
用 Claude Code 一段時間之後,會發現有些工作流動不動就要重複交代——commit message 要怎麼寫、PR 描述要分幾段、處理特定格式的檔案要先做哪幾步。把這些東西寫進 CLAUDE.md 雖然有效,但每一筆指令都會佔走 context window,累積到一定程度反而拖慢模型表現。Skills 就是 Claude Code 為了解決這個問題而設計的輕量擴充機制:把工作流寫成一個獨立的 SKILL.md,靠檔案內的 description 讓 Claude 自動判斷什麼時候要載入,沒用到的時候完全不佔 context。比起寫 MCP server 簡單很多,比塞進 CLAUDE.md 又乾淨許多,這篇文章整理一下這個機制怎麼運作、放在哪裡、以及怎麼自己寫一個。
Skill 是什麼
一個 Skill 本質上就是一個資料夾,裡面有一份 SKILL.md 檔案,外加可能會用到的腳本或範本。SKILL.md 的開頭是 YAML frontmatter,主體是 Markdown 寫的指令說明:
---
name: commit-helper
description: 依照可獨立執行的功能區塊進行 git commit,每個提交的範圍要可以完整獨立運作
---
# Commit Helper
當使用者要求建立 git commit 時:
1. 先用 `git status` 與 `git diff` 看清楚有哪些改動。
2. 把改動依「可獨立部署的功能單位」分組⋯⋯Frontmatter 兩個欄位都是必要的,name 是 skill 的識別名稱,description 則是用來告訴 Claude「在什麼情況下需要載入這個 skill」。description 寫得越精準,Claude 越能正確判斷時機;寫得太籠統會在不相關的情境被誤觸發,寫得太狹窄又會該載入的時候沒載入。
Skills 的關鍵設計是延遲載入:Claude Code 啟動時只會掃描所有 skill 的 frontmatter,主體內容並不會放進初始 context;只有在 Claude 判斷某個 skill 跟當下任務相關時,才會把對應的 SKILL.md 內容載進來。沒被觸發的 skill 完全不耗 token,所以可以放心累積幾十個 skill 在身上,後面「Skill 的格式」一節會展開三層載入的細節。
跟 MCP 的差別
Skills 跟 MCP(Model Context Protocol)server 常被放在一起討論,但兩者在做的事情完全不同。Skill 本質上就是一份 markdown 指令,告訴 Claude「遇到這種情境,請按照以下步驟處理」,所有實際動作(讀檔、跑指令、改 code)都還是 Claude 用本來就有的工具去執行。MCP server 則是一個實際在跑的程式,透過標準協議把外部能力(資料庫查詢、第三方 API、私有系統存取)暴露給 Claude 使用。
| 面向 | Skill | MCP server |
|---|---|---|
| 本質 | 純文字指令 | 持續執行的程式 |
| 能做的事 | 引導 Claude 怎麼做事 | 提供新的工具與資料來源 |
| 需要寫程式碼? | 不用,只寫 Markdown | 要寫 server(任何語言) |
| AI 原生 API 整合 | 無(不認識 MCP 等協議) | 有(標準 MCP 協議) |
