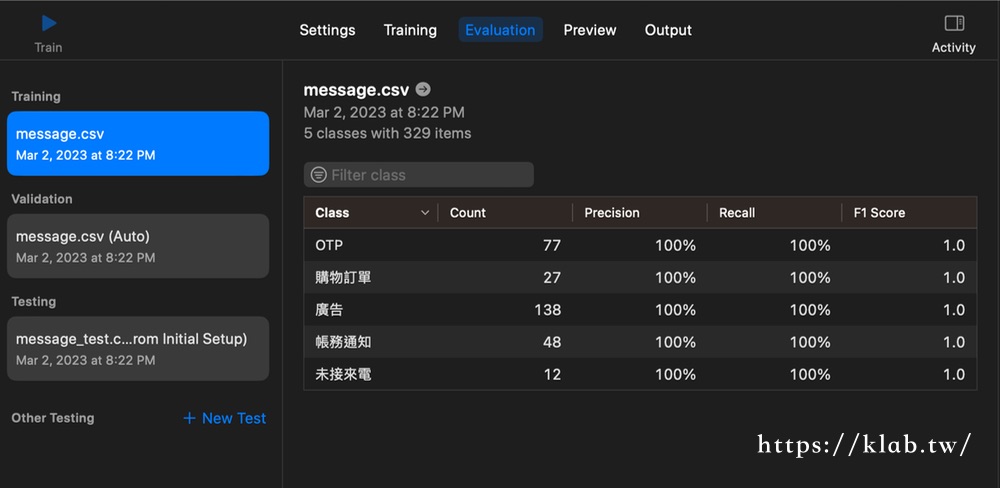
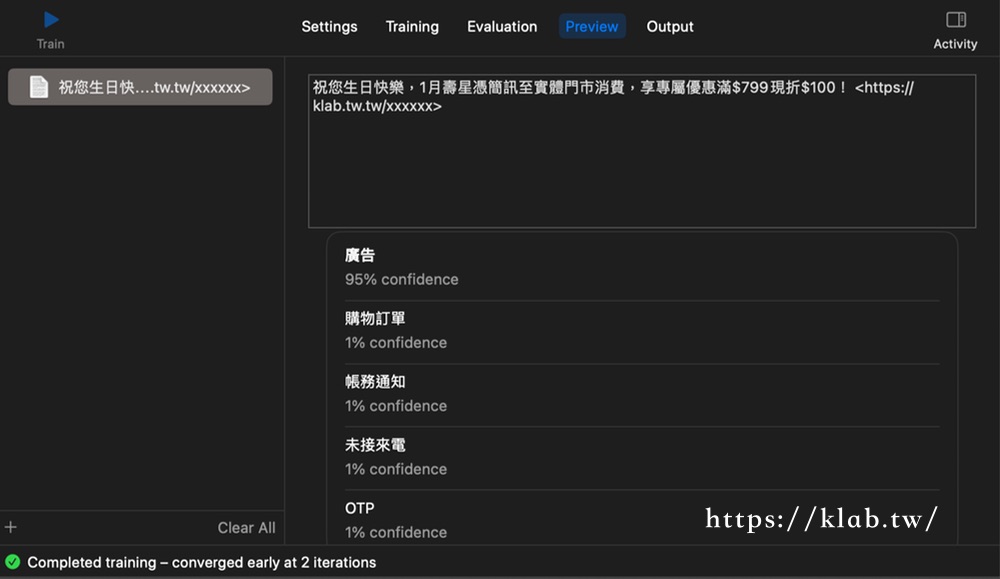
切換到Evaluation頁籤可以看到訓練的結果,然後我們再切換到Preview頁籤就可以直接使用這個模型來預測新的文字內容了。
在Preview頁籤會有左右兩個框,在左邊的框的左下角點選「+」,然後點選「Enter Text」,就會跳出Untitled的文字框,這邊我們可以輸入文字,或是複製貼上任何文字,電腦就會馬上判斷這段文字是什麼標籤的可能性。
輸出模型
在我們的Create ML專案中切換到Output頁籤,會看到這個模型的資訊,例如模型的檔案大小、可以分類的標籤名稱與數量,以及此AI模型支援的macOS、iOS、watchOS、tvOS版本。點選上方的Get就可以獲得我們訓練好的Core ML Model囉。如果你會寫Swift語言,也想將你訓練好的Model放上你的App中使用,可以繼續往下看怎麼將Core ML Model結合App。
結合App
雖然訓練階段不用寫程式,但要結合到App終究要寫程式了,以下在Xcode的Playgound內使用Swift語言來示範如何使用訓練好的模組。需要對Swift語言有一些了解,我有寫一篇Java工程師的Swift學習筆記-上篇可以看看,但一直沒空寫下篇😅。
首先開啟Xcode建立Playground,然後對Resources資料夾點選右鍵按下「Add Files to “Resources”」將之前訓練後產生的「MessageClassifier.mlmodel」加入Resources資料夾,就可以開始寫程式碼了。以下範例會使用Model建立一個文字分類器,命名為predictor。
import Foundation
import CoreML
import NaturalLanguage
// 初始化,"MessageClassifier"是Model的名稱
// 在Playground環境下try後面不接驚嘆號也是可以的,詳細原理要參考Swift語言的例外處理與Optional
let mlModel = try! MessageClassifier(configuration: MLModelConfiguration()).model
let predictor = try! NLModel(mlModel: mlModel)
// 我們要判斷的文章內容
let text = "您的 Klab.tw Blog 認證碼為888888,請於2分鐘內輸入,謝謝。"
// 使用predictedLabel方法獲得文章最有可能的分類
let label = predictor.predictedLabel(for: text)!
print(label) // 輸出:OTP
// 回傳可能性最高的兩個標籤與分數
let dict = predictor.predictedLabelHypotheses(for: text, maximumCount: 2)
print(dict) // 輸出:["OTP": 0.8052849823353586, "帳務通知": 0.05698736417732086]從上面程式碼可以看出初始化模組只要兩行程式碼就可以開始了,非常簡單。
第一個方法使用predictor.predictedLabel回傳的是一個Optional<String>,因此加上驚嘆號來讀取Optional的值,類似Java的Optional.get()一樣,如果值是空的就會報錯,因此也有類似Java的Optional.orElse(T)方法可以給予預設值。但是predictedLabel方法應該不會回傳空值,你輸入任何內容他都會試著給出一個分類標籤,因此直接用這個方法不太好,建議使用第二個方法獲得可信度來判斷。
第二個方法使用predictor.predictedLabelHypotheses回傳的是一個Dictionary<String, Double>,其中Key是每一種可能的分類標籤(Label),Value是可能信,數字0到1之間。需要注意Dictionary的第一個元素不一定是可能性最高的元素,只想要取得可能性最高的標籤可以指定maximumCount,以下提供一個程式範例。
// 回傳可能性最高的一個標籤與分數
let dict = predictor.predictedLabelHypotheses(for: text, maximumCount: 1)
// 取出Dictionary內的第一個元素(也只有這一個)
if let item = dict.first {
let rate = Int(item.value * 100)
print("「\(item.key)」的可能性\(rate)%")
// 輸出:「OTP」的可能性80%
} else {
print("錯誤")
}因為我們設定maximumCount為1,AI模型總會回傳一個元素,所以也可以跳過檢查直接用dict.first!來讀取,再來看你使用Storyboard或是Swift UI來設計介面了。我的成果範例中使用的是Swift UI,我會再寫一篇文章教學如何在Swift UI整合我們的Core ML模型。