
LLM 大語言模型像 ChatGPT、Claude、Gemini、Llama 用起來很厲害,但拿來問公司內部規章、最新新聞、自己的讀書筆記、或是某個冷門開源專案的原始碼時,常常會得到一句「我不知道」或者更糟的——一本正經地胡說八道。原因很單純:模型只認得訓練當下的那批資料,訓練完之後發生的事、私有資料、長尾知識都不在裡面。RAG(Retrieval-Augmented Generation,檢索增強生成)就是為了補上這個缺口而出現的設計。這篇文章會帶大家了解 RAG 是什麼、能做什麼、運作原理(包含 Embedding 與高維度向量空間),以及實務上什麼時候適合用、什麼時候用了反而是錯的,最後整理目前常見的 RAG 軟體選擇。
什麼是 RAG
RAG 全名是 Retrieval-Augmented Generation,中文常翻成「檢索增強生成」。拆開看就是兩件事:先 Retrieval(檢索)從外部資料庫找出與問題相關的文件片段,再把這些片段塞進 prompt 交給 LLM 做 Generation(生成回答)。換句話說,RAG 不是一種新的模型,而是一套「讓 LLM 在回答之前先讀一下參考資料」的工程做法。
這個概念最早是 Facebook AI Research 在 2020 年的論文 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 正式提出,當時的目標是讓 seq2seq 模型可以參考外部知識來回答需要事實依據的問題。後來 LLM 興起之後,這個架構被延伸成現在大家熟悉的「LLM + 向量資料庫」配方,幾乎成了企業導入生成式 AI 的標準起手式。
跟單純的 LLM 比較,RAG 有兩個重要差別。第一個是 知識可以隨時更新,只要把新文件丟進資料庫就好,不需要重新訓練模型;第二個是 回答可以附來源,因為 LLM 看到的是檢索出來的具體段落,可以直接把這些段落的出處標出來,使用者也可以自己回去查證。這兩點正是純粹靠模型內部知識做不到的。
RAG 可以做什麼
RAG 的應用面比想像中廣,只要場景是「LLM 不太熟、但我們手上有資料」幾乎都用得到。以下是目前在企業與個人專案最常看到的幾種典型應用:
- 企業內部知識庫問答:員工手冊、SOP、API 文件、Confluence、Notion 全部餵進去,員工用自然語言問問題,回答還能附原始文件連結。
- 客服機器人:把產品說明書、FAQ、過往工單匯入,比傳統規則式 chatbot 更會處理模糊問題,也比純 LLM 更不容易亂答。
- 法律與醫療輔助查詢:法條、判例、臨床指引這類需要嚴格引用來源的場景,RAG 的「附引用」特性剛好對到需求。
- 個人筆記助手:把 Obsidian、Apple Notes、PDF、論文丟進本地 RAG 系統,就能變成一個只認得自己腦袋的私人秘書。
- 程式碼問答:把整個程式碼倉庫做成向量索引,問「這個函式被誰呼叫」「OAuth 流程寫在哪裡」之類的問題會比純 grep 來得有彈性。
