
用 Claude Code 寫了一陣子,許多人都會被額度頁面嚇一跳——明明只跑了幾個任務,session 額度就掉了一大半。其實多數時候模型本身沒有特別聒噪,問題出在 prompt cache 沒命中:每一輪對話如果無法重複利用前面的快取,就等於把整段 system prompt、CLAUDE.md、過往對話全部重新計費送進去一次。Anthropic 的計費也明確區分了三種 token 來源(fresh input、cache write、cache read),三者單價差距很大,有 cache 的部分只需要 10% 的 Token 費用,是否吃到 cache 直接決定一整段對話的成本。
這篇文章會先給一份節省 Token 的要點清單,方便忙的時候快速翻閱對照;接著再從 Claude Code 怎麼計費、prompt cache 怎麼運作講起,聊什麼操作會無聲無息把快取打破——包含很多人會誤會的「點兩下 ESC 」到底會不會讓快取失效。最後分享我自己用的一份 statusline 腳本,把 hit rate、快取剩餘時間、context 用量都印在狀態列,再搭配 refreshInterval 每 10 秒自動刷新,避免在不知情的狀況下持續燒額度。
節省 Token 的要點速覽
名詞須知
後面要點會反覆出現幾個名詞,先用一張表把意思固定下來,避免讀到一半卡住。技術細節在後面章節會展開,這裡只給最關鍵的一句話定義:
| 名詞 | 意思 |
|---|---|
| 上下文(context window) | 模型一次能看到的所有內容上限,包含 system prompt、歷史對話、工具回傳。Claude Code 在狀態列會顯示為 ctx 百分比 |
| system prompt | 對話開頭由系統送進去的指令集,告訴模型扮演什麼角色、可以用哪些工具。Claude Code 自己組好的,使用者不直接寫 |
| CLAUDE.md | 專案根目錄或全域 ~/.claude/CLAUDE.md 的常駐指令檔,每輪請求都會被塞進 system prompt 後面 |
| Claude Code Skills | 放在 .claude/skills/ 或 ~/.claude/skills/ 的 markdown 工作流,預設只載入 frontmatter 描述、被觸發時才注入主體 |
| Subagent | 跑在獨立上下文裡的 agent,主對話只會收到它的最終結論。內建有 Explore、general-purpose、Plan |
| Prompt cache | Anthropic 在 API 層提供的快取機制,把 request 從頭往後切片快取,下一輪同樣的前綴可以重用避免重算 |
| Cache hit / read | 本輪命中快取、被讀回來的 token,單價只有標準輸入價的 10% |
| Cache write | 本輪寫入快取的 token,單價比標準輸入貴 25%(5 分鐘 TTL)或貴一倍(1 小時 TTL) |
| Fresh input | 本輪沒命中快取也沒寫入快取的新內容(如使用者剛輸入的訊息、工具最新回傳),用標準輸入價 |
| TTL(time to live) | 快取存活時間。Pro 方案約 5 分鐘、Max 方案約 1 小時,超過就清掉 |
| Auto-compact | 上下文用量逼近上限時 Claude Code 自動把舊對話濃縮成摘要,會徹底清空整段快取 |
/clear | Claude Code 指令,把對話歷史清掉重新開始;同時也會丟掉所有原本的快取 |
要點清單
下面這幾條是平常用 Claude Code 最容易實踐、效果也最直接的省 token 撇步。多數圍繞著「不要動到對話前綴」這件事,背後跟 prompt cache 的運作有關(後面章節會展開),這裡先當清單翻閱:
- CLAUDE.md 寫精簡,能搬到 Skill 就搬:CLAUDE.md 每個字都會塞進每一輪請求,編輯一次就會打斷後續的快取重用。把「特定情境才需要的工作流」改寫成 Claude Code Skills 延遲載入,沒被觸發時完全不耗 token。
- 完成大型任務後主動
/clear:跑完一個大功能或長除錯後,上下文(ctx)通常已經堆了一堆無關的檔案內容、grep 結果、試錯紀錄,再繼續疊新任務只會讓 auto-compact 提早觸發。任務一段落就/clear,雖然下一輪要付一次基底重建費(system prompt + CLAUDE.md + skills 重新寫入快取),但換到後面整段對話跑在乾淨環境裡值得,也避免被舊脈絡帶偏。 - 小任務之間別亂
/clear:上下文還在個位數時清掉反而不划算——基底重建費比省下的還多。同一個主題下接連問幾個小問題、或修同一支檔案的不同地方,繼續疊上去吃 cache read 比較便宜。判斷準則:如果新問題還會用到剛才的脈絡,就別清;明顯換主題且 ctx 已爬到一定水位,才考慮清。 - 用 Plan Mode 一次想清楚再動手:Shift+Tab 切到 Plan mode 會讓 Claude 先把計畫整段提出來等確認再執行。方向錯誤時在 plan 階段否決掉只損失一輪 output token,遠比寫完才打掉重練便宜。
- 研究型任務丟給 Subagent 隔離上下文:跨檔搜尋、長文件閱讀這類「要讀很多但結論很短」的任務丟給 subagent 處理,獨立上下文讀完一堆檔案,最後只把結論回傳,主對話的上下文不會被污染。具體操作見後面〈用 Subagent 處理研究型任務〉一節。
- 讀檔用
offset/limit,不要整檔吐出來:Claude Code 內建的 Read 工具支援指定行數範圍。只關心某段函式或設定時,事先指定範圍會比讀整檔節省可觀的 token,搜尋結果用grep -A/-B抓上下文也是同樣道理。 - 不要為了比較頻繁切模型:用
/model在 Opus/Sonnet/Haiku 之間切換,每切一次都會把整段對話前綴重建一次。任務做到一半覺得卡住時換模型的成本比想像中高。 - 盯著狀態列上的
ctx與hit,別讓 auto-compact 偷襲:上下文用量逼近上限時 Claude Code 會自動 compact,一次清空整段快取。把 statusline 設好(後面有完整範例),看到ctx欄位變紅就主動收尾,比讓系統幫你決定划算很多。 - 長時間離開前先評估:目前觀察 Pro 方案 prompt cache 約 5 分鐘過期、Max 方案約 1 小時(這是 Anthropic 現階段的設定,未來有可能調整),超過 TTL 回來第一句一定 miss。如果只是離開 10 分鐘左右,max 方案完全不用擔心;如果預期離開更久就不用刻意保留快取。
- 短暫離開可用
/loop養快取:Pro 方案如果只是去倒杯咖啡、開個短會 5–15 分鐘就回來,可以開另一個視窗下/loop 4m say hi,每 4 分鐘戳一次「hi」把 TTL 往後續,回來時 cache 還在。要小心這個動作每輪都會吃 session/weekly 額度(每次 cache read + 一輪 hi/output 計費),所以離開超過 30 分鐘以上反而比直接吃一次重建費更貴,記得回來時把這個 loop 收掉——最簡單的方式是直接請 Claude Code 取消這個循環任務;如果手上跑的是比較小的模型、聽不懂「取消 loop」的意思,可以講得更明確:「用CronDelete刪掉這個 loop 的任務 ID」。另外關閉整個 session 也能讓它停止觸發,不過不一定收得乾淨——下次用--resume/--continue接回對話時,沒過期的任務可能又會被帶回來繼續跑。
