
網站開久了,總會遇到流量很奇怪的時刻。可能是登入頁突然每秒被嘗試上百次帳密、可能是 API 被某個爬蟲不講武德地全速掃、也可能只是某位使用者的程式寫錯陷入無限重試迴圈,把伺服器的連線數整個吃光。這時候如果只靠應用層去擋,常常已經來不及,因為連請求都還沒進到應用程式,CPU 就先燒起來了。Nginx 內建的 limit_req 模組就是為了這種情境而生,幾行設定就能在最前線把異常流量擋掉,讓真正的使用者還能正常用。
不過 limit_req 的設定看起來短,背後的概念其實不算直觀,burst、nodelay、delay 這幾個參數搭配起來會產生很不一樣的行為,網路上找到的範本常常複製貼上就用,結果不是擋得太嚴讓正常使用者收 503,就是擋得太鬆等於沒設。這篇文章會從 Leaky Bucket 演算法的原理開始講起,把每個參數背後在做什麼事情拆開來看,搭配圖解比較三種常見模式的差異,最後再回到實戰設定。
為什麼需要 Rate Limit
Rate Limit 中文翻作「速率限制」或「限流」,目的是限制某個來源在單位時間內能發出多少個請求。乍看之下這跟防火牆有點像,但兩者切入的角度不太一樣:防火牆通常是「黑白名單式」的判斷,符合條件就放、不符合就擋;Rate Limit 則是「配額式」的判斷,前面幾個請求都放行,超過配額才擋。對於沒有惡意但寫錯程式的使用者來說,Rate Limit 比直接封 IP 友善很多,過一段時間自己就會恢復。
常見會加上 Rate Limit 的場景大概有幾種:
- 登入、註冊、忘記密碼等敏感頁面:避免暴力破解或大量註冊假帳號
- 對外的 API 端點:避免單一使用者把整個服務的容量佔走
- 成本較高的搜尋、檔案下載、報表產生:避免被有心人不斷觸發拉垮系統
- 網站的整體入口:作為最外層的保護,避免突發流量直接打到後端
題外話,Rate Limit 不是萬能的,遇到分散式爬蟲(每個 IP 只發幾個請求,但 IP 有上萬個)就會失靈,那種情境通常還要搭配 WAF、Cloudflare 之類的服務一起處理。但對於 90% 的日常異常流量來說,光是 Nginx 一層 Rate Limit 就能擋掉大部分問題。
Leaky Bucket 漏桶演算法
Nginx 的 limit_req 採用的是經典的 Leaky Bucket(漏桶) 演算法。可以把它想像成廚房裡的洗碗槽:水龍頭隨時可能有人開(請求進來),但下方的排水孔流速是固定的(伺服器處理速度)。如果水流入的速度小於排出速度,水位永遠是空的,一切正常;如果突然湧入大量的水,水位會慢慢升高,但只要還沒滿就 OK;一旦水位滿到溢出洗碗槽,多出來的水就只能流到地上(請求被拒絕)。
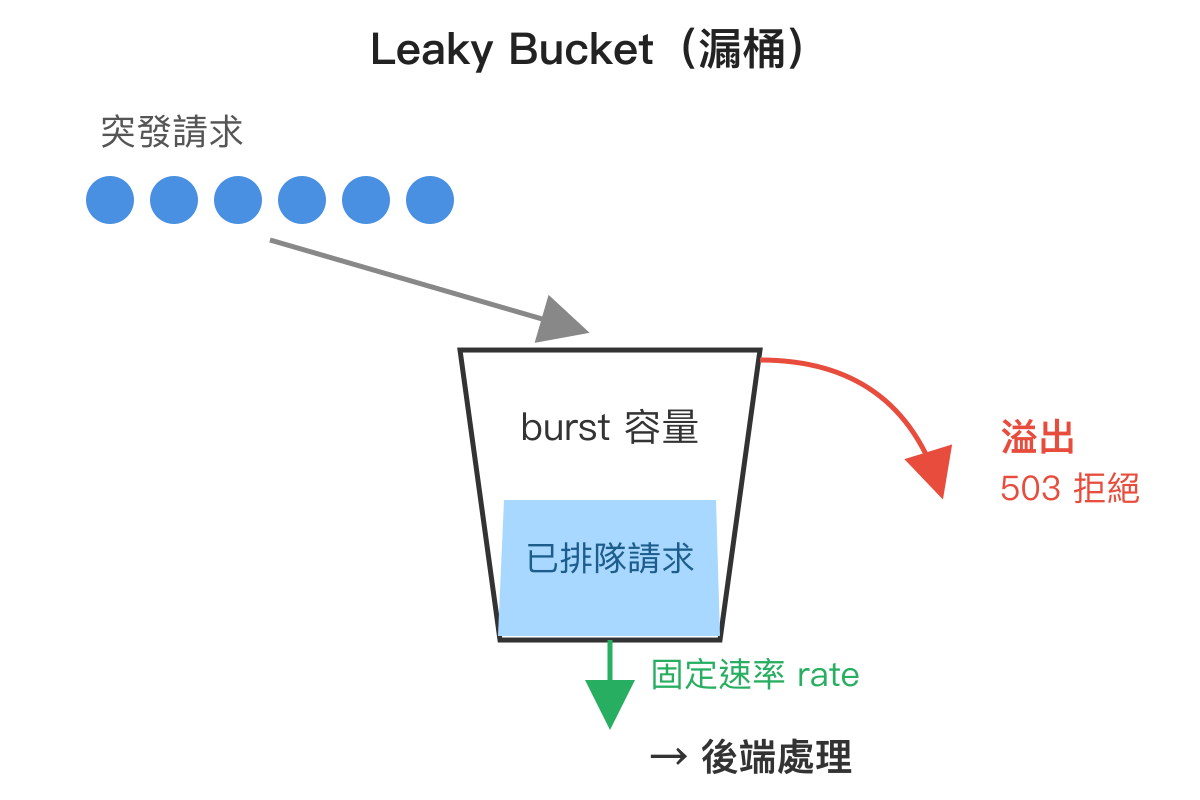