- 最新資訊查詢:搭配每日爬蟲把新聞、財報、論文同步進去,補上 LLM 訓練資料的時間落差。
RAG 怎麼運作
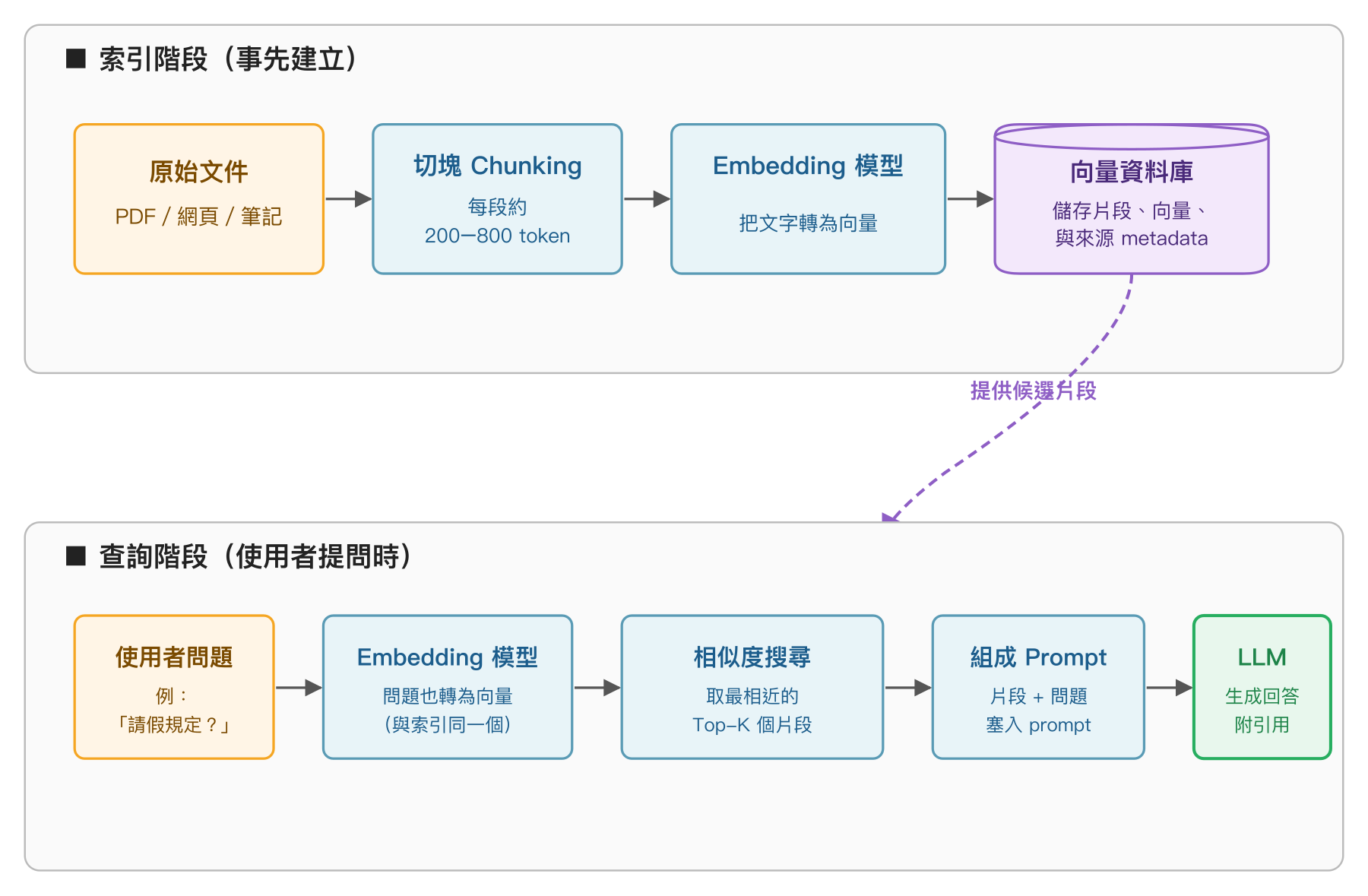
整個 RAG 流程可以拆成兩個階段:索引階段(Indexing,事先把資料準備好)與 查詢階段(Querying,使用者真的提問的當下)。兩個階段都會用到一個關鍵零件——Embedding 模型,這也是 RAG 與傳統關鍵字搜尋最大的差別。
先決定要用哪一個 Embedding 模型
在動手做任何一步之前,第一個要決定的是用哪一個 Embedding 模型。原因很單純:索引與查詢必須用同一個模型,否則兩邊的向量座標系統會對不上,後面的相似度搜尋根本找不到對應的點。中途想換模型的話,整批文件都得重新編碼一次,成本不算小,因此一開始就值得多花一點時間挑。
挑選時通常會看幾個方向:準確度(一般而言越大的模型越準,但延遲與成本也跟著漲)、維度(影響儲存空間與檢索效能,384 維比 3072 維輕快但表達力較弱)、語言支援(中文場景選錯模型搜尋結果會落差很大)、以及部署形式(雲端 API 還是本地自架)。Embedding 模型有哪些?下表整理目前最常被拿來起手的幾個選項:
| 開發者 | 模型 | 維度 | 參數 | 擅長語言 |
|---|---|---|---|---|
| OpenAI | text-embedding-3-small | 1536 | 未公開 | 多語言(含中文) |
| OpenAI | text-embedding-3-large | 3072 | 未公開 | 多語言(含中文) |
| BAAI | bge-m3 | 1024 | 560M | 多語言(100+ 種) |
| BAAI | bge-large-zh-v1.5 | 1024 | 約 335M | 中文為主 |
embeddinggemma | 768 | 308M | 多語言(100+ 種) | |
| Mixedbread AI | mxbai-embed-large-v1 | 1024 | 335M | 英文為主 |
| Nomic AI | nomic-embed-text-v1.5 | 768 | 137M | 英文為主 |
| Sentence-Transformers | all-MiniLM-L6-v2 | 384 | 22M | 英文為主 |
中文場景的話,BAAI 的 bge-m3 與 bge-large-zh-v1.5 是常見起手選擇,它們在中文語料上的表現通常比通用模型好;想用 Google 自家的多語言模型,embeddinggemma 體積不大、覆蓋 100+ 語言,跑在筆電也沒壓力。只用英文又想跑快一點的話,all-MiniLM-L6-v2 跟 nomic-embed-text-v1.5 算便宜耐用;要更高精度的開源英文模型,可以看 mxbai-embed-large-v1。想直接用 OpenAI 雲端服務不打算自架,text-embedding-3-small 在準確度與成本之間取得不錯的平衡,且本身已支援多語言、中文也行,只是需要付費呼叫 API。