| 使用通用 API/CLI | 可以(指引 Claude 用 curl、CLI、SDK 等) | 可以(在 server 端處理) |
| 狀態保存 | 無 | 可以 |
| 適合場景 | 流程規範、檔案處理、寫作格式 | 查資料庫、戳 Jira、讀內部系統 |
表格裡「AI 原生 API 整合」這列要特別解釋一下:MCP 是 Anthropic 推的標準協議,主要用途是讓 AI 直接「認得」某個工具或資料來源,協議層級的整合 skill 確實沒辦法做到。但這不代表 skill 完全碰不到外部世界——skill 還是可以指引 Claude 用 curl 打通用的 REST/GraphQL API、跑 CLI 工具(gh、aws、kubectl 等)、執行 Python/Node 寫的 SDK 呼叫,因為這些都是 Claude Code 本來就有的執行能力。差別在於:MCP 把「怎麼用某個工具」設計給 AI 直接消化,skill 則是把「怎麼用某個工具」用文字告訴 Claude,再讓 Claude 用 bash/檔案系統等通用工具去執行。
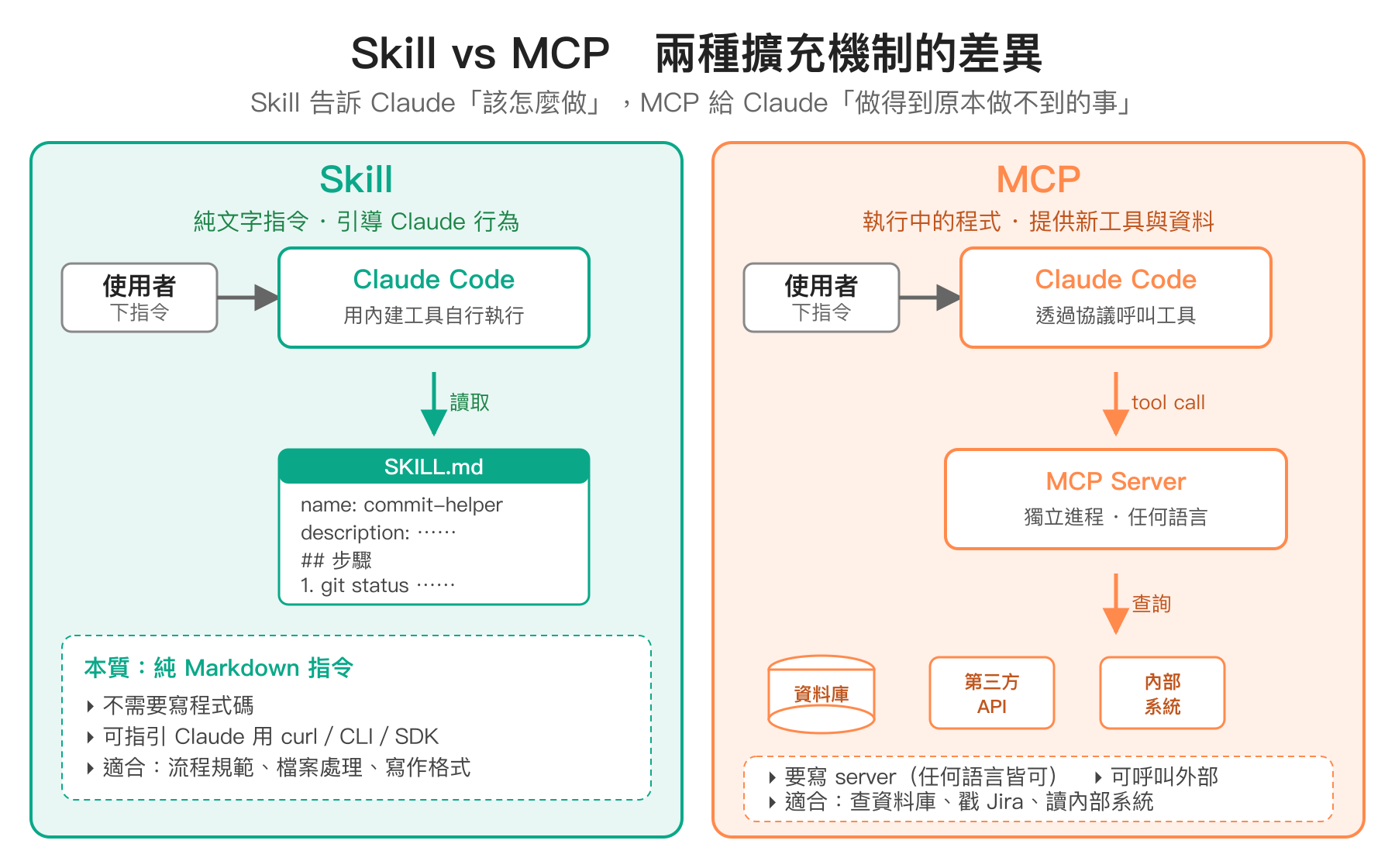
判斷的捷徑很簡單:如果只是想告訴 Claude「該怎麼做」,寫 skill;如果需要讓 Claude「做得到原本做不到的事」,才需要 MCP。兩者也可以搭配——skill 在指令裡直接呼叫某個 MCP 提供的工具,是非常自然的組合。
什麼時候適合用 Skill
Skills 最划算的場景共通點是:不是天天都做、但要做的時候步驟多、容易漏。寫一次 skill 下次自動觸發,比每次手動交代節省非常多時間。下面列三個典型的應用場景作為參考。
多步驟發佈流程
像「發佈一篇部落格文章」「跑 release checklist」「打包並上傳前端 build」這類流程,通常包含好幾個指令、檢查、與條件分支。完整寫成 skill 之後,使用者只要說「我要發 release」,Claude 就會依步驟跑:先檢查 git 狀態、再跑測試、確認 changelog、上 tag、最後推 build 上去。
這類 skill 的價值不只是省輸入時間,更重要的是把流程文件化下來——團隊新人 clone 倉庫之後不用看 README,直接讓 Claude 跑就會走完正確流程,避免漏步驟造成的事故。
特殊格式的檔案處理
像把 Word 轉成 Markdown、把 PDF 報表抽成結構化資料、把 Excel 整理進資料庫,這些都涉及到特定工具的特殊操作順序,沒有預先指引的話 Claude 容易走冤枉路。把處理 SOP 寫成 skill,遇到對應的副檔名或關鍵字就自動載入,第一次嘗試就能拿到正確結果。
這個用途之前在 MarkItDown 教學 那篇文章末尾示範過——把 docx 轉 markdown 的整套流程(含內嵌圖片抽取與置換)寫成 docx-to-markdown skill,使用者只要把檔案丟進專案,說「轉成 markdown」就能一次到位。
撰寫格式與規範
每個團隊都有自己的 commit message 慣例、PR 描述模板、code review checklist、技術文件風格。把這些規範寫成 skill 之後,每次需要產出對應的內容時 Claude 會自動依規範格式輸出,減少人工修正。
這類 skill 通常放在專案層級最合適:跟著 git 一起 commit 進倉庫,PR review 時還能順便看到規範的更新,整個團隊都能共享同一份標準。比起放在 README 等人手動翻閱,把規範直接寫成 skill 的執行率高非常多。