上面這些撇步「為什麼有效」的細節,會在後面講完計費邏輯與 prompt cache 機制後變得更清楚。先進入計費怎麼算的部分。
Claude Code 的 Token 怎麼算
Claude API 把每一次 request 的 token 拆成四個欄位回報,這四個欄位也是 Claude Code statusline 拿得到的數值:
| 欄位 | 意思 | 計費特性 |
|---|---|---|
| input tokens | 本輪新送進去、沒被快取的內容 | 標準輸入價 |
| cache creation | 本輪寫入快取的 token(cache write) | 比輸入貴 25%(5m TTL)或貴一倍(1h TTL) |
| cache read | 本輪命中快取、被讀回來的 token | 只要輸入價的 10% |
| output tokens | 模型回應產生的 token | 輸出價(最貴) |
這張表的關鍵在最後兩欄:cache read 的單價只有標準輸入的十分之一,所以一段對話的成本能不能壓低,幾乎就看 cache read 占整體輸入的比例有多高。我們把這個比例稱為 cache hit rate,計算方式是 cache_read / (cache_read + cache_write + input)。在一輪正常的延續對話裡,hit rate 應該要落在 90% 以上;如果掉到 70% 以下就代表這輪有大量內容被當成新輸入重算,背後通常是快取被破壞了。
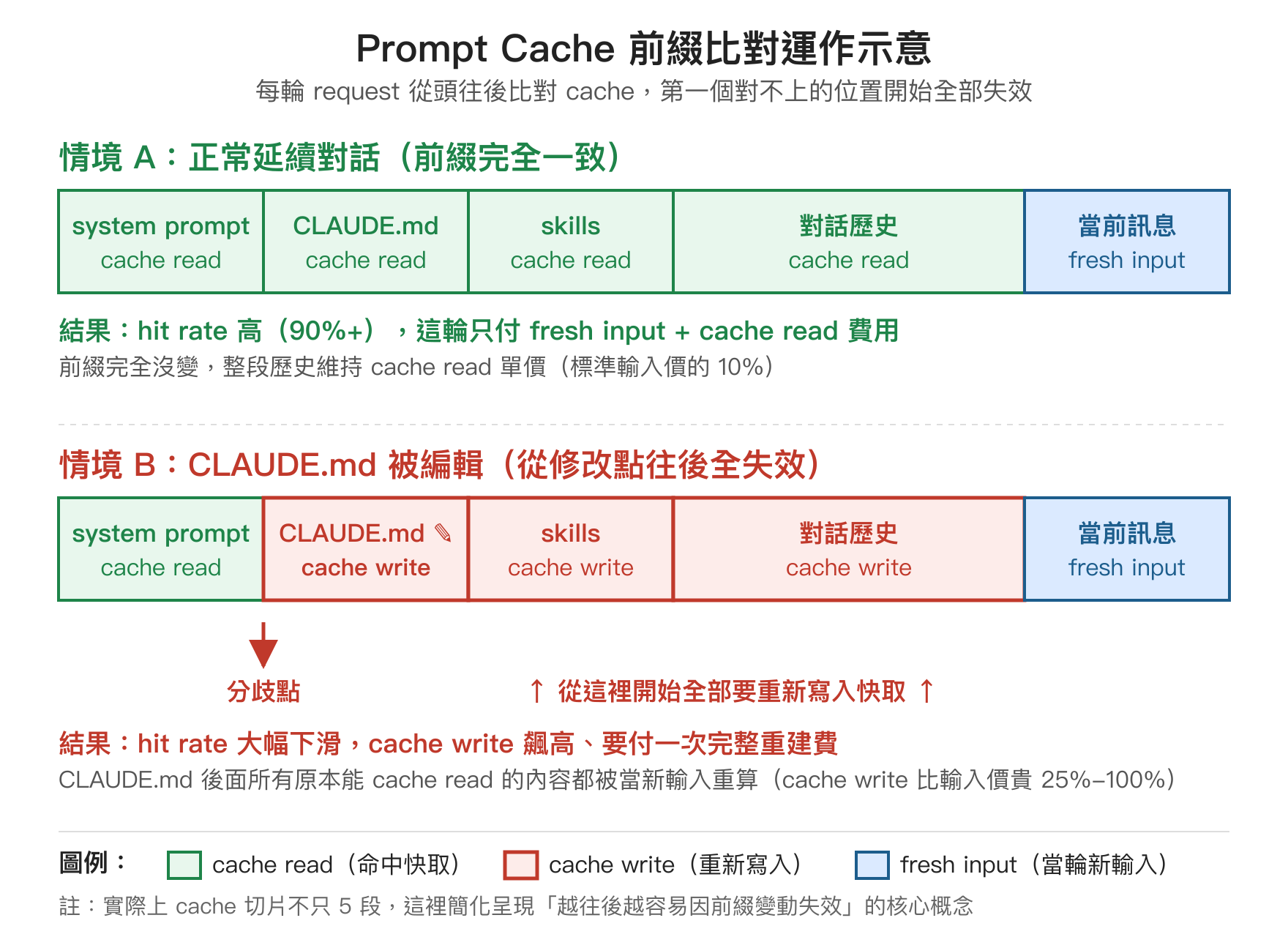
Prompt Cache 的運作原理
Anthropic 的 prompt cache 走的是前綴比對(prefix match)。每次 request 送進去之後,伺服器會把整段 prompt 從頭往後切成多個區段,每個區段算一個 hash key 暫存在快取裡。下一次 request 進來時,從第一個 token 開始往後比對,能對得上的部分就直接用快取版本,從第一個對不上的位置往後就全部重算並寫入新快取。
這個機制有兩個推論很重要。第一,快取是「從頭比對」而不是「整體比對」,所以前綴只要動到一個字,後面整段就全部失效。第二,快取有 TTL:API 預設 5 分鐘版本,每多一筆 request 命中就會把過期時間往後續,沒人來戳的話過了 5 分鐘整段消失。Claude 也提供 1 小時 TTL 的擴充版本(價格上 cache write 收費翻倍、但 cache read 一樣便宜),目前觀察 Claude Code 在 Max 方案下會自動使用 1 小時 TTL,Pro 方案則是 5 分鐘。
這也解釋了為什麼長時間放著不動再回來,第一句話會特別貴——因為原本的快取已經過期被清掉,這輪等於把整個 system prompt、CLAUDE.md、所有歷史對話重新寫進新快取。也就是 statusline 上會看到 cache write 飆高、cache read 變成 0、hit rate 直接歸零的狀況。
Context 越大,每輪對話越貴
很多人以為「有 cache 就不用怕對話變長」,這個誤會其實不小。Prompt cache 確實把已快取部分的單價打到 10%,但快取的內容還是要在每一輪請求裡整段重新送進去讓模型看見——只是用 cache read 的便宜價結帳,並不是「同樣的內容只算一次」。換句話說,對話跑得越久、上下文堆得越高,每一輪的輸入帳單也會跟著線性成長,差別只在於成長的斜率比沒 cache 時平緩許多。
具體算一下就很清楚。以 Opus 標準輸入 $15/M、cache read $1.5/M 為例,假設 cache hit rate 都維持在 95%:上下文還在 10k tokens 時,每輪輸入成本約 $0.08;爬到 100k 時來到 $0.27;接近 200k 時就漲到 $0.49。同樣一句「我繼續修這支函式」的對話,差別只在背後拖了多少歷史,這一輪的輸入帳單就能差到六倍以上。如果完全沒有 cache(例如剛經歷 auto-compact 或 /clear 後第一輪),同樣 200k 上下文每輪會直接跳到 $3.05,差距更誇張。
