
Anthropic 在 2026 年 4 月 16 日正式推出 Claude Opus 4.7,距離上一代 Opus 4.6 才過了不到三個月。這次的版號跳了一小階,但實際拉開的差距並不小——官方公布的 CursorBench 從 4.6 的 58% 直接跳到 70%、Rakuten-SWE-Bench 的解題量是 4.6 的 3 倍、視覺辨識準確率從 54.5% 一路衝到 98.5%。價格則是維持跟 4.6 相同,1M context 一樣不再額外加價。
這篇文章會從版本差異、Benchmark 表現、新功能、Breaking changes、價格與上下文限制這些大家最關心的角度,把 Opus 4.7 整體梳理一遍。最後也會聊一下 Anthropic 這次罕見地直接承認「Opus 4.7 比同門的 Mythos Preview 弱」的這件事——為什麼會這樣,以及對開發者來說意味著什麼。
Claude Opus 4.7 是什麼
Claude Opus 是 Anthropic 三條產品線(Haiku、Sonnet、Opus)裡最高階的一條,定位是處理最複雜的推理、長任務工作流、agent 自主操作這些情境,相對地推理成本與延遲也最高。Sonnet 適合大多數日常任務、Haiku 給對成本與延遲敏感的場景,Opus 則是不計成本要拿到最強表現時才會選用。
Opus 4.7 主要打的方向是軟體工程與 agent 能力。Anthropic 官方公告把它定位為「在程式撰寫、agent 操作、長任務維持」這三件事上比 Opus 4.6 顯著進步。除了純語言能力外,視覺理解、影像處理也大幅升級,Claude Code 的使用者特別會有感。
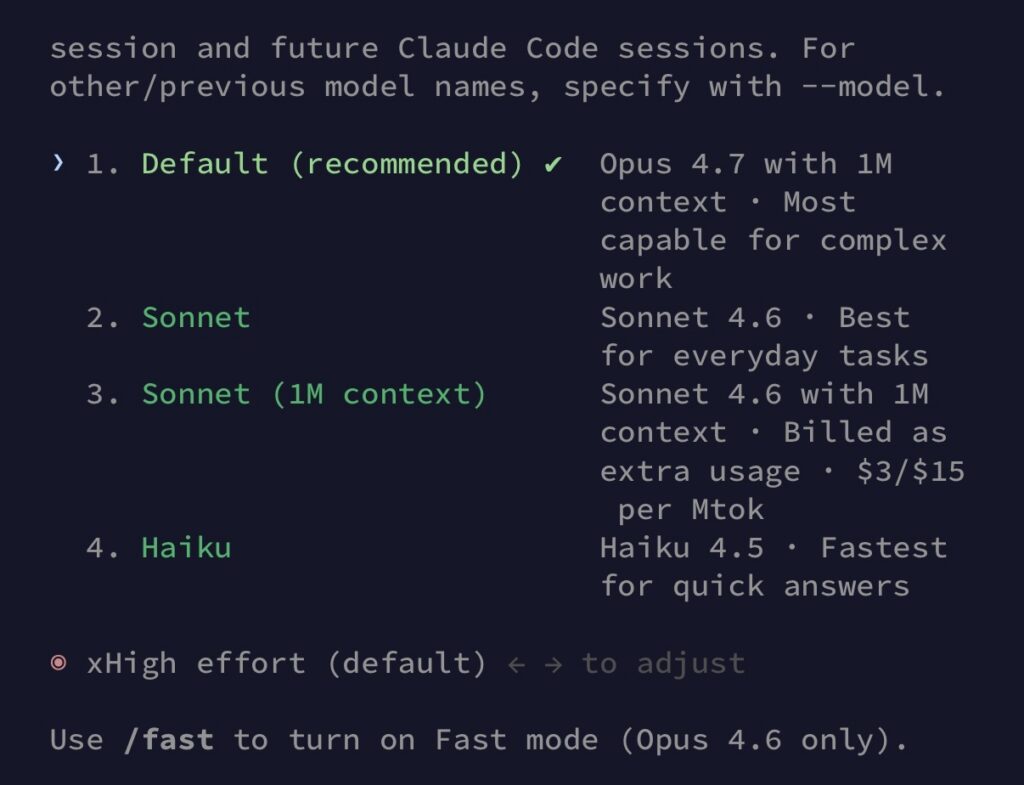
模型 ID 是 claude-opus-4-7,已上架 Anthropic API、Amazon Bedrock、Google Vertex AI 與 Microsoft Foundry,Claude 的 Pro、Max、Team、Enterprise 訂閱方案也同步可用。Anthropic 公告中也提到,從 2026 年 4 月 23 日開始,Enterprise pay-as-you-go 與 API 的預設模型會從 4.6 切到 4.7,沒有指定模型版本的請求就會自動跑在新模型上。
與 Opus 4.6 的差異一覽
先用一張表把開發者最常關心的幾個項目對齊:
| 項目 | Opus 4.6 | Opus 4.7 |
|---|---|---|
| 模型 ID | claude-opus-4-6 | claude-opus-4-7 |
| Input 價格 | $5 / 1M tokens | $5 / 1M tokens |
| Output 價格 | $25 / 1M tokens | $25 / 1M tokens |
| Context window | 1M tokens | 1M tokens |
| 長 context 加價 | 無(2026-03 官方取消) | 無,900K 與 9K 同每 token 費率 |
| Max output | 64K tokens | 128K tokens |
| Effort levels | low / medium / high / max | 新增 xhigh,介於 high 與 max 之間 |
| Task budgets | 無 | 新增 beta,模型可自行配額 |
| Extended thinking budget | 可手動指定 | 移除,只剩 adaptive thinking |
| 影像最大解析度 | 1568px / 1.15MP | 2576px / 3.75MP |
| Tokenizer | 原版 | 新版,同內容最多多 35% token |