其他領域專精的 Skill
除了上面三個工程相關的應用,Skills 也很適合把某個專業領域的知識濃縮成可重複使用的工作流。重點在於「Claude 本身有相關背景知識,但需要被引導照特定框架走」——skill 提供框架與檢查表,讓輸出穩定可預期。幾個常見的例子:
- 前端設計:把品牌設計系統(色票、字型階層、間距 token、元件規範)寫進 skill,Claude 在做 mockup 或寫 component 時就會自動套用,不會每次都產出風格不一致的東西。也可以針對 Material Design、Apple HIG 等設計準則寫對應的 skill。
- 財報分析:把要看的指標清單(流動比率、毛利率、ROE、現金流量結構)與對應的判讀邏輯寫成 skill,丟一份年報 PDF 進來,Claude 會依固定步驟擷取數字、計算、產出比對表,避免每次手動交代要看什麼。
- 法律分析:合約 review 的檢查清單(不平等條款、免責範圍、智財權歸屬、解約條件)寫成 skill,丟入合約全文後 Claude 會依清單逐項檢視,把潛在風險條目列出來給人類審閱,比讓 Claude 自由發揮穩定許多。
這類「領域專精 skill」的關鍵不是讓 Claude 學會新知識,而是把領域內的「該怎麼看、該怎麼問、該怎麼結論」的方法論寫清楚。寫得越具體,輸出品質越穩定。對於組織內部來說,這也是把資深人員的工作流程留下來的好方式——把高手的 checklist 寫成 skill,新人也能馬上跑出接近資深的產出。
反過來說,如果一個指令每次對話都會用到(例如「回答時用繁體中文」),寫成 skill 反而是繞遠路——CLAUDE.md 是更直接的位置;如果一個工作流需要存取資料庫或第三方服務,skill 沒辦法做這件事,要走 MCP server。看清楚邊界再選工具,才不會把所有東西都塞成 skill 反而失去原本省 context 的初衷。
放在哪裡
Skills 依照範圍可以放在三個地方,分別代表不同的影響層級。三個位置會被同時掃描,描述符合的都能被 Claude 載入。
專案層級
路徑:.claude/skills/<name>/SKILL.md
把 skill 放在專案根目錄底下,會跟著 git 一起被版本控制,團隊成員 clone 下來就能用。最適合放跟程式碼風格、發佈流程、PR 規範相關的工作流,讓所有 contributor 共用同一份規則,PR review 也能看到 skill 的改動。
個人層級
路徑:~/.claude/skills/<name>/SKILL.md
放在使用者家目錄底下,跨所有專案都能用,不會被任何 git 倉庫追蹤到。適合個人慣用的工具型工作流,例如「把 docx 轉成 markdown」「整理筆記檔案」「批次重新命名圖檔」這類跟特定專案無關的能力。
Plugin
透過 Claude Code 的 plugin 系統發佈,安裝後 plugin 內附的 skill 也會被自動掃描。適合想分享給其他開發者,或是組織內部的標準工作流——把多個相關 skill 打包成 plugin,新成員裝一次就能拿到整套規範。
Skill 的格式
知道要把 skill 放在哪之後,下一步就是把資料夾內容寫好。一個 skill 至少需要一份 SKILL.md,視需求可以加上額外的腳本或範本檔案。
為什麼是資料夾,而不是單一檔案