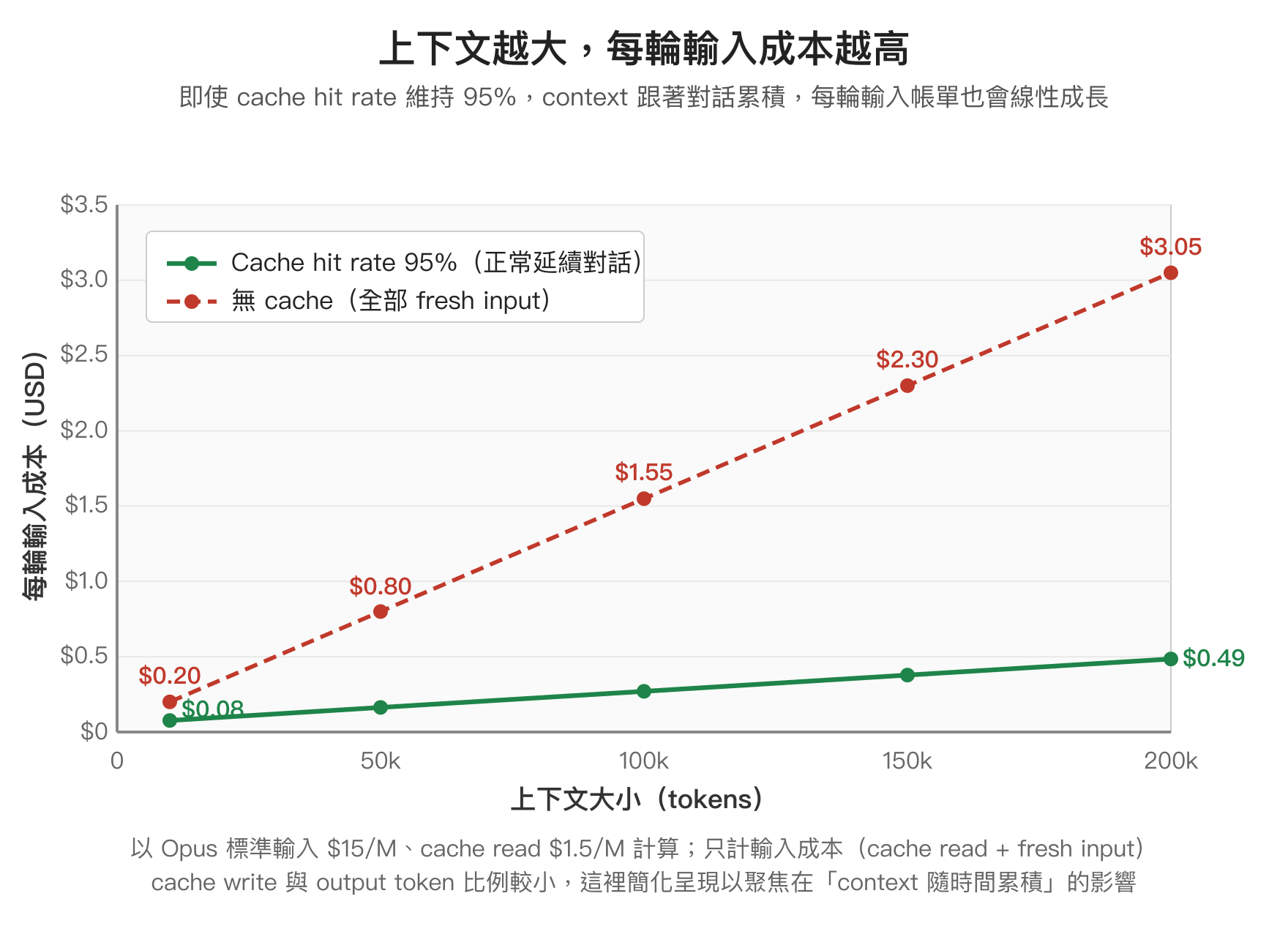
所以與其等到 auto-compact 觸發才被動收場,平常就盯著 statusline 上的 ctx 百分比、適時用 /clear 或拆 subagent 把上下文壓低,才是長期省成本的關鍵。後面的 statusline 章節會把這個監控做法補完整。
什麼操作會破壞快取
因為快取走前綴比對,只要對話「從中間任何一處」開始與先前不同,後面就全部失效。常見的破壞情境整理如下:
改動 system prompt 來源檔
CLAUDE.md(不管專案的還是全域 ~/.claude/CLAUDE.md)一旦被編輯儲存,下一輪對話組起來的 prompt 前段就跟前一輪不同,整個 cache 會從那個位置往後全部失效。新增、移除、啟用、停用一個 skill 也是同樣效果——skill 的 frontmatter 列表會被注入到系統提示裡,列表變了前綴就斷掉。切換 output style 也會落在這個段落,等於每改一次設定就要付一次重建快取的錢。
切換模型
Opus、Sonnet、Haiku 之間互換時,不只是模型換掉,連對應的 system prompt 也會被替換成適合該模型的版本,等於整段前綴重洗。常見的反模式是任務做到一半覺得卡住,連續用 /model 切來切去比較,每切一次就燒一次完整快取重建費。
切換 effort level
Claude Code 的 effort level 控制模型的思考預算(extended thinking budget)。切換 effort 會改變請求的 thinking 參數,導致 message history 層級的快取失效——不過 system prompt 和 tool definitions 的快取不受影響,所以衝擊比切換模型小。實務上的意思是:如果在對話中途從 high 切到 low 再切回 high,每次切換都會付一次 message history 的重建費用。建議在對話開始時就決定好 effort level,避免中途反覆調整。
Auto-compact 與 /compact
當上下文用量逼近上限,Claude Code 會自動觸發 compact,把過往對話濃縮成摘要再繼續。compact 之後的對話前綴是「全新的摘要文字」而不是「原本的歷史訊息」,所以 compact 會徹底清空整個快取。手動 /compact 也是一樣效果。這是為什麼 statusline 上監控上下文百分比有意義——超過某個門檻就該主動收尾或 /clear,避免讓 auto-compact 在不知情的狀況下重建一切。
/clear 與開新 session
/clear 直接把對話歷史清掉重新來,舊快取會被孤立在那邊等 TTL 過期自然消失。從成本角度看,/clear 跟 compact 都會讓下一輪付一次完整重建費,但 /clear 的好處是「乾淨」:模型不會被先前無關的脈絡帶歪,同樣一筆 cache write 換到的是更聚焦的工作環境。如果手上的任務跟前面對話完全無關,/clear 永遠比繼續疊上去划算。
TTL 過期
前面提到 Pro 5 分鐘、Max 1 小時。中間長時間沒互動再回來時,第一輪一定 miss。如果預期會離開電腦一陣子又不想付重建費,可以在離開前刻意送一個小訊息延長 TTL,或是接受重建費直接離開。實務上 Max 的 1 小時 TTL 已經寬鬆很多,平常工作節奏下幾乎不會自然過期。
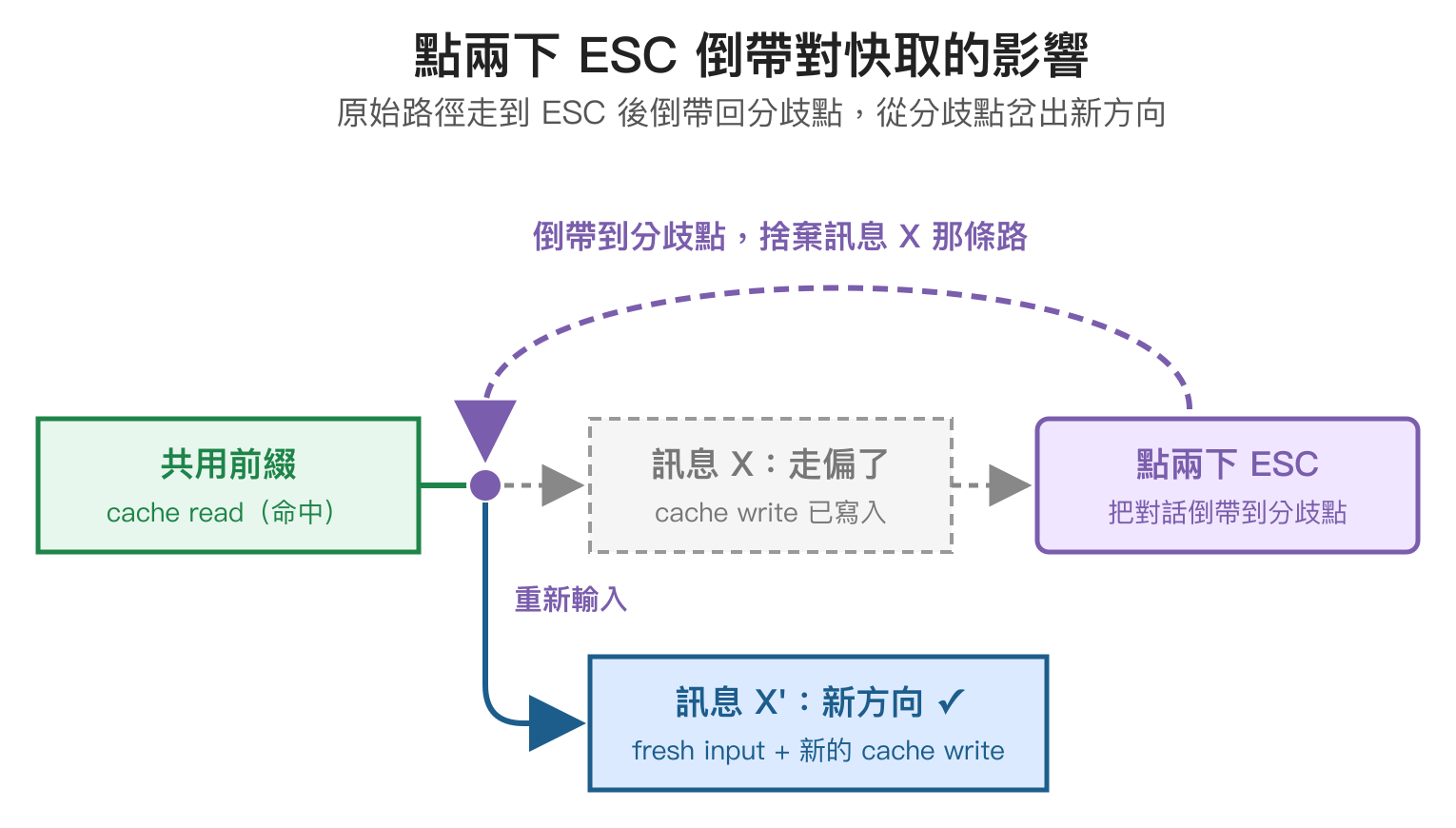
點兩下 ESC 會不會破壞快取?