對應到 Nginx 的設定,桶子的「排出速度」就是 rate,桶子的「容量」就是 burst,超過 burst 容量就會溢出,Nginx 會回傳一個錯誤狀態碼。原生 Nginx 從 1.3.15 引入 limit_req_status 指令以來,預設值一直都是 503(Service Unavailable),可以透過 limit_req_status 429; 改成 429(Too Many Requests)。語意上 429 比 503 更精確、也比較不會跟伺服器真的掛掉時的 503 混淆,現代服務通常會明確改成 429。如果實測發現預設就是 429,多半是設定檔某處已經被改過、或前面有 Cloudflare 之類的代理在轉換狀態碼,可以用 nginx -T | grep limit_req_status 確認。這個演算法的好處是行為非常可預測:不管短時間內湧入多少請求,後端拿到的速度永遠不會超過 rate,這樣後端就不會被打爆。
limit_req_zone 與 limit_req
Nginx 的 Rate Limit 由兩個指令組成,limit_req_zone 負責「定義一個漏桶長什麼樣子」、limit_req 負責「在某個位置套用這個漏桶」。這樣設計的好處是同一個 zone 可以在多個 location 共用,也可以在不同地方套用不同的 zone。
# 定義 zone(放在 http {} 區塊內)
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=10r/s;
server {
location /api/ {
# 套用 zone(放在 server 或 location 內)
limit_req zone=mylimit burst=20 nodelay;
proxy_pass http://backend;
}
}看起來短短幾行,但每個欄位都有講究。下面把 limit_req_zone 的三個欄位、以及 limit_req 的三個欄位逐一拆開來看。
key:用什麼識別請求來源
limit_req_zone 的第一個參數是 key,也就是「以什麼為單位來算配額」。最常見的選擇是 $binary_remote_addr,也就是用客戶端 IP。為什麼是 $binary_remote_addr 而不是 $remote_addr?因為前者是二進位格式只佔 4(IPv4)或 16(IPv6)bytes,後者是字串格式 IPv4 就要 7~15 bytes,差異會反映在共享記憶體用量上,當追蹤的 IP 多到一定數量會差很大。
除了 IP 之外,key 也可以是其他變數,常見的選擇包含:
$binary_remote_addr:以客戶端 IP 為單位(最常用)$server_name:以網域為單位,整個網域共用一個配額$http_x_api_key:以 API key 為單位(搭配 header 認證的服務)$cookie_session_id:以登入 session 為單位- 留空字串
"":不分來源,整體共用一個配額(適合保護耗資源端點)
注意:如果 Nginx 前面還有反向代理或 CDN(例如 Cloudflare、AWS ALB),$binary_remote_addr 看到的會是代理伺服器的 IP,所有流量會被算成同一個來源。這時候要改用 $http_x_forwarded_for 或 $realip_remote_addr,並且記得搭配 real_ip 模組正確設定可信代理,不然這個欄位會被偽造。
zone:共享記憶體區域
zone=mylimit:10m 這段定義了一塊「共享記憶體區域」,名字叫 mylimit、大小 10MB。這塊記憶體是給 Nginx 的多個 worker process 共同存取用的,裡面記錄每個 key 目前的桶子水位、上次更新時間等資訊。
10MB 大概可以追蹤多少個 key?官方文件說 1MB 大約可存 16,000 個 IPv4 狀態,所以 10MB 大約 16 萬個。對中小型網站綽綽有餘,大型網站可以視情況開到 32m 或 64m。如果空間不夠用,Nginx 會回傳 503 並在 error log 留下訊息,這時候要把 zone 加大。
rate:平均速率
rate=10r/s 代表每個 key 每秒最多 10 個請求。Nginx 也支援 r/m(每分鐘)作為單位,例如 rate=30r/m。但要注意 Nginx 內部其實是換算成「每個請求之間的最小間隔」來執行的,10r/s 等於 100ms 一個、30r/m 等於 2 秒一個。所以 30r/m 不是「一分鐘內可以爆衝 30 個然後等 60 秒」,而是「每 2 秒只能放 1 個」。如果想做出「一分鐘內可以爆衝」的行為,要靠下面要講的 burst。
burst:允許短時間爆衝
burst 是漏桶的「容量」,也就是允許多少個請求暫時排在桶子裡等處理。如果不設 burst,等於桶子容量為 0,超過 rate 速度的請求會立刻被拒絕。但實務上很少有流量是「精準均勻分布」的,使用者點一下頁面可能瞬間就觸發 5 ~ 10 個請求(HTML、CSS、JS、圖片、API),這些都會被算進配額裡。如果 burst 設 0,正常使用者很容易誤傷。
所以實務上 burst 通常會設一個合理的緩衝,例如 rate 的 2 ~ 5 倍。burst 越大越能容忍尖峰,但也代表攻擊者可以在桶子被填滿前發出更多請求。
nodelay:burst 內的請求不延遲處理