這是很多人初學 skill 時會問的問題:既然只有 SKILL.md 是必要的,為什麼不直接讓 skill 是一個檔案就好?答案是大多數實用的 skill 不只需要指令文字,還需要附帶資源。資料夾把 skill 自成一個獨立單元,搬移、分享、版本控制都方便許多。
資料夾內除了 SKILL.md,常見會放的東西有:
- 腳本(scripts/):skill 流程中需要執行的 shell、Python、Node 腳本。例如 docx 轉檔 skill 會放一段 Python 來抽取內嵌圖片,
SKILL.md只負責「告訴 Claude 什麼時候要呼叫它」。 - 範本(templates/):標準格式的範本檔案,例如 PR 描述模板、release notes 模板、報告 markdown 骨架。Claude 會依範本填入內容,產出格式統一。
- 參考文件(reference/、docs/):較長的領域知識、規範條目、範例集。例如法律分析 skill 可能附一份「常見不平等條款的範例庫」,Claude 在比對合約時會載入這份做依據。
- 樣本資料(samples/、examples/):給 Claude 看的輸入輸出範例,幫助 skill 在邊界情境也能保持風格一致。寫前端設計 skill 時放幾個 component 範例,效果通常比再寫一段「請參考某某風格」好很多。
- 子指令(sub-skills/、prompts/):對於非常複雜的 skill,可以把流程分階段寫成多份 markdown,
SKILL.md當入口、再依情境呼叫對應的子檔案,避免單一檔案過長造成 Claude 抓重點失焦。
另一個資料夾化的好處是方便整包分享:把資料夾打包成 zip、放上 GitHub、或用 Claude Code plugin 系統發佈,使用者拿到就能直接 drop 進 .claude/skills/ 使用,不需要再去湊腳本與範本。對於團隊內部要散播一套標準工作流的場景特別好用。
資料夾結構
每個 skill 是一個獨立的資料夾,名稱就是 skill 的識別名(會跟 frontmatter 的 name 對齊)。資料夾內可以放任何 skill 用得到的檔案:
.claude/skills/secret-check/
├── SKILL.md # 必要:指令本體與 frontmatter
├── scripts/ # 可選:skill 內要呼叫的腳本
│ └── scan.sh
└── templates/ # 可選:skill 用到的範本檔案
└── report.md實際只有 SKILL.md 是必要的,其他子目錄全部是視需要才加。簡單的 skill 通常只需要一份 SKILL.md;複雜的 skill 才會搭腳本(例如要跑一段 Python 解析檔案)或範本(例如生成標準格式的報告)。在 SKILL.md 的指令裡要呼叫這些檔案,用相對路徑寫即可,例如「執行 scripts/scan.sh」「以 templates/report.md 為基礎填入內容」。
SKILL.md 的 frontmatter
檔案的開頭是 YAML frontmatter,用三個橫線包起來,跟一般 Markdown 部落格文章的 frontmatter 寫法一樣。最關鍵的兩個欄位是:
| 欄位 | 用途 | 是否必要 |
|---|---|---|
name | skill 的識別名稱,也對應到 slash command(/<name>) | 必要 |
description | 告訴 Claude「在什麼情境要載入這個 skill」,自動匹配的關鍵 | 必要 |