這題很多人有疑問。Claude Code 在輸入框按兩下 ESC 會跳出歷史紀錄選單,讓使用者把對話倒帶到前面某一輪重新開始。從快取的角度看,倒帶本身不會讓被丟掉的那段 cache「立刻失效」——倒帶後的前綴跟原本的對話前綴完全一致,所以倒帶之後重新發出的第一輪訊息,前面那段 cache 會 hit;分歧發生在「倒帶之後輸入的新內容」與「原本被丟掉的那段內容」不同的地方,從那裡之後全部要重算。
換句話說,點兩下 ESC 倒帶的損失等於「丟掉的那段對話的 cache write 成本白付了」,但前面共用的快取還能繼續用。實務上這比 /clear 划算很多,特別適合「方向走偏想換條路試試」的情境。要注意的是被丟掉的那段 cache 雖然在伺服器上還沒到期,但因為新對話不會再走那條路徑,所以那段快取就只是靜靜地等 TTL 過期消失,再也不會被用到。
Fork session 也是同樣道理
Claude Code 用 --fork-session(搭配 --resume 或 --continue)會把目前對話複製成一個新的 session ID 繼續走,原本的 session 完整保留。從快取角度看,跟點兩下 ESC 是同一個道理:Anthropic 的 prompt cache 是用「prompt 內容前綴的 hash」當 key,不綁 session ID。所以 fork 出去的新 session 在分歧點之前的內容跟母 session 一字不差,那段照樣命中 cache read;只有分歧之後新輸入的內容才會走 cache write/fresh input。
跟 ESC 倒帶的差別只在「原路徑要不要保留」:ESC 倒帶把原本那段路覆蓋掉再也回不去;fork 則是兩條分支並存,可以在 session 選單裡隨時切回母 session 繼續原本那條路。實務上想做「同一個前提,分頭試兩種解法」就用 fork,已經確定方向走偏不會回頭就用 ESC——兩者付的 cache 重建費完全一樣。
用 Subagent 處理研究型任務
前面提到「研究型任務丟給 subagent」是省 token 的關鍵之一。為什麼有效?因為 subagent 跑在獨立的上下文裡:它讀進去的所有原始檔案、grep 結果、API 回應通通只存在於 subagent 自己的對話脈絡,主對話只會收到 subagent 的最終結論。對主對話的快取來說,這等於「用一筆有界的 subagent 成本,換到主上下文持續精簡」——主對話的前綴不會因為塞進大量檔案內容而暴漲,後續輪次都還能持續命中快取。
把這個過程畫出來,subagent 期間的總用量會像閃電一樣瞬間衝高、又瞬間落下:subagent 在獨立 context 裡讀越多檔案,總 token 用量就越高;但 subagent 一結束,那段獨立 context 整個釋放掉,只有最終摘要會回到主對話。如果是直接在主對話裡讀同樣的檔案,這些內容會永久累積在主上下文裡——後續每一輪都要付這份歷史的 cache read 費。
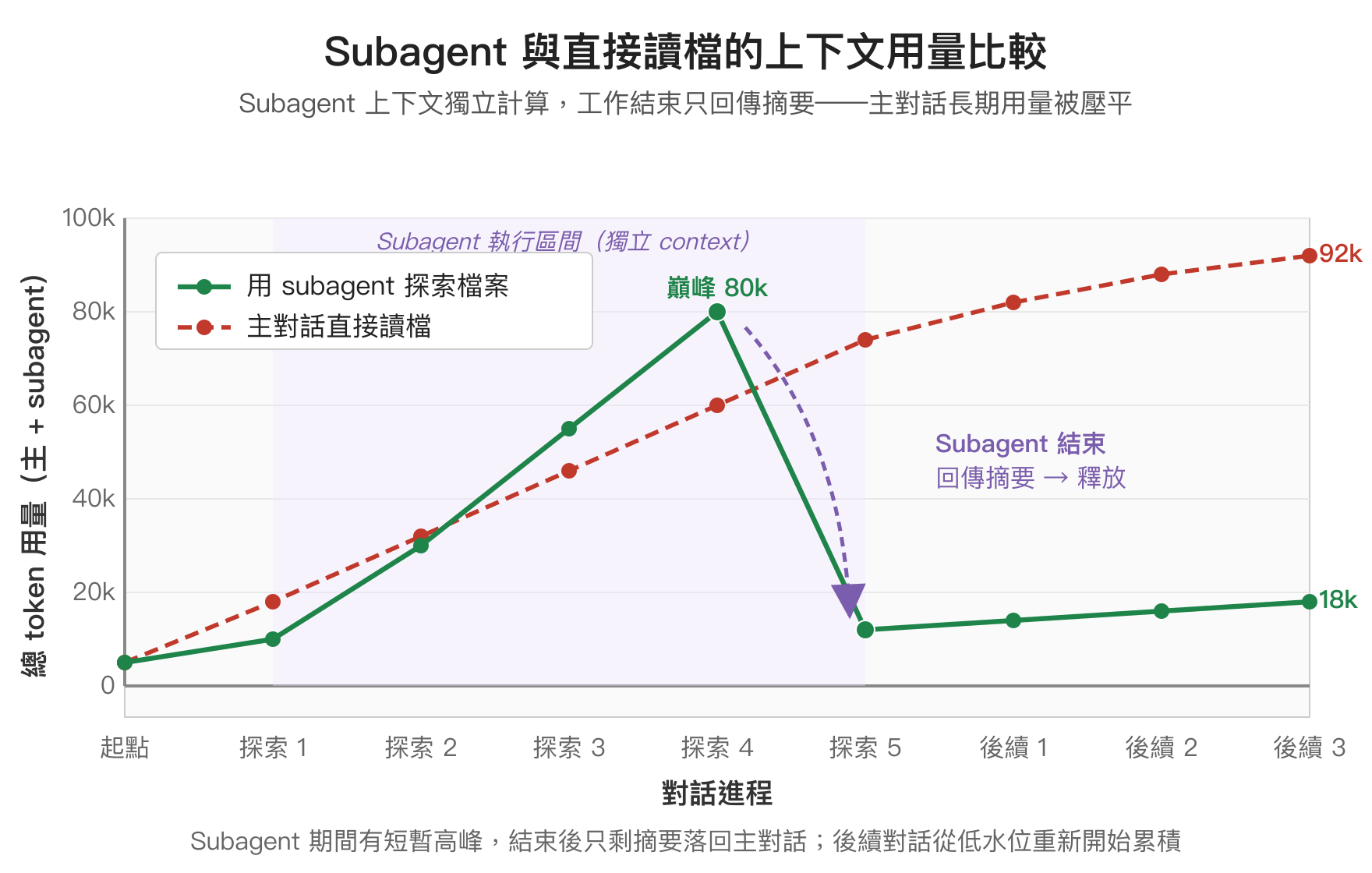
什麼任務適合丟 Subagent
判斷準則一句話:「要讀很多、但結論很短」就丟 subagent。常見適合的場景:
- 跨檔搜尋程式碼裡某個 symbol/某段邏輯的所有引用位置
- 讀完一份長的 RFC、設計文件、第三方 API 文件後給簡短摘要
- 掃過整個 repo 找出哪些檔案還在用舊版 API、舊套件
- 跑多次
find/grep嘗試不同關鍵字才能定位的探索性搜尋 - 需要瀏覽多個目錄結構才能回答「這個專案大致怎麼組織」的問題
反過來,明確知道要改哪裡的編輯任務不要丟 subagent。Subagent 拿不到主對話的上下文,把實作任務丟過去等於要重新交代背景,反而更花 token;而且實作完成後 subagent 回傳的內容主對話還要重新理解一次,沒比自己直接動手便宜。
內建 Subagent 怎麼叫出來
Claude Code 內建幾個 subagent,最常用的三個:
| Subagent | 用途 | 什麼時候叫它 |
|---|---|---|
Explore | 快速程式碼搜尋 | 要找符號定義、追引用、locate files 時 |
general-purpose | 通用研究、多步驟任務 | 需要多步驟搜尋、整合不同來源結論時 |
Plan | 規劃實作步驟 | 動手前先請它把流程列出來討論 |
不需要記指令,直接用自然語言講就會觸發:
- 「用 Explore agent 幫我找專案裡所有
useAuth的呼叫位置」 - 「開個 subagent 讀完
docs/architecture.md跟RFC-042.md,給我 200 字摘要」 - 「跨整個 codebase 找出哪些檔案還在用舊版 logger,列出檔案路徑就好」
Claude Code 看到這類描述會主動用 Task 工具呼叫對應的 agent,主對話最後只會看到結論。如果不確定該用哪個 agent,講「開個 subagent 處理 ⋯⋯」就好,Claude Code 會自己挑合適的。
寫自己的 Custom Subagent
同一個流程會反覆需要時,可以寫成自訂 subagent,下次叫得更精準。把 markdown 檔放到 ~/.claude/agents/<name>.md(全域)或 .claude/agents/<name>.md(當前專案):
---
name: api-doc-reader
description: 讀完 docs/api 下的 OpenAPI 文件,回傳指定端點的參數與範例
tools: Read, Grep, Glob
---
當被叫來時:
1. 用 Glob 找出 docs/api/ 底下所有 .yaml、.md 檔案
2. Read 全部檔案內容
3. 找出指定端點(從使用者輸入推斷)
4. 回傳「參數列表 + 一個 curl 範例」即可,不要轉貼整段原文name 是識別名稱,description 用來告訴 Claude「什麼情境要叫這個 agent」,tools 限制這個 agent 能用哪些工具(不寫就繼承所有工具)。寫好之後在主對話講「用 api-doc-reader 找 /users/:id 的細節」就會被觸發,跟內建 agent 用法一致。
注意:Subagent 看不到主對話的歷史,叫它的時候要把必要前提一次講清楚。例如「用 Explore 找 handleClick 的定義」要補上「我們在 React 專案、檔案大多在 src/ 下」這類資訊,不然 subagent 可能會在無關目錄裡白繞一圈。
用 statusline.sh 觀察快取狀態
知道這些原理之後,下一個問題是怎麼即時觀察。Claude Code 提供 statusLine 設定,每次模型回應結束會把 session 資訊(包含 token 用量、cache 狀況)以 JSON 從 stdin 餵給指定腳本,stdout 印出來的內容就是狀態列。我自己寫了一份 ~/.claude/statusline.sh,把幾個關鍵欄位拉出來顯示。
設定方法
在 ~/.claude/settings.json 加上:
{
"statusLine": {
"type": "command",
"command": "~/.claude/statusline.sh",
"padding": 0,