| Prompt caching | 支援,省 90% | 支援,省 90% |
| Batch processing | 支援,省 50% | 支援,省 50% |
注意:表格上 Opus 4.7 跟 Opus 4.6 的單價(input/output 每 1M token)完全一樣,但這不代表「同樣的工作換到 4.7 上花的錢一樣」。Opus 4.7 換了新的 tokenizer,同樣一段文字最多會多吃 35% 的 token,所以實際帳單可能會略高,等於是「單價沒漲、但 token 數漲了」。詳細的原因放在後面的「新版 tokenizer」一節說明。
除了 tokenizer 之外,幾個比較需要展開講的點,下面分別細看。
程式與 Agent 能力升級
這代 Opus 4.7 最被強調的就是程式能力。Anthropic 在公告與第三方夥伴公布的數字如下:
| Benchmark | Opus 4.6 | Opus 4.7 | 變化 |
|---|---|---|---|
| CursorBench | 58% | 70% | +12 個百分點 |
| Rakuten SWE-Bench(解題量) | 1x | 3x | 3 倍 |
| 內部 93-task coding benchmark | — | — | +13% |
| Visual-acuity benchmark | 54.5% | 98.5% | +44 個百分點 |
| Terminal-Bench | 部分失敗 | 原本失敗的也能解 | — |
Rakuten 公布的 SWE-Bench 數字最有意思:解題量是 4.6 的 3 倍,而且 code quality 與 test quality 兩個面向都拿到雙位數百分比的提升。對長時間 coding agent 工作流來說,這代表能解的範圍變廣,產出的程式品質也更穩定。
視覺辨識的部分大概是這次最戲劇化的數字——從 54.5% 直接跳到 98.5%。Anthropic 同步把單張圖片可接受的解析度從 1568px / 1.15MP 提高到 2576px / 3.75MP,而且模型輸出的座標跟實際 pixel 1:1 對應。對於 GUI agent、瀏覽器操作、設計稿分析這類強烈依賴視覺的工作流,4.7 應該會是體感差距最明顯的地方。
注意:SWE-bench Verified 與 GPQA Diamond 的官方確切分數,Anthropic 這次沒有在 model card 上完整公開,目前流傳的數字多是第三方估計,這裡就不一一列出,避免誤導。
Opus 4.7 新功能
新的 xhigh effort level
原本 Anthropic 的 effort level 只有 low、medium、high、max 四檔,這次在 high 跟 max 之間多了一個 xhigh。實際的設計考量是 high 跟 max 中間的 token 成本差異太大,xhigh 給開發者一個「想要更深但又不想花到 max 那麼多」的中間選項。
Claude Code 使用 Opus 4.6 模型預設使用 Medium effort,但是 Opus 4.7 模型預設是 xHigh effort,因此會消耗更多 Token,可以依照需求調整。
Task budgets(beta)
Task budgets 是這代新加的 beta 功能,需要在 Messages API 加上 task-budgets-2026-03-13 header 才會啟用。它跟過去 max_tokens 設硬上限的概念不同——模型會被告知還剩多少 token 預算,自己決定要花在哪一段思考、哪一段輸出上,做到自我配額。
實際使用上,Task budgets 適合的是長時間 agent 任務,例如要在預算內完成多輪檢索、改 code、跑測試這種工作。而日常一次性 API 呼叫繼續用 max_tokens 就好,不需要為了新功能而上 beta header。