name 建議用 kebab-case(小寫加連字號),跟資料夾名一致比較好維護。description 寫得越精準,Claude 越能正確判斷時機,後面有專門一節討論這件事。除了這兩個欄位,部分版本的 Claude Code 還支援 allowed-tools 等進階設定,限制 skill 啟用時可以使用哪些工具,需要的話可以再加。
SKILL.md 的指令本體
frontmatter 之後就是 Markdown 寫的指令本體,這部分沒有固定格式,但結構越清楚 Claude 越容易跟著走。實務上常見的寫法是:
---
name: release-checklist
description: 發佈新版本前的檢查清單,逐項確認 changelog、測試、版號、tag 都到位
---
# Release Checklist
## 觸發時機
當使用者表達要「發佈版本」「跑 release」「上線新版」等意圖時。
## 步驟
1. 確認 `git status` 乾淨,沒有未提交的改動。
2. 跑 `npm test`,所有測試必須通過。
3. 檢查 `CHANGELOG.md` 是否更新到本次版本。
4. ⋯⋯
## 注意事項
- 任何步驟失敗時立即停止,回報錯誤訊息給使用者。
- 不要自動修改 git tag,等使用者確認後才執行。三個段落其實對應三個問題:什麼時候用(觸發時機)、怎麼做(步驟)、注意什麼(限制與規避)。Claude 在執行時會把這份 SKILL.md 整個讀進 context 當作 system 指令,所以該寫的細節都要寫清楚——尤其是條件分支、錯誤處理、與「什麼時候要停下來問人類」這種設計上的限制,越清楚越能避免 skill 被執行得跟原意有出入。
三層載入機制與 token 成本
知道 skill 的資料夾與 SKILL.md 怎麼寫之後,就比較容易理解它載入的細節。Skills 之所以可以在身上掛幾十個都不爆 context,關鍵在於分層、漸進式的載入機制,每個 skill 的內容會被切成三層,依使用情境決定要不要進到 context:
| 層級 | 內容 | 什麼時候載入 | 大概的 token 量 |
|---|---|---|---|
| 第 1 層 | SKILL.md 的 frontmatter(name 與 description) | Claude Code 啟動時就載入 | 每個 skill 約 30–80 tokens |
| 第 2 層 | SKILL.md 的指令本體 | Claude 判斷該 skill 跟當下任務相關才載入 | 典型 300–2000 tokens |
| 第 3 層 | 資料夾內的腳本、範本、參考文件等附帶檔案 | SKILL.md 指令明確要求 Claude 去讀時才載入 | 視檔案大小 |
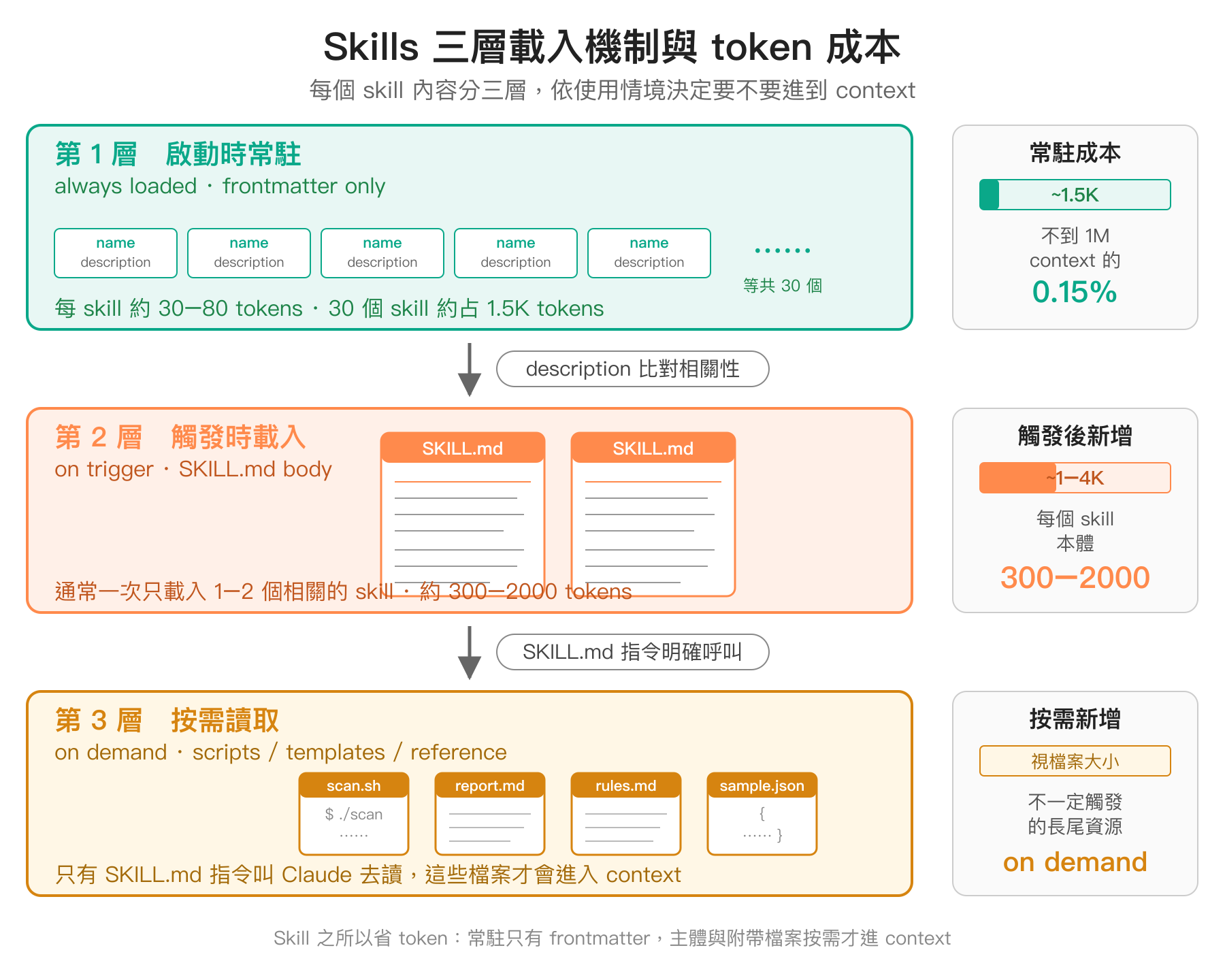
Claude 用什麼判斷要不要載入第 2 層?答案就是第 1 層的 frontmatter。Claude 會把所有 skill 的 description 跟使用者當下的意圖做語意比對,覺得相關的才把對應的 SKILL.md 主體拉進來。這也是為什麼description 寫得精準與否會直接決定 skill 有沒有被正確觸發——它不只是描述文字,更是自動匹配的判斷依據。