表格只列幾個熱門選項,實際上開源 Embedding 模型每隔幾個月都會冒出新的。想看更完整的清單與最近的下載排行,可以直接去 Ollama 的 Embedding 模型分類頁,挑到合適的也能用 Ollama 在本機跑起來。
索引階段:把文件變成向量
索引階段做的事情,是把我們希望 LLM 之後能參考的所有文件處理成一個可以搜尋的資料庫。流程大致如下:
- 文件切塊(Chunking):一份 PDF 或一篇長文不會整篇直接塞進 LLM,會先切成幾百字一段的小區塊。切太大放不進 prompt、切太小又會丟失語境,常見大小是 200–800 token。
- 用 Embedding 模型轉成向量:每一個 chunk 丟進 Embedding 模型,得到一串浮點數(向量),長度通常是 384、768、1024、1536、3072 之類的數字,這個長度叫做「維度」。
- 寫入向量資料庫:把每個 chunk 的「原始文字 + 向量 + metadata(來源、頁碼、時間)」一起寫進向量資料庫,等待之後被搜尋。
Embedding 與高維度向量空間
這邊值得停下來解釋一下什麼是 Embedding。Embedding 模型是一種特別設計過的神經網路,它的任務是把一段文字轉成一串固定長度的浮點數,例如 [0.0213, -0.1442, 0.0857, ..., 0.0091],長度 1536。這串數字看起來像亂數,但其實它代表這段文字在一個「語意空間」裡的座標。
所謂的語意空間是這樣想像的:二維空間就是一張紙,可以用 x、y 兩個座標標出一個點;三維空間是立體,需要 x、y、z 三個座標。如果再加更多軸呢?四維、五維、一直加到 1536 維。人類大腦想像不出 1536 維長什麼樣子(坦白說超過三維就很吃力),但數學上完全合理。Embedding 模型在訓練時就是想辦法把語意相近的文字放在這個高維空間中相鄰的位置,意思相反或無關的文字則放遠一點。
所以一段「貓在沙發上睡覺」的句子和「小貓在沙發上打盹」的句子,雖然用字不一樣,但它們的向量會在這個高維空間中非常靠近;而「貓在沙發上睡覺」和「明天的股市走勢」就會離得很遠。這也是為什麼 RAG 能做到「用自然語言搜尋」——使用者不需要剛好打對關鍵字,只要意思相近就找得到。
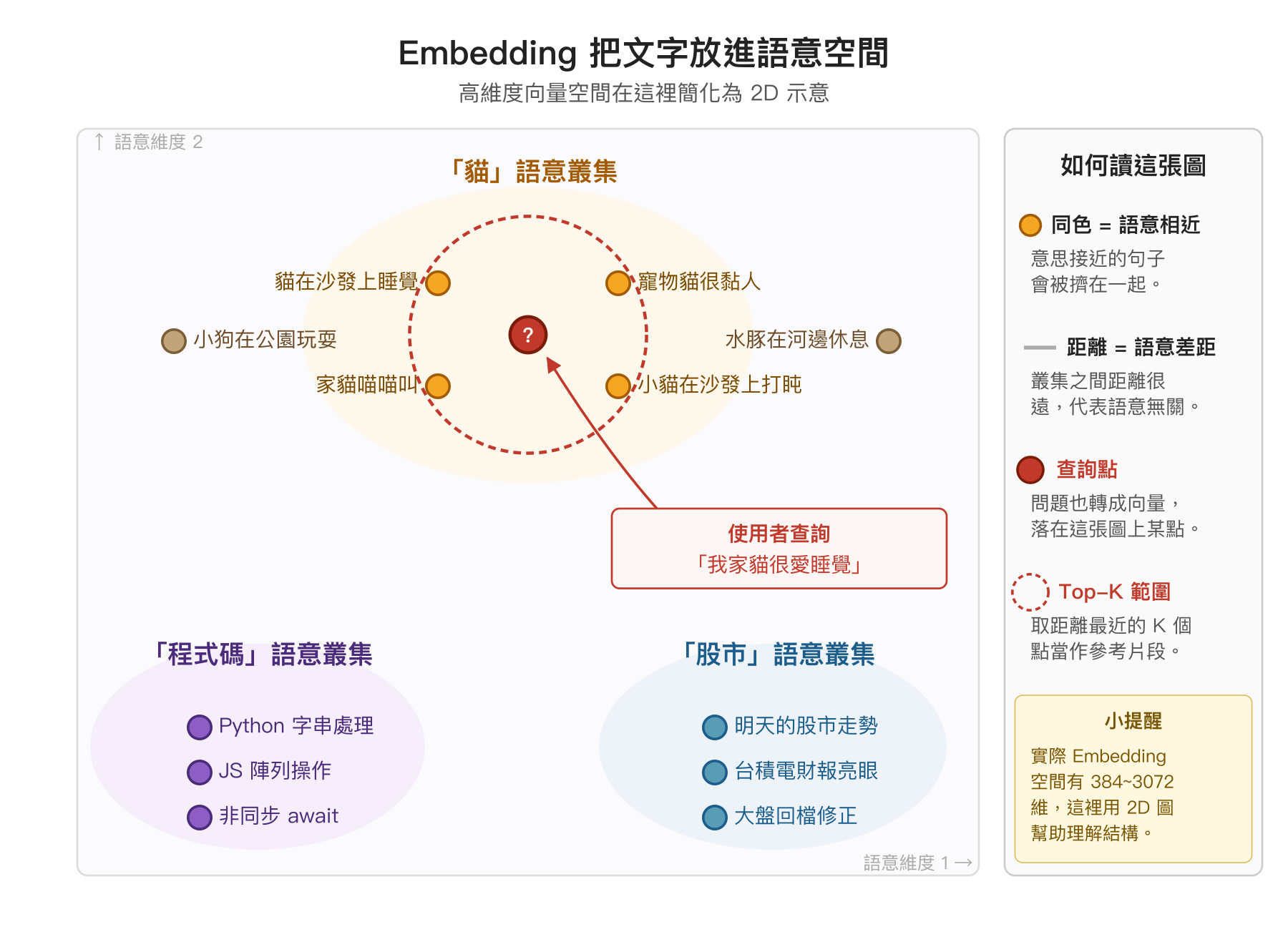
查詢的時候,問題本身也會被同一個 Embedding 模型轉成向量、落在這張圖上某個位置,再從附近撈出距離最近的 K 個點當作參考片段交給 LLM。像「小狗在公園玩耍」「水豚在河邊休息」這類同樣是動物的句子雖然也在語意空間裡,但離「我家貓很愛睡覺」的查詢稍遠,就會被 K 拒於門外——這也是為什麼 K 值與 Embedding 模型本身的好壞,會直接影響最後 LLM 看到的內容品質。