"refreshInterval": 10
}
}refreshInterval 是這份設定的關鍵:預設情況下 statusline 只會在每次 Claude 回應結束時更新一次,所以「離開電腦十分鐘再回來」狀態列上的快取剩餘時間還停在十分鐘前的數字,看不出快取是不是已經過期。設成 10 代表每 10 秒重新跑一次腳本,這樣即使沒有發出新訊息,狀態列也會持續更新「距離上次 API 回應幾秒」這個數字,超過快取 TTL 前變紅色提醒。
腳本核心邏輯
腳本第一行是計畫類型,後面三組門檻決定何時把對應數字變紅:
#!/bin/sh
# plan_mode: set to "pro" or "max"
plan_mode="max"
# 快取過期紅字門檻(秒);0 = 永不變紅
# pro 方案 prompt cache 約 5 分鐘過期,max 方案約 1 小時,超過就要重算 cache
case "$plan_mode" in
pro) ago_red_threshold=270 ;; # 4m30s,留 30 秒緩衝
max) ago_red_threshold=3300 ;; # 55m,留 5 分鐘緩衝
*) ago_red_threshold=0 ;;
esac
# Cache hit rate 紅字門檻(%);低於此值顯示紅字提醒
hit_red_threshold=70
# Context window 紅字門檻(%);高於此值顯示紅字提醒
ctx_red_threshold=50三個門檻各自代表不同警示。ago_red_threshold 是「距離上次 API 回應幾秒」變紅的門檻,pro 設 270 秒(5 分鐘 TTL 留 30 秒緩衝),max 設 3300 秒(1 小時 TTL 留 5 分鐘緩衝)。hit_red_threshold 設 70 代表 cache hit rate 低於 70% 就把該欄整個變紅,提示這輪 cache 出了問題。ctx_red_threshold 設 50 代表上下文(context window)用量超過 50% 就提醒,留下足夠空間在 auto-compact 觸發前自己決定要 /clear 還是收尾。
腳本會從 stdin 解析 JSON、把模型名稱、effort 等級、session/weekly 額度、累積成本、上下文百分比印在第一行,第二行則印 cache hit rate、cache write/read、新輸入/輸出 token、上次 API 更新時間,以及距離現在多久。最後那個「多久前」的時間是靠把上一次 token 數字記在 /tmp/claude-statusline/ 比對得出,token 數字一改就代表 API 有新回應,時間戳跟著更新。
完整腳本
#!/bin/sh
plan_mode="max"
case "$plan_mode" in
pro) ago_red_threshold=270 ;;
max) ago_red_threshold=3300 ;;
*) ago_red_threshold=0 ;;
esac
hit_red_threshold=70
ctx_red_threshold=50
input=$(cat)
model_full=$(echo "$input" | jq -r '.model.display_name // empty')
model_short=$(echo "$model_full" | sed 's/ *([^)]*)//g; s/^[Cc]laude *//;' | tr '[:upper:]' '[:lower:]')
# Effort level(v2.1.128+ 開始可從 statusline JSON 取得)
effort=$(echo "$input" | jq -r '.effort_level // empty')
session_pct=$(echo "$input" | jq -r '.rate_limits.five_hour.used_percentage // empty')
weekly_pct=$(echo "$input" | jq -r '.rate_limits.seven_day.used_percentage // empty')
ctx_pct=$(echo "$input" | jq -r '.context_window.used_percentage // empty')
cost_usd=$(echo "$input" | jq -r '.cost.total_cost_usd // empty')
cwd=$(echo "$input" | jq -r '.workspace.current_dir // empty')
git_branch=""
if [ -n "$cwd" ]; then
git_branch=$(GIT_OPTIONAL_LOCKS=0 git -C "$cwd" symbolic-ref --short HEAD 2>/dev/null)
fi
if [ -n "$effort" ]; then
parts="${model_short} (${effort})"
else
parts="${model_short}"
fi
if [ -n "$session_pct" ] && [ -n "$weekly_pct" ]; then
parts="${parts} | session: $(printf '%.0f' "$session_pct")% | weekly: $(printf '%.0f' "$weekly_pct")%"
fi
if [ -n "$cost_usd" ]; then
parts="${parts} | $(printf '$%.2f' "$cost_usd")"
fi
if [ -n "$ctx_pct" ]; then
ctx_int=$(printf '%.0f' "$ctx_pct")
if [ "$ctx_int" -gt "$ctx_red_threshold" ]; then
ctx_str=$(printf "\033[31mctx: %s%%\033[0m" "$ctx_int")
else
ctx_str="ctx: ${ctx_int}%"
fi
parts="${parts} | ${ctx_str}"
fi
if [ -n "$cwd" ]; then
dir_name=$(basename "$cwd")
parts="${parts} | ${dir_name}${git_branch:+ ($git_branch)}"
fi
printf "%s" "$parts"
# 第二行:token 與 cache 資訊
cache_write=$(echo "$input" | jq -r '.context_window.current_usage.cache_creation_input_tokens // 0')
cache_read=$(echo "$input" | jq -r '.context_window.current_usage.cache_read_input_tokens // 0')
input_tokens=$(echo "$input" | jq -r '.context_window.current_usage.input_tokens // 0')