單獨用 burst 而沒加 nodelay 的話,超出 rate 的請求會被「排隊」依照 rate 速度逐一處理。例如 rate=2r/s burst=4,瞬間湧入 5 個請求時,第 1 個會立刻處理,第 2 ~ 5 個會分別在 0.5s、1.0s、1.5s、2.0s 處理。從使用者角度看,後面幾個請求的回應時間會被人為延長。
加上 nodelay 之後,行為會變成:burst 桶子裡的請求「立刻全部處理」,但桶子的水位不會立刻歸零,而是依照 rate 速度慢慢補回。換句話說,使用者在瞬間爆衝後不會被延遲,但接下來幾秒內如果再發新請求,會因為桶子還沒補回而被拒絕。這個模式對使用者體驗最友善,是大多數 Web 應用的首選。
三種模式講起來抽象,直接看圖比較好理解:
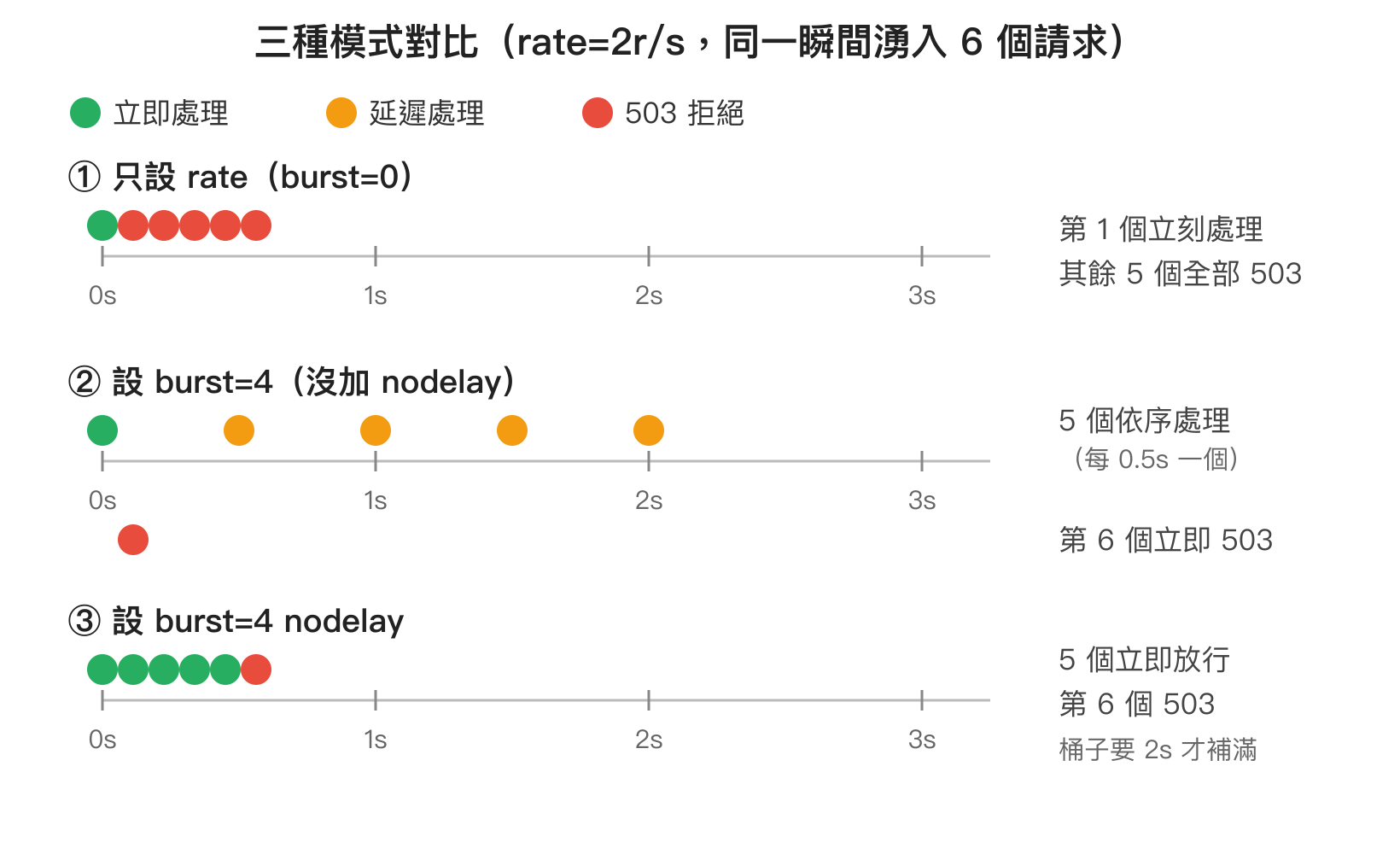
從圖中可以看出,模式 ② 和 ③「會處理多少個請求」是一樣的(都是 5 個成功、1 個 503),差別在於「何時處理」。模式 ② 把流量平滑掉,後端負載最穩定,但使用者會感受到延遲;模式 ③ 後端短時間內會吃到 5 個請求的瞬時負載,但使用者體驗最好。實務上,如果後端可以承受短時間的尖峰,nodelay 幾乎是必加的選項。
delay:burst 的折衷模式
Nginx 1.15.7 之後新增了 delay 參數,可以做到「前 N 個立即處理、超過 N 個後面排隊」的混合模式。例如 burst=10 delay=5,前 5 個請求立刻處理(等同 nodelay),第 6 ~ 10 個排隊延遲處理,第 11 個之後才回 503。這個模式適合「想保留一些彈性給使用者爆衝、但又不想讓全部 burst 都同時打到後端」的場景。
實戰設定範例
基本:保護登入頁
登入頁是最常被暴力嘗試的目標,配額可以設得很嚴格,因為正常使用者不會在短時間內登入幾十次。下面這份設定每個 IP 每秒最多 1 次登入嘗試,允許瞬間爆衝 5 次(例如使用者快速重試):
http {
# 定義一個叫 login 的 zone,每秒 1 個請求
limit_req_zone $binary_remote_addr zone=login:10m rate=1r/s;
# 改用 429(Too Many Requests)回應,比 503 更語意正確
limit_req_status 429;
server {
location = /login {
limit_req zone=login burst=5 nodelay;
proxy_pass http://backend;
}
}
}分層:API 一般端點 vs 重端點
大型 API 服務常常會把端點分等級,一般查詢可以給寬鬆的配額,搜尋、報表這種耗資源的端點配額要嚴格。透過定義多個 zone 並在不同 location 套用,就可以做到分層管理:
http {
# 一般 API:每秒 20 個
limit_req_zone $binary_remote_addr zone=api_general:10m rate=20r/s;
# 重端點:每秒 2 個
limit_req_zone $binary_remote_addr zone=api_heavy:10m rate=2r/s;
server {
# 預設套用一般限制
location /api/ {
limit_req zone=api_general burst=40 nodelay;
proxy_pass http://backend;
}
# 搜尋端點額外套用重限制(兩個 limit_req 會同時生效)
location /api/search {
limit_req zone=api_general burst=40 nodelay;
limit_req zone=api_heavy burst=5 nodelay;
proxy_pass http://backend;
}
}
}同一個 location 內可以寫多個 limit_req,每一個都是獨立的桶子,全部都要通過才會放行。這樣搜尋端點同時受「整體 API 配額」和「搜尋專屬配額」雙重約束。
搭配 Cloudflare 橘雲反向代理
網站如果有開 Cloudflare 的橘雲(Proxy 模式),所有流量都會先經過 Cloudflare 的邊緣節點再轉到我們的源站,這時候 Nginx 看到的 $remote_addr 全部都會變成 Cloudflare 節點的 IP(像是 173.245.x.x、104.16.x.x 之類的)。直接拿 $binary_remote_addr 當 Rate Limit 的 key 會出大事,因為全世界的使用者都被算成同一個來源,幾秒內就會被擋光。整個流程大概是這樣:
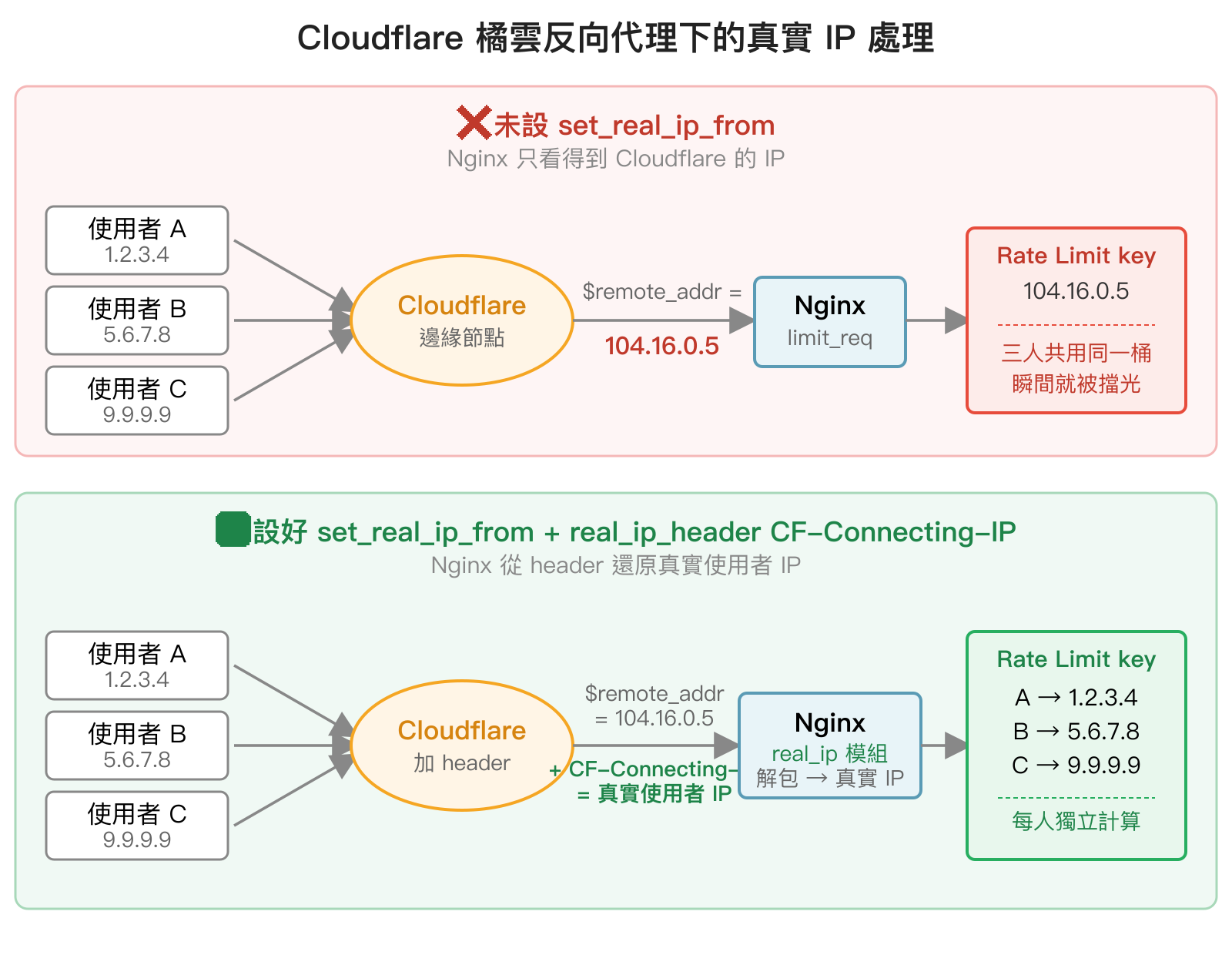
Cloudflare 會把真實使用者的 IP 放在三個 header 之一:
CF-Connecting-IP:Cloudflare 自己加的 header,只放單一 IP,所有方案都有,最推薦使用X-Forwarded-For:標準 header,但可能含多個 IP,且 client 端可以自行帶這個 header(要靠real_ip_recursive on往前找最接近源站的可信 IP)True-Client-IP:Cloudflare Enterprise 方案才有,行為跟CF-Connecting-IP一樣