高解析度影像
影像處理上限從 1568px / 1.15MP 提高到 2576px / 3.75MP,等於可以直接丟入更大張、細節更多的圖。對於螢幕截圖、設計稿、PDF 掃描頁這類需要看清楚小字的場景,可以省掉自己先做切片或縮圖的工。
新版 tokenizer
Opus 4.7 換了新的 tokenizer,同樣一段文字在 4.7 上消耗的 token 數量最多會多 35%(官方說法是「1x 到 1.35x」,依內容而定)。這意味著兩件事:第一,token 為單位的成本估算可能要重做;第二,現有 prompt cache 在跨 4.6 與 4.7 的場景下,cache 是不會共用的。如果工作流原本嚴格依賴 token 計算(例如自定切片、配額分配),升級時記得測過一輪。
題外話,換 tokenizer 通常代表整個模型是重新訓練的——embedding 矩陣與詞彙表是綁死的,舊權重沒辦法直接套用。從這個角度看,4.6 到 4.7 雖然版號只跳 0.1,但本質上比較接近「同一個訓練世代下的新模型」,而不是 4.6 微調出來的小升級。SWE-bench Pro 從 53.4% 跳到 64.3%、視覺從 54.5% 衝到 98.5% 這種幅度,也呼應了這件事。
另外比較反常識的是,業界換新 tokenizer 通常會強調「壓縮率更好、同樣內容用更少 token」當賣點,但 Opus 4.7 反過來——同內容反而用更多 token。Anthropic 官方只說新 tokenizer「對模型在多種任務上的表現有貢獻」,沒講具體設計理由。可能的方向包括擴大多語言或程式碼相關詞彙、把容易混淆的合併 token 拆開、tokenizer 邊界優先對齊語義而不是壓縮等等,但這些都是推測。從結果看,Anthropic 的取捨是用「多 35% token 的成本」換到「Benchmark 大幅提升」,這個帳目前看起來是划算的。
升級時的 Breaking changes
4.7 不是純粹相容性升級,有幾個 API 行為改變要特別留意:
- Extended thinking budget 移除:過去 4.6 可以手動指定
thinking.budget_tokens,4.7 改為只剩 adaptive thinking(模型自己決定要不要思考、思考多深),而且預設關閉 - Sampling 參數限制:
temperature、top_p、top_k設成非預設值會直接回 400 錯誤。Anthropic 的設計是希望開發者不要再透過這些參數調 randomness,改用 effort level 與 prompt 來引導 - Thinking content 預設不回傳:要看到模型的思考內容必須改用
display: "summarized"主動 opt-in,不再像 4.6 預設就會夾在回應裡面 - 行為更字面化:Anthropic 表示 4.7 對 prompt 的指令會更嚴格按字面執行,回覆長度也會更貼合任務本身需要,預設的 tool call 與 subagent 觸發次數變少,整體語氣更直接、emoji 更少
實際升級到 4.7 之前,比較保險的做法是把 prompt 與 sampling 設定先 review 一輪。如果原本依賴 thinking content 做下游處理,記得改成主動 opt-in,否則程式會收到空欄位。
價格與上下文限制
Opus 4.7 的價格與 Opus 4.6 完全相同:input $5 / output $25 美元每 1M tokens。這在新模型發佈時並不常見——通常旗艦版號往上跳會伴隨漲價,但這次 Anthropic 維持原價直接升級,等於是大家現有的成本模型不需要重做。