output_tokens=$(echo "$input" | jq -r '.context_window.current_usage.output_tokens // 0')
total_input=$((cache_read + cache_write + input_tokens))
if [ "$total_input" -gt 0 ]; then
hit_rate=$(awk "BEGIN { printf \"%.0f\", $cache_read * 100 / $total_input }")
if [ "$hit_rate" -lt "$hit_red_threshold" ]; then
hit_str=$(printf "\033[31mhit: %s%%\033[0m | " "$hit_rate")
else
hit_str="hit: ${hit_rate}% | "
fi
# 用 token 數字當簽名追蹤上次 API 更新時間
state_dir="/tmp/claude-statusline"
mkdir -p "$state_dir" 2>/dev/null
session_id=$(echo "$input" | jq -r '.session_id // empty')
state_file="${state_dir}/${session_id:-default}"
current_sig="${cache_write}-${cache_read}-${input_tokens}-${output_tokens}"
now=$(date +%s)
last_update=$now
if [ -f "$state_file" ]; then
prev_sig=$(awk 'NR==1' "$state_file")
prev_time=$(awk 'NR==2' "$state_file")
[ "$current_sig" = "$prev_sig" ] && [ -n "$prev_time" ] && last_update=$prev_time
fi
[ "$last_update" = "$now" ] && printf "%s\n%s\n" "$current_sig" "$now" > "$state_file"
elapsed=$((now - last_update))
if [ "$elapsed" -lt 60 ]; then
ago_str="${elapsed}s"
elif [ "$elapsed" -lt 3600 ]; then
ago_str="$((elapsed / 60))m$((elapsed % 60))s"
else
ago_str="$((elapsed / 3600))h$(((elapsed % 3600) / 60))m"
fi
if [ "$ago_red_threshold" -gt 0 ] && [ "$elapsed" -ge "$ago_red_threshold" ]; then
ago_display=$(printf "\033[31m(%s ago)\033[0m" "$ago_str")
else
ago_display="(${ago_str} ago)"
fi
printf "\n%scache: %s, %s | in: %s, out: %s | %s" \
"$hit_str" "$cache_write" "$cache_read" "$input_tokens" "$output_tokens" "$ago_display"
fi儲存到 ~/.claude/statusline.sh 之後記得 chmod +x,然後在 settings.json 設好 statusLine 跟 refreshInterval 就會出現在每次回應底下。
注意:腳本中的 effort_level 欄位是 Claude Code v2.1.128(2026 年 5 月第三週) 才加進 statusline JSON 的。如果版本較舊,這個欄位會是空值,腳本會自動略過不顯示,不影響其他功能。更新到最新版即可:claude update。
也可以讓 AI 幫忙產生跨平台版本
上面那份腳本是 POSIX sh 寫的,macOS 跟 Linux 直接能跑,但 date -r、awk、/tmp 路徑這些細節在 Windows 原生環境會踩雷。如果想在不同平台都用得上,可以把下面這份提示詞貼到 Claude Code(或任何能執行指令的 AI 助手),它會先偵測作業系統再決定要產 sh 還是 PowerShell:
請幫我建立一份 Claude Code 的 statusLine 腳本,要顯示以下資訊並支援我目前的作業系統。
## 偵測環境
請先用指令確認我目前的環境(macOS / Linux / Windows、shell 種類),再決定用哪種腳本格式:
- macOS / Linux / WSL / Git Bash → 寫成 POSIX sh 腳本(#!/bin/sh)
- Windows 原生(無 WSL/Git Bash) → 寫成 PowerShell 腳本(.ps1)
- 任何環境都需要 jq 來解析 JSON,請先檢查 jq 是否安裝;沒裝的話先給我安裝指令再繼續
## 輸入格式
Claude Code 會把以下 JSON 從 stdin 餵給腳本,腳本要解析需要的欄位:
- .model.display_name(例如 "Claude Opus 4.7 (1M context)")
- .effort_level(例如 "high"、"xhigh")
- .output_style.name
- .rate_limits.five_hour.used_percentage
- .rate_limits.seven_day.used_percentage
- .context_window.used_percentage
- .context_window.current_usage.cache_creation_input_tokens
- .context_window.current_usage.cache_read_input_tokens
- .context_window.current_usage.input_tokens
- .context_window.current_usage.output_tokens
- .cost.total_cost_usd
- .workspace.current_dir
- .session_id
## 顯示內容(兩行)
**第一行**:{model} ({effort}) | session: X% | weekly: X% | $X.XX | ctx: X% | {dir} ({git_branch})
- model 去掉 "Claude " 前綴與括號內容並轉小寫(例:opus 4.7)
- effort 顯示目前的 effort 等級(例:high、xhigh),沒有值時省略括號
- ctx 超過門檻整段(含 "ctx:")變紅字
**第二行**:hit: X% | cache: {write}, {read} | in: X, out: X | (Xs ago)
- hit rate = cache_read / (cache_read + cache_write + input),低於門檻整段變紅