正確做法是搭配 Nginx 內建的 ngx_http_realip_module(一般 distro 的 nginx 都有編入),告訴 Nginx「來自這些網段的請求,請從指定 header 讀取真實 IP 並覆寫 $remote_addr」。完整設定如下:
http {
# === Cloudflare IPv4 網段 ===
set_real_ip_from 173.245.48.0/20;
set_real_ip_from 103.21.244.0/22;
set_real_ip_from 103.22.200.0/22;
set_real_ip_from 103.31.4.0/22;
set_real_ip_from 141.101.64.0/18;
set_real_ip_from 108.162.192.0/18;
set_real_ip_from 190.93.240.0/20;
set_real_ip_from 188.114.96.0/20;
set_real_ip_from 197.234.240.0/22;
set_real_ip_from 198.41.128.0/17;
set_real_ip_from 162.158.0.0/15;
set_real_ip_from 104.16.0.0/13;
set_real_ip_from 104.24.0.0/14;
set_real_ip_from 172.64.0.0/13;
set_real_ip_from 131.0.72.0/22;
# === Cloudflare IPv6 網段 ===
set_real_ip_from 2400:cb00::/32;
set_real_ip_from 2606:4700::/32;
set_real_ip_from 2803:f800::/32;
set_real_ip_from 2405:b500::/32;
set_real_ip_from 2405:8100::/32;
set_real_ip_from 2a06:98c0::/29;
set_real_ip_from 2c0f:f248::/32;
# 從 CF-Connecting-IP 取得真實 IP
real_ip_header CF-Connecting-IP;
# 這之後 $binary_remote_addr 才會是真實使用者的 IP
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=10r/s;
}重點:一定要明確列出信任的網段,不能偷懶寫成 0.0.0.0/0(信任所有來源)。否則隨便一個攻擊者直接連源站 IP(繞過 Cloudflare)並偽造 CF-Connecting-IP header,就能假裝成任何 IP 繞過 Rate Limit。如果擔心源站 IP 外洩,建議在防火牆層級也只允許 Cloudflare IP 連進 80/443 port,雙保險。