順便釐清一個常見的小困惑:既然 Embedding 算出來就是空間裡的一個座標,為什麼大家都說「向量」而不是「座標」?答案在於這串數字真正會被拿來做的運算。儲存的時候它的確像座標,標出文字落在語意空間的哪裡;但實際在比對相似度的時候,我們會把它視為從原點出發、指向那個位置的箭頭——也就是向量。最常用的 cosine similarity 算的就是兩個向量的夾角;而經典的「king − man + woman ≈ queen」這種語意算術,更是把詞向量加加減減出來的結果,只有把這串數字視為向量才有意義。換句話說,「點」是它躺在那裡的樣子,「向量」則是它被拿來計算的方式,機器學習領域因此習慣選後者當稱呼。
為什麼是 1536 維這種奇怪的數字?這跟 Embedding 模型的架構有關,模型內部最後一層輸出多少個神經元,向量就是多少維。維度越高理論上能表達越細緻的語意差異,但代價是儲存空間、計算成本與資料庫索引大小都會跟著上升——前面表格裡 384、1024、1536、3072 這幾個數字背後其實就是模型大小與精度取捨的結果。
查詢階段:找相似 chunk 拼進 prompt
當使用者真的丟問題進來時,RAG 系統會做以下幾件事:
- 把問題也轉成向量:使用者問「公司請假規定是什麼」,這句話先過同一個 Embedding 模型變成 1536 維向量。重點:索引和查詢一定要用同一個 Embedding 模型,否則兩邊的座標系統對不上。
- 相似度搜尋:拿這個查詢向量去向量資料庫,找出距離最近的前 K 個 chunk(K 通常設 3–10)。距離量測最常用的是 cosine similarity(餘弦相似度),看兩個向量的夾角而不是長度。
- 把結果拼成 prompt:把找到的幾個 chunk 原始文字接在問題前面,組成類似這樣的 prompt:「以下是相關文件,請依此回答問題。文件:[chunk1] [chunk2] [chunk3]。問題:公司請假規定是什麼?」
- 交給 LLM 生成答案:LLM 看到具體文件就會基於這些內容回答,並且可以在回答時引用對應的 chunk 來源。
整個流程聽起來像魔法,但拆開看每一步都是工程組裝。也因為每一步都可以調整(chunk size、embedding 模型、檢索 K 值、是否加 rerank、prompt 模板⋯⋯),實務上一套 RAG 從能用到好用之間有很大的調校空間。
什麼時候適合用 RAG
RAG 雖然強大,但不是每個場景都該套上去。以下幾種情境,RAG 通常會是合適的選擇:
- 知識會持續更新:政策、產品文件、新聞、研究論文這類今天加一份明天改一份的內容,用 RAG 直接更新資料庫就好,不必動模型。
- 需要明確引用來源:法律、醫療、學術、合規場景下,回答必須交代「我從哪份文件得到這個結論」,這是純 LLM 做不到、RAG 天生擅長的。