另外值得提醒的是長 context 不會額外加價。Opus 4.6 剛上線時其實有所謂的 long-context premium——超過 200K token 的請求會被加價計費,但 Anthropic 在 2026 年 3 月 16 日已經把這個 premium 取消,4.6 跟 Sonnet 4.6 之後都改成全 context 統一費率。Opus 4.7 延續了這個定價:發 9K token 跟發 900K token 的請求,每 token 費率完全一樣。對於常需要塞整個 codebase、長 PDF 或大量歷史對話進去的場景,這條在實際成本上很有感。
省成本的工具仍然完整保留:
- Prompt caching:重複命中的部分省 90% 費用
- Batch processing:非即時的批次任務省 50%
- Max output 倍增:從 64K 提高到 128K,過去要分段呼叫的長輸出可以一次到位
注意:新版 tokenizer 同樣一段內容最多會多吃 35% token,等於切到 4.7 上實際付的錢可能略高。對成本敏感的工作流,建議在切換前用小量真實流量跑過一輪實測。
Claude Code 端的改動
Claude Code 也跟著做了同步更新。最明顯的新指令是 /ultrareview——專門開一個聚焦 code review 的 session,效果跟一般對話下「請幫我 review 這份 PR」差別在於 ultrareview 會走比較嚴謹的多階段流程,把問題分類、按優先順序整理,並且不會順手幫忙改 code(避免 review 變實作)。
除了新指令,4.7 在 Claude Code 裡的預設行為也有改變:tool call 跟 subagent 觸發比 4.6 保守一些、語氣比較直接、不太會在回應裡放 emoji。這跟前面提到的「指令更字面化」是一脈相承的設計選擇,整體上比較像在跟一個老練但話不多的工程師合作。
關於 Claude Code 本身的入門與常用功能,可以參考之前寫過的 Claude Code 入門使用教學,這邊就不再重複介紹。
Mythos Preview 是什麼
聊到 Opus 4.7,就一定要提一下 Claude Mythos Preview——一個比 4.7 更強、但 Anthropic 決定不對外公開上市的模型。
Mythos 最早是在 2026 年 3 月 26 日因為 Anthropic 自家 CMS 設定失誤,文章被搜尋引擎 index 才意外曝光,Fortune 第一個獨家報導出來。Anthropic 後來在 4 月 7 日正式公告 Mythos Preview 的存在,承認這是內部代號 Capybara 的一個新世代通用模型,並且在內部評測中能夠在多種主流作業系統與瀏覽器上自主發現並利用 zero-day 漏洞。
因為這個能力等級的模型如果直接公開上市,可能會被濫用於實際攻擊,Anthropic 選擇以代號 Project Glasswing 的計畫,把 Mythos Preview 限定提供給 12 家戰略合作夥伴做防禦性資安研究——名單裡有 Amazon、Apple、Microsoft、Cisco、CrowdStrike、Linux Foundation、Palo Alto Networks 等,目的是讓這些公司能用 Mythos 在攻擊者拿到同等級工具之前先盤點漏洞。一般開發者、Pro/Max 訂閱者目前都拿不到 Mythos。
Opus 4.7 與 Mythos Preview 的關係
網路上一個常聽到的說法是「Opus 4.7 是 Mythos Preview 的弱化版」。這個說法其實有官方根據——Anthropic 在 Opus 4.7 的公告裡直接寫:
Although it is less broadly capable than our most powerful model, Claude Mythos Preview, it shows better results than Opus 4.6 across a range of benchmarks.