自動同步 Cloudflare IP 列表
上面那串 IP 列表抄起來很長,而且 Cloudflare 偶爾會新增網段,硬寫在設定檔裡會慢慢過時。建議寫個小腳本從 Cloudflare 官方 API 自動產生設定,搭配 cron 每週跑一次:
#!/bin/bash
# /etc/nginx/update-cloudflare-ips.sh
set -e
OUT=/etc/nginx/conf.d/cloudflare-realip.conf
TMP=$(mktemp)
{
echo "# Auto-generated from Cloudflare IP list"
echo "# Updated at $(date -Iseconds)"
curl -fsS https://www.cloudflare.com/ips-v4 | sed 's|^|set_real_ip_from |;s|$|;|'
curl -fsS https://www.cloudflare.com/ips-v6 | sed 's|^|set_real_ip_from |;s|$|;|'
echo "real_ip_header CF-Connecting-IP;"
} > "$TMP"
# 測試新設定,OK 才覆蓋與 reload
mv "$TMP" "$OUT"
nginx -t && nginx -s reload產生的設定檔會被自動載入到 http {} 區塊(透過 include /etc/nginx/conf.d/*.conf),這樣 limit_req_zone 寫的 $binary_remote_addr 就會是真實 IP。記得在 crontab 加上:
# 每週日凌晨 3 點同步一次
0 3 * * 0 /etc/nginx/update-cloudflare-ips.sh >> /var/log/cf-ip-update.log 2>&1驗證真實 IP 有沒有生效
設定完之後最容易被忽略的一步是「實際驗證」。最直接的方式是把 access log 改成同時記錄 $remote_addr(覆寫後)與 $http_cf_connecting_ip(原始 header),看看兩者是否一致:
log_format cfdebug '$remote_addr | cf=$http_cf_connecting_ip | xff=$http_x_forwarded_for '
'"$request" $status';
server {
access_log /var/log/nginx/access.log cfdebug;