實務上的成本估算大概是這樣:假設身上有 30 個 skill,平均 description 寫 50 tokens,常駐占用約 1500 tokens(不到 1M context 的 0.15%);其中 1–2 個被觸發載入主體,再加 1000–4000 tokens;如果其中一個 skill 又呼叫了腳本檔案,再多幾百 tokens。整體來說,skill 累積到幾十個都還很安全,不會像把所有規則塞進 CLAUDE.md 那樣造成初始 context 直接膨脹幾萬 tokens。
反過來這也提醒一件事:SKILL.md 主體不要寫得太長。一旦被觸發就會整份進到 context,太冗長的 skill 反而會在實際工作時佔走可貴的 token 預算。複雜場景比較好的做法是在 SKILL.md 寫骨架與決策邏輯,把詳細步驟、長範本拆到第 3 層的附帶檔案,讓 Claude 視需要才讀。
怎麼觸發
Skill 有兩種觸發方式:自動匹配與 slash command。
自動匹配是 Claude 根據對話內容,把使用者意圖跟所有 skill 的 description 比對,自動決定要不要載入。例如 description 寫「依照可獨立執行的功能區塊進行 git commit」的 skill,當使用者說「幫我提交這些改動」時就會被自動拉進來。這個機制的好處是不需要記住 skill 名稱,缺點是描述寫得不夠好就可能漏觸發。
Slash command 是手動指定,用 /skill-name 直接呼叫對應的 skill。例如把上面那個 skill 取名 commit-helper,輸入 /commit-helper 就能強制載入。在 description 不夠精準、或想跳過自動判斷直接執行時很好用,類似把 skill 當成 alias。
實作一個小範例
以一個很常用的場景示範:每次 commit 前希望 Claude 先檢查改動有沒有混到 secret(API key、密碼等),順手提醒。先建立資料夾與檔案:
mkdir -p .claude/skills/secret-check
touch .claude/skills/secret-check/SKILL.md接著在 SKILL.md 裡寫指令:
---
name: secret-check
description: 在 git commit 前掃描 staged 改動,找出可能的 secret(如 API key、token、密碼),提醒使用者不要把敏感資料 commit 進倉庫
---
# Secret Check
當使用者要 commit 改動時:
1. 用 `git diff --cached` 取得 staged 內容。
2. 掃描以下高風險 pattern:
- `api[_-]?key`、`secret`、`token`、`password` 後接等號或冒號
- 長度超過 32 的 base64 字串
- AWS access key 格式(`AKIA[0-9A-Z]{16}`)
- 看起來像 JWT 的字串(以 `eyJ` 開頭)
3. 找到任何疑似 secret,立刻停止 commit,列出檔名與行號請使用者確認。
4. 沒找到才繼續正常 commit 流程。
注意:誤判時也要明確標示這是 pattern 比對的結果,最終由使用者判斷。存檔後重新進入 Claude Code,下次說「幫我把這些改動 commit 上去」時,這個 skill 就會被自動載入並執行。如果想強制呼叫,輸入 /secret-check 也可以。
如何寫好 Skill