Opus 4.7’s cyber capabilities are not as advanced as those of Mythos Preview—indeed, during its training we experimented with efforts to differentially reduce these capabilities.
翻成白話:Opus 4.7 整體能力比 Mythos Preview 弱,而且 Anthropic 在訓練 4.7 的階段,刻意做了「選擇性降低資安攻擊能力」的實驗。所以「弱化版」這個說法在「攻擊能力被刻意抑制」這一點上完全成立。
不過嚴格來說,Opus 4.7 並不是把 Mythos Preview 拿來剪一刀就推出。比較精確的描述是:兩者是同一個訓練世代下平行產出的兩個模型,Mythos 代表 Anthropic 目前能力的上限、Opus 4.7 是把資安相關能力刻意壓低之後的公開釋出版本。Mythos 留給 Project Glasswing 夥伴做防禦研究、Opus 4.7 給一般開發者用。
會這樣設計的考量也很實在:先把比較安全的 4.7 釋出到實際生產環境,觀察大規模部署下還會不會冒出沒料到的風險,把 safeguards 跟監控機制都磨利之後,未來才有可能讓 Mythos-class 的能力安全地對外開放。換個角度看,Opus 4.7 等於是 Mythos 級模型上市前的中間步驟,這也是為什麼 Anthropic 願意主動承認「我們有更強的版本,但不打算給」這件事。
怎麼開始用
升級到 4.7 的方式依使用情境分成幾種:
- Claude Pro / Max / Team / Enterprise 訂閱者:在 claude.ai 的模型選單直接選 Opus 4.7 即可,不需要額外設定
- Anthropic API:在 Messages API 的
model欄位指定claude-opus-4-7,舊版claude-opus-4-6仍可繼續使用,沒有強制下架 - Claude Code:升級到最新版本後,在 model 設定切到 Opus 4.7。Claude Code 也支援 1M context 模式,超過 200K 的 session 會自動啟用,不需要額外開關
- Bedrock / Vertex AI / Microsoft Foundry:對應的 model ID 從各平台的 console 取得,行為與直接走 Anthropic API 一致
另外從 2026 年 4 月 23 日開始,Enterprise pay-as-you-go 與 API 的預設模型會從 4.6 換成 4.7。如果線上環境有特別依賴 4.6 行為的工作流(例如 prompt 是針對 4.6 微調過的、依賴舊 thinking budget 機制),記得把 model 欄位明確指定為 claude-opus-4-6,避免被自動切換到新模型。
常見問答
整理幾個 Opus 4.7 發佈後比較常被問到的問題:
什麼情境適合升級到 4.7?
新模型發佈的時候,「該不該全面升級」其實值得想一下。以下是幾個比較適合切到 4.7 的情境:
- 長時間 coding agent 工作流(解題量 3 倍最直接受惠)
- 瀏覽器自動化、GUI agent、需要看清楚螢幕截圖的場景
- 需要長 context 又不想付溢價的場景(整個 codebase、長 PDF、大量歷史對話)
- Code review、複雜重構、需要細節推理的工程任務
什麼情境繼續用 4.6 或其他模型?