- 資料是私有或敏感的:內部技術文件、客戶資料、合約等等不適合送上雲端訓練,但可以放在自家伺服器的向量資料庫,只在查詢當下把相關段落送進 LLM。
- 知識量大到塞不進 context:即使 LLM 支援百萬 token 的 context window,把幾 GB 的文件每次都整批送進去也不切實際(費用、延遲都會爆掉)。先用 RAG 篩出相關段落是務實做法。
- 需要長尾知識:某個小眾框架的 changelog、某家公司的內部術語、某個地區的特殊法規,模型在訓練時可能根本沒看過,但我們手上剛好有資料。
什麼時候不適合用 RAG
反過來,有些情境硬上 RAG 反而是錯的選擇,這也是很多人在企業導入 AI 時容易踩到的坑。實務經驗中,比較典型的「不適合」情境如下:
- 需要跨文件推理或彙總:例如「比較這 50 份合約,整理出共通的違約條款」,RAG 一次只能撈幾段文字進來,看不到全貌,這時候直接把整批文件丟進大 context window 反而比較合適。
- 問題涉及結構化計算:「上季營收比前年同期成長多少」這種問題 RAG 撈到的是文字片段,但答案需要精確的 SQL 或試算表計算,正確做法是讓 LLM 寫查詢 / 程式去跑,不是檢索文字。
- 知識其實已經在模型裡:「Python list 跟 tuple 差別」這種公開的、訓練資料裡早就有的知識,直接問 LLM 就好,多套一層 RAG 只是增加延遲與失誤風險。
- 需要學會新行為而不是新知識:要 LLM 用某種特殊風格寫作、套用品牌語氣、輸出固定 JSON 格式,這些是「行為調整」,比較適合用 prompt engineering 或 fine-tuning,RAG 幫不上忙。
- 資料量很小:總共只有十幾頁 PDF、幾萬字筆記的情境,與其建一整套向量資料庫,不如直接把全部內容貼進 system prompt 或 context,省下基礎建設的力氣。
- 對即時性要求極高:交易撮合、毫秒級回應的場景,RAG 多一層檢索就多一層延遲,這種地方應該用更輕量的傳統檢索甚至硬寫規則。
很多團隊一聽到 LLM 配上自家資料就直覺想到 RAG,但其實「不用 RAG 也是合理選擇」這件事值得反覆提醒。先想清楚問題本質是「缺知識」「缺推理」還是「缺行為」,再決定要不要動用 RAG,會少走很多冤枉路。
常見 RAG 軟體
RAG 生態系大致可以分成三層:應用框架(負責把流程串起來)、向量資料庫(負責儲存與搜尋)、整合平台(負責 UI 與一站式體驗)。實務上不一定每一層都自己選,很多整合平台已經把上面幾層全部包好。
應用框架
適合工程師自己拼裝 RAG pipeline 的程式庫:
- LangChain:最廣為人知的 LLM 應用框架,提供 RAG 各環節的元件與整合,社群最活躍但 API 變動快。
- LlamaIndex:專注在資料連接與檢索的框架,設計上比 LangChain 更聚焦在 RAG 場景,文件處理工具豐富。