有了格式跟範例之後,下一個問題就是怎麼把 skill 寫得真的好用。實務上發現兩件事最影響 skill 的品質:description 是否精準,以及 skill 內容是否真的反映實戰流程。
寫好 description 的關鍵
一個 skill 用得好不好,九成取決於 description 寫得夠不夠精準。Claude 會把 description 跟使用者意圖做語意比對,所以幾個原則:
- 包含具體動作:寫「在 commit 前掃描 secret」比寫「保護隱私」精準很多。
- 列出觸發場景:如果這個 skill 只在特定情境用,明確寫出來,例如「處理 docx 檔案時」「在 monorepo 內」。
- 避免過度泛用:description 寫成「幫助開發」這種太廣的措辭,會在每次對話都被誤觸發,反而吃 token。
實務上修改 description 後可以實測幾種對話方式,看 skill 有沒有正確被載入;觀察一陣子再迭代,比一次想到位更實際。
讓 AI 幫忙寫 Skill
Skill 不一定要從零自己寫——其實讓 Claude 自己把剛走過的工作流整理成 skill 是更高效的做法。流程大致是:先用對話的方式帶 Claude 把整件事走一遍,過程中遇到坑、繞過的彎路、最後可行的順序都實際被記錄在對話裡,然後直接請 Claude「把剛才的經驗整理成一個 skill」。產出的 skill 通常會比一開始空想寫的版本更貼近實戰,因為已經把踩過的雷都消化進去。
本站之前 MarkItDown 教學 那篇文章末尾的 docx-to-markdown skill 就是這樣產生的。實際把幾份含圖片的 Word 檔轉 Markdown 之後,發現 placeholder 替換、rels 解析、emf/wmf 圖片處理等等坑,再請 Claude 把整套流程連同注意事項寫成 skill。後來再丟新的 docx 進來,Claude 就會直接走完整流程,不會重新踩同一輪雷。
幾個讓 AI 寫 skill 寫得好的小訣竅:
- 等流程跑完再寫:不要一開始就請 Claude 想 skill,先把實際工作做完,遇到的問題自然會反映在最後的 skill 裡。
- 明確指定 description 風格:請 Claude 寫 skill 時順便提醒「description 要包含具體觸發場景」,避免 AI 寫出過度籠統的描述。
- 把踩過的雷加進「注意事項」:剛才對話裡面對 Claude 解釋過「這個地方要小心」「那個工具的某個 flag 不要用」,提醒它把這些一起寫進 skill 的 注意事項段落,下次才不會重蹈覆轍。
- 產出後人類稍微 review 一下:AI 寫的 skill 偶爾會把不必要的細節也寫進去,自己看一下、剪掉冗餘段落,會讓 skill 在被載入時更精煉。
用這種「先做、再請 AI 寫」的方式累積 skill,幾週下來就會在 ~/.claude/skills/ 底下慢慢長出一整套個人化的工作流工具箱,而且每一個 skill 都來自真正解決過的問題,沒有空想成份。
小結
Skills 是 Claude Code 在「擴充 vs context 成本」之間找到的平衡點:寫法比 MCP server 簡單,乾淨度比 CLAUDE.md 好,被觸發前完全不耗 token,被觸發時又能注入完整指令。對於有重複工作流的開發者來說,把這些流程寫成 skill 可以省下大量重複交代的時間。先從一兩個最常用的開始累積,再慢慢長成個人化工具箱即可。