反過來,下面這些情境繼續用其他模型反而更合理:
- 純文字對話、客服、資訊摘要這類日常任務——Sonnet 足夠且便宜很多
- 對延遲敏感的即時對話與 chatbot——Haiku 速度與成本都更適合
- 已經在 4.6 上用 thinking budget、自訂 sampling 參數深度調整過的工作流——升上 4.7 等於要重新校過一輪,沒有立即必要可以再觀察一陣
- 對 token 成本估算非常嚴格的 SaaS 計費模型——新 tokenizer 換算過後,下游用量會微幅上升,計價邏輯要先重算
換句話說,Opus 4.7 的升級價值很集中在「複雜程式工作 + 長 context + 視覺」這幾個領域。如果現有需求落在 Sonnet、Haiku 能處理的範圍,硬要升上 Opus 4.7 並不划算。
Opus 4.7 會比 4.6 貴嗎?
表面上單價完全一樣(input $5、output $25 / 1M tokens),但同樣一段文字在 Opus 4.7 上最多會多 35% token。所以「同樣的工作」帳單通常會略高,因為 tokenizer(把文字轉換成 token 的分詞器)換新版了,不同的輸入內容可增加 0% 到 35% 的 token 花費。而且 Claude Code 上預設的 effort 從 medium 變成 xHigh,雖然會思考更多,但也更花費 token。
對成本敏感的工作流,建議切換前用小量真實流量做 A/B 對照,量化看看自己的內容類型實際是落在 1.0x 還是接近 1.35x,再決定升不升。
一般開發者能用到 Mythos Preview 嗎?
目前不行。Mythos Preview 只透過 Project Glasswing 提供給 Anthropic 挑選的 12 家戰略合作夥伴(Amazon、Apple、Microsoft、Cisco、CrowdStrike、Linux Foundation、Palo Alto Networks 等),用途是防禦性資安研究。Pro / Max / Team / Enterprise 訂閱者、API 使用者、Bedrock / Vertex AI 等第三方平台都拿不到 Mythos,沒有 waitlist 也沒有 beta 申請管道。
對一般使用者而言,Opus 4.7 已經是目前能拿到的最強公開版本。要等到 Mythos-class 模型對外開放,可能要看後續 safeguards 的成熟度。
升級時最容易踩到的雷是什麼?
API 端有四個變動最容易在升級當天就讓程式爆掉:
- 還在送
thinking.budget_tokens的請求會直接收到 400 錯誤——必須改用thinking: {type: "adaptive"} - 還在送非預設的
temperature、top_p、top_k一樣會收到 400——這些參數要全部從請求中拿掉 - 原本依賴 thinking content 做下游處理的程式會收到空字串,因為 4.7 預設不回傳 thinking——要改用
display: "summarized"主動 opt-in - 原本貼著
max_tokens上限跑的場景,可能會因為新 tokenizer 多吃 token 而被截斷——建議把max_tokens加一點 headroom,特別是 compaction 觸發點要重抓
Extended thinking budget 跟 effort level 差在哪?