- (Xs ago) 是「距離上次 API 回應幾秒」,超過門檻變紅
- 「上次 API 回應」用以下方法判斷:把當輪 token 數字拼成簽名存進暫存檔,下次執行比對簽名相同就沿用之前的時間戳;不同就更新成現在時間
- macOS / Linux:暫存檔放 /tmp/claude-statusline/{session_id}
- Windows:放 %TEMP%\claude-statusline\{session_id}
## 開頭可調門檻
腳本最上方留三組變數方便調整,附中文註解:
- plan_mode = "max" # 切換 pro / max
- ago_red_threshold # plan_mode=pro → 270(5min TTL 留 30 秒緩衝)
# plan_mode=max → 3300(1hr TTL 留 5 分鐘緩衝)
# 0 = 永不變紅
- hit_red_threshold = 70 # cache hit rate 低於此值變紅
- ctx_red_threshold = 50 # context 用量超過此值變紅
## 紅字輸出
- 終端機 ANSI:\033[31m...\033[0m(POSIX sh)
- PowerShell:用 $([char]27)[31m...$([char]27)[0m(注意 statusLine 收的是 stdout,PowerShell 要把 ANSI 字串組進輸出)
## 跨平台細節
- date 取秒數時間戳:macOS/Linux 用 date +%s;PowerShell 用 [int][double]::Parse((Get-Date -UFormat %s))
- 把秒數轉回 HH:MM:SS:macOS 用 date -r、Linux 用 date -d "@...",腳本要兩者都試
- awk 在 Windows 原生沒有,PowerShell 版改用內建運算
- 確保純 ASCII,避免 BOM 或 CRLF 在 sh 上炸掉
## 安裝後驗證
產生完腳本要:
1. 給 chmod +x(POSIX)或設定 ExecutionPolicy(PowerShell)
2. 在 ~/.claude/settings.json(macOS/Linux)或 %USERPROFILE%\.claude\settings.json(Windows)加上:
{
"statusLine": {
"type": "command",
"command": "<腳本絕對路徑>",
"padding": 0,
"refreshInterval": 10
}
}
3. 用 echo '{...}' | <腳本> 餵一段假 JSON 測一次,確認輸出正常這份提示詞的重點是先偵測環境再決定腳本格式、明確列出 JSON 欄位避免 AI 自己編 schema,並且把跨平台地雷(date、awk、暫存路徑)一次提醒清楚。產出的腳本不會只在 macOS 能跑,PowerShell 版的 ANSI 顏色處理也會考慮到。
解讀狀態列
實際運作起來大致像這樣(以 Max 方案為例):
opus 4.7 (high) | session: 32% | weekly: 18% | $4.21 | ctx: 23% | project (main)
hit: 96% | cache: 1240, 38500 | in: 320, out: 580 | (12s ago)每個欄位代表的意思整理在下表:
| 欄位 | 意義 | 怎麼判讀 |
|---|---|---|
opus 4.7 | 目前使用的模型 | 切換模型會打破快取,注意不要為了比較頻繁切換 |
(high) | 目前的 effort 等級 | low/medium/high/xhigh/max,等級越高模型推理越深入但消耗越多 token。用 /effort 調整 |
session: 32% | 5 小時 session 額度已用比例 | 接近 100% 就會被強制等待重置 |
weekly: 18% | 7 天週額度已用比例 | 長期工作節奏的參考;週末跑大任務前先看一下 |
$4.21 | 本 session 累積成本(USD) | 方案內不額外付費,但可以拿來估算 API 直接呼叫的等價成本 |
ctx: 23% | 當前上下文(context window)用量 | 超過設定門檻變紅,提醒接近 auto-compact,建議 /clear 或收尾 |
project (main) | 當前工作目錄與 git 分支 | 確認自己在對的專案與分支上工作 |
hit: 96% | 本輪 cache hit rate | 90% 以上健康;低於 70% 變紅,代表這輪有大量內容被當新輸入重算 |
cache: 1240, 38500 | cache write, cache read tokens | write 飆高代表前綴被打破;read 大表示有效利用快取 |
in: 320 | 本輪 fresh input tokens | 沒被快取的新內容,例如使用者剛輸入的訊息與工具回傳 |
out: 580 | 本輪 output tokens | 模型回應產生的 token,單價最貴 |
(12s ago) | 距離上次 API 回應的時間 | 超過快取 TTL 門檻變紅,下一輪會付一次完整重建費 |
幾個常見的紅字組合可以這樣判讀:hit 整段變紅、cache write 飆高,幾乎可以確定剛才動了 CLAUDE.md、改了 skill、切了模型或 compact 過。ctx 變紅代表接近 auto-compact 門檻,建議切換任務或 /clear。(12s ago) 變成 (56m ago) 且整段變紅,代表快取已經到期、下次發訊息會付一次完整重建費。模型名稱後面的 effort 等級(如 (high))可以讓你一眼確認目前的推理深度——有時候 skill 或 subagent 會隱式改變 effort,沒有狀態列的話不容易察覺。
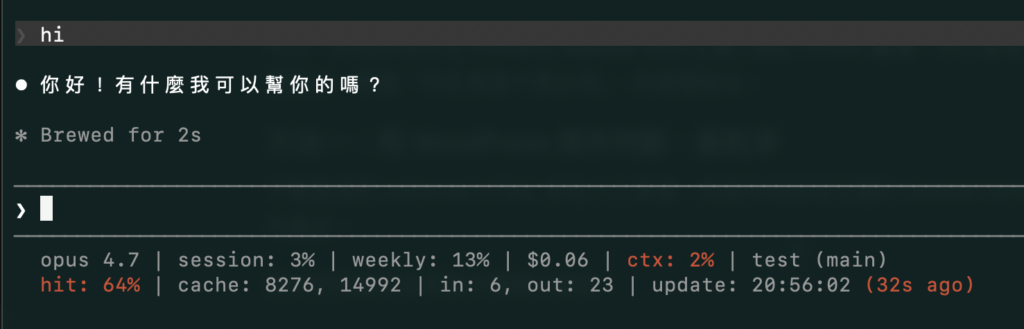
這邊實際示範,並且調整了變紅字的用量與時間,方便看到警示效果。想要更顯眼可以讓 AI 幫忙改成紅底白字之類,更顯眼的顯示方式。
小結
Claude Code 的計費邏輯把「對話歷史」轉換成 cache read/cache write/fresh input 三種不同單價的 token,是否吃到 cache 直接決定一段對話的成本。Prompt cache 走前綴比對 + TTL 過期,所以幾乎所有「省 token 的撇步」核心都是同一件事:避免讓前綴變動、避免讓 TTL 流逝。CLAUDE.md 寫精簡、用 Skills 取代靜態指令、任務切換時主動 /clear、用 subagent 隔離雜訊,每一條都是這個原則的應用。
點兩下 ESC 倒帶不會立刻摧毀快取,但被丟掉的那段 cache write 就是白付的,使用前可以先評估是不是用「再追加一句修正」就能達到同樣效果。最後,把 statusline.sh 配合 refreshInterval: 10 接起來,hit rate、上下文用量、快取剩餘時間就會持續顯示在眼前,比起發現額度燒光才回頭找原因,主動觀察狀態列才是長期最省成本的做法。