# ...
}從不同網路(手機 4G、家裡網路、VPN)開幾次網站,再去看 log。如果 $remote_addr 跟 cf= 一樣、且就是自己當下的 IP,代表設定正確;如果 $remote_addr 還是 Cloudflare 的 IP(104.16.x.x、172.64.x.x 之類),表示網段沒涵蓋到或 header 名字寫錯。確認沒問題後再把 log_format 改回正常版本即可。
Cloudflare 自家 Rate Limiting 與 Nginx 怎麼分工
Cloudflare 自己也有 Rate Limiting 服務(Free 方案有限制版、付費方案有完整版),那既然有了 CF 的限流,還需要 Nginx 這層嗎?實務上建議兩層都做,分工大致是這樣:
- Cloudflare 那層:擋大規模 DDoS、機器人、整個網域的整體配額。優點是流量根本進不到我們的源站,省頻寬與運算
- Nginx 這層:擋細部的端點配額(登入、特定 API、重端點),以及做為 Cloudflare 失效時的最後防線
另外要注意,Cloudflare 預設會幫源站做 connection coalescing,也就是同一個 Cloudflare 節點到源站只會開少量的 keep-alive 連線、所有使用者的請求都會走這幾條連線出去。所以如果有用 limit_conn 限制連線數,這個值要設得寬鬆很多,不然會擋到 CF 自己。
監控與除錯
設定上線之後不能就放著不管,要持續觀察 Nginx 的 error log,看看擋掉的請求是不是真的異常流量、有沒有誤殺正常使用者。被 limit_req 擋下的請求會在 error log 留下類似這樣的訊息:
2026/04/20 10:23:45 [error] 1234#0: *5678 limiting requests, excess: 5.123 by zone "mylimit", client: 192.0.2.1, server: example.com, request: "GET /api/users HTTP/1.1"如果嫌 error 等級太吵,可以用 limit_req_log_level 改成 warn 或 notice。另外建議搭配監控系統(Prometheus + Grafana、Datadog、雲端 LB log 等)統計 4xx 和 5xx 的比例,limit_req_status 設成 429 之後,可以單獨抓 429 的次數來觀察 Rate Limit 的觸發頻率。
除錯時還有一個常見的坑:測試 Rate Limit 的時候用 curl 從本機連,會發現一直擋不下來,那是因為本機 IP 是 127.0.0.1 沒被當成「真實」流量,或者測試時請求數量根本沒達到設定門檻。建議用 ab(Apache Bench)或 wrk 工具壓測:
# 同時 10 個連線,總共發 100 個請求,看 503/429 的比例
ab -n 100 -c 10 https://example.com/api/users常見錯誤與注意事項
最後整理幾個實務上很常踩到的坑:
- 把 rate 設成「能接受的最大值」:rate 是「平均速度」不是「上限」,搭配 burst 才有上限。如果想限制「每秒最多 100 個」,應該設
rate=100r/s burst=0,而不是rate=100r/s burst=200 nodelay(後者瞬間可以放 201 個) - NAT 環境誤殺:同個公司或學校的使用者可能共用對外 IP,用 IP 當 key 會把整群人算成同一個來源。如果使用者多,可能要改用其他識別(session、API key)或放寬 rate
- 忘記排除靜態資源:Rate Limit 套在整個網站根目錄上時,圖片、CSS、JS 也會被算進配額,正常瀏覽就可能被擋。建議在
location區分靜態與動態資源,或只對 API、登入等敏感路徑套用 - WebSocket 與長連線:
limit_req只算「請求數」,WebSocket 升級之後就不再是 HTTP 請求,這條規則對 WebSocket 訊息無效,要保護的話得用limit_conn限制連線數 - reload 不會清空計數:
nginx -s reload是熱重載,共享記憶體區域的內容會保留,所以調整 rate 後新規則會立刻生效但既有桶子的水位不變。如果要徹底重置,得restart
Rate Limit 是個「設定簡單、調校困難」的功能,第一版上線後通常需要根據實際流量觀察一段時間再微調。建議先從寬鬆的設定開始(例如 nodelay 加大 burst),確認沒誤殺再逐步收緊。Nginx 也有 limit_req_dry_run 模式可以「只記錄不擋」,方便先觀察哪些請求會被擋下來、再決定要不要正式啟用。