兩者控制的東西完全不同層次。
Extended thinking budget(4.6 寫法 thinking.budget_tokens: N)是一個精確的硬性 token 上限,只控制「思考」階段最多花多少 token,設了就一定強制思考。
Effort level(output_config.effort)則是 low / medium / high / xhigh / max 五檔粗粒度旋鈕,影響的不只思考深度,還包含 tool call 頻率、subagent 觸發次數、回覆長度,整批一起調。簡單比喻是:budget 像手動油門、effort 像自動駕駛模式。
4.7 把 budget 砍掉的官方理由是「adaptive thinking 在內部評測上比 fixed budget 表現更穩定」,背後的設計哲學變化是把模型內部運作的控制權收回模型本身——同一波還拿掉了 temperature 等 sampling 參數,方向一致。對開發者來說,這等於失去精準的 token 預估能力,要改用 task_budget(軟性建議)來控制整個 loop 的 token 上限。
實務遷移大致是:
# 4.6 寫法
response = client.messages.create(
model="claude-opus-4-6",
thinking={"type": "enabled", "budget_tokens": 32000},
max_tokens=8000,
)
# 4.7 對應寫法
response = client.messages.create(
model="claude-opus-4-7",
thinking={"type": "adaptive"}, # 主動 opt-in
output_config={"effort": "high"}, # 用 effort 取代 budget
max_tokens=10000, # 新 tokenizer 留 headroom
)真正的踩雷點是:原本 4.6 用 {type: "enabled", budget_tokens: N} 強制思考的程式碼,搬到 4.7 上會直接收到 400 error——因為 4.7 不接受 enabled 模式了。要改成 {type: "adaptive"} 並用 effort 控制深度。對於 4.6 時代沒在用 thinking field 的程式(omit 等於 disabled),升到 4.7 行為一樣,沒有差異。
注意:這整個 breaking change 只影響直接打 Anthropic Messages API(或 Bedrock / Vertex / Foundry)的開發者。Claude Code、Claude Managed Agents、claude.ai 網頁/手機 App 的使用者不需要做任何事——這些 surface 都有 harness 自動幫忙處理 thinking 設定。Claude Code 從 2026-02 起就預設啟用 adaptive thinking + medium effort,4.7 上連 CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING 環境變數也失效了,永遠是 adaptive on。
xhigh 跟 max effort level 該怎麼選?
Anthropic 官方建議是:對程式與 agent 任務,從 xhigh 開始試;對需要高品質但成本可控的任務,high 起跳;要拚最強表現再用 max。xhigh 補的是 high 跟 max 之間的成本斷層——high 之後直接跳 max 對很多場景來說過頭了,xhigh 給了一個更細的選擇點。
實務上 max 是「不計成本要拿到最好結果」的等級,token 消耗會比 xhigh 明顯多,日常工作流不太需要常駐在 max。
4.7 會比較容易拒絕回答嗎?
在資安相關的話題上會。Anthropic 官方有提到 Opus 4.7 加了「real-time cybersecurity safeguards」,遇到涉及攻擊技術、漏洞利用這類的請求會比 4.6 更容易拒絕。如果是合法的安全研究、紅隊測試、CTF 練習這類正當使用情境,可以申請 Cyber Verification Program 取得對應權限。
非資安的一般任務則沒有這層額外的拒絕門檻,跟 4.6 體感差不多。題外話,4.7 整體語氣會比 4.6 更直接、更字面化,過去靠 prompt 「請不要過度解讀指令」這類包裝的情況,在 4.7 上反而要拿掉,否則模型會嚴格照字面跑。
小結
Claude Opus 4.7 這次的更新,重點不在於跳了一個全新的代數,而是在維持原價的前提下把程式、視覺、長 context 三個面向一次推上去,同時在 API 行為上做了一些值得提前準備的 breaking changes。對軟體工程相關的工作流來說,是一個值得實際試一試的版本;對日常一般任務的使用者,Sonnet 與 Haiku 仍然是更合理的選擇。
而 Mythos Preview 跟 Project Glasswing 的安排,則透露了 Anthropic 對「能力上限的模型如何釋出」的新做法——不再是「訓練好就上市」,而是「先把比較安全的版本送出去、用實際部署去驗證 safeguards」。這個節奏對使用者來說可能會慢一點才看到頂級模型,但長遠來看,能讓整體 AI 部署的風險被控制在更可預期的範圍內。
參考資料
- Anthropic – Introducing Claude Opus 4.7
- Anthropic – Claude Opus product page
- Anthropic – Models overview
- Anthropic – Pricing
- Anthropic Red – Claude Mythos Preview
- Axios – Anthropic releases Claude Opus 4.7, concedes it trails unreleased Mythos
- Fortune – Anthropic ‘Mythos’ AI model representing ‘step change’