- Haystack:來自 deepset 的 Python 框架,適合企業導入,較成熟穩定,pipeline 概念清楚。
向量資料庫
RAG 系統的核心儲存層,選擇上要看資料量、是否需要自架、與現有技術棧的整合難度:
| 軟體 | 類型 | 特色 |
|---|---|---|
| Pinecone | 雲端服務 | 免運維、企業選擇多,需要付費 |
| Qdrant | 開源 | Rust 寫的高效能向量資料庫,支援自架與雲端 |
| Weaviate | 開源 | 內建多種 Embedding 模組,圖形化操作友善 |
| Chroma | 開源 | 輕量、適合本地 / 開發用,Python 整合最簡單 |
| Milvus | 開源 | 大規模分散式向量資料庫,億級資料表現好 |
| pgvector | PostgreSQL 擴充 | 把向量功能加進現有 PostgreSQL,免另外維運 |
| Elasticsearch | 搜尋引擎 | 從關鍵字搜尋出身,近年也加入了向量檢索能力 |
整合平台
如果不想自己寫程式,這幾套開箱即用的平台已經把 RAG 的細節包起來,匯入文件、選模型、設聊天介面,幾分鐘就能跑:
- AnythingLLM:桌面版可直接安裝,支援接 Ollama、OpenAI、Claude 等多種後端,把資料夾匯入就能問答,對個人用戶很友善。
- Dify:開源 LLMOps 平台,網頁介面、工作流、知識庫一應俱全,企業 PoC 常用。
- Flowise:拖拉式的 LLM / RAG 流程編輯器,類似 n8n 的視覺化操作,適合不寫程式的人。
- RAGFlow:專注在 RAG 的開源產品,特別強調文件解析能力(表格、PDF 排版),適合餵大量公司文件。
- Open WebUI:本來是 Ollama 的網頁介面,後來內建 RAG 功能,搭配 Ollama 跑本地模型很方便。
小結
RAG 把 LLM 從「考試只能用腦袋」變成「考試可以翻書」,這是它真正的價值所在。實作上不算複雜:切塊、embedding、向量資料庫、相似度搜尋、拼進 prompt,整套流程拆開來每一步都有現成工具可選。但是要做得好需要不少調校經驗,chunk 大小、embedding 模型挑選、檢索 K 值、是否加 rerank、prompt 模板⋯⋯每一個旋鈕都可能影響最終回答品質。
因此實務上的建議是:先想清楚問題是不是真的「缺知識」這個層次的問題,再決定 RAG 是不是答案。如果是,可以先用 AnythingLLM 或 Dify 之類的整合平台快速做出原型驗證價值,再決定要不要花力氣自己拼 LangChain、LlamaIndex 加上自架向量資料庫做完整的工程版本。從免費開始試最划算。
如果想在本地端跑一套完全離線的 RAG 環境,可以搭配 Ollama 入門教學|本地大語言模型新手指南 介紹的 Ollama 提供 LLM 與 Embedding 模型,再選一套整合平台串起來,連網路都不用,資料也不會外流。