
Anthropic 在 2026 年 6 月 30 日推出 Claude Sonnet 5,接替 Sonnet 4.6 成為 Claude 產品線的中階模型。官方定位是「性能接近 Opus 4.8,但價格維持在 Sonnet 級距」,並且在 8 月 31 日前提供 $2/$10 的優惠價(正式價 $3/$15),比 Sonnet 4.6 的 $3/$15 還便宜。
Sonnet 5 已經成為 claude.ai Free 與 Pro 方案的預設模型,Max、Team、Enterprise 也同步可用。對 API 開發者來說,模型 ID 是 claude-sonnet-5,Amazon Bedrock、Google Vertex AI 也在同一天上架。
這篇整理 Sonnet 5 跟 Sonnet 4.6 的差異、與 Opus 4.8 和其他模型的定價與 benchmark 對照、安全性改進,以及各平台的使用方式。
快速比較
與 Sonnet 4.6 的差異
| 項目 | Sonnet 4.6 | Sonnet 5 |
|---|---|---|
| 模型 ID | claude-sonnet-4-6 | claude-sonnet-5 |
| Input 價格 | $3 / 1M tokens | $3(優惠期 $2) |
| Output 價格 | $15 / 1M tokens | $15(優惠期 $10) |
| Context window | 1M tokens | 1M tokens |
| Max output(同步 API) | 128K tokens | 128K tokens |
| Max output(Batch API beta) | 300K tokens | 300K tokens |
| Adaptive thinking | 有 | 有 |
| Extended thinking | 有 | 無 |
| Effort 預設值 | — | API 與 Claude Code 預設 high |
| Tokenizer | 舊版 | 新版(同 Opus 4.7 起) |
| 知識截止 | 2026-01 | 2026-01 |
| 延遲 | Fast | Fast |
比較明顯的變化:Context window 從 Sonnet 4.5 時代的 200K 一路升到 4.6 的 1M,Sonnet 5 維持 1M 不變。Max output 從 Sonnet 4.5 的 64K 升到 128K,追平了 Opus 4.8。Tokenizer 換成新版(同 Opus 4.7 起),token 數會增加約 30%,詳見下方 Tokenizer 章節。
Extended thinking 在 Sonnet 5 上已經移除,改為 Adaptive thinking(跟 Opus 4.7、4.8 一樣)。如果既有的工作流有依賴 Sonnet 4.6 的 extended thinking 行為,升級前要確認一下。
Claude 完整產品線價格對照
把目前在線的所有 Claude 模型放在一起,比較容易看出 Sonnet 5 的定位。單價都是每 1M tokens 美元:
| 模型 | Input | Output | Context | Max output | 定位 |
|---|---|---|---|---|---|
| Fable 5 | $10 | $50 | 1M | 128K | 頂級旗艦,極限推理與長任務 agent |
| Opus 4.8(Fast Mode) | $10 | $50 | 1M | 128K | Opus 2.5× 速度,延遲敏感場景 |
| Opus 4.8 | $5 | $25 | 1M | 128K | 複雜推理與長任務 agent |
| Sonnet 5(正式價) | $3 | $15 | 1M | 128K | 速度與智能平衡,日常 agent 任務 |
| Sonnet 5(優惠價至 8/31) | $2 | $10 | 1M | 128K | 同上,限時優惠 |
| Haiku 4.5 | $1 | $5 | 200K | 64K | 最快、成本敏感場景 |
Sonnet 5 正式價跟 Sonnet 4.6 完全一樣($3/$15),等於免費升級。8 月底前的優惠價 $2/$10 則比 Sonnet 4.6 便宜了 33%,對想趁便宜大量跑 agent 任務的開發者來說是個不錯的時間窗口。
跟 Opus 4.8 比,Sonnet 5 的 input 便宜 40%($3 vs $5)、output 便宜 40%($15 vs $25)。如果任務不需要 Opus 級的深度推理,Sonnet 5 能省下可觀的費用,尤其是大量跑 agent 時。
與 OpenAI、Google 對照
| 模型 | Input | Output | Context | 長 context 加價 |
|---|---|---|---|---|
| Claude Sonnet 5(優惠價) | $2 | $10 | 1M | 無,全段同費率 |
| Claude Sonnet 5(正式價) | $3 | $15 | 1M | 無,全段同費率 |
| Claude Opus 4.8 | $5 | $25 | 1M | 無,全段同費率 |
| OpenAI GPT-5.5 | $5 | $30 | 1M | > 272K 全段 2× input / 1.5× output |
| Google Gemini 3.1 Pro | $2 | $12 | 1M | > 200K 改 $4 / $18 |
Sonnet 5 優惠價($2/$10)與 Gemini 3.1 Pro 的基礎價幾乎打平,而且 Anthropic 全段同費率沒有長 context 跳階。正式價 $3/$15 則比 GPT-5.5 的 $5/$30 便宜不少。如果 Sonnet 5 的能力夠用,在成本上已經沒有太多理由去選 GPT-5.5 了,除非工作流綁定 OpenAI 生態系。長 context 的計費差異在之前的 Opus 4.8 整理 裡有圖解比較。
核心改進:Agent 能力大幅提升
Anthropic 在公告中把 Sonnet 5 定位為「the most agentic Sonnet model yet」。核心訴求是:幾個月前需要 Opus 等級才跑得起來的 agent 任務,Sonnet 5 也能處理了。
具體改進包括:
- 自主規劃與工具使用:能自己擬定計畫、操作瀏覽器和終端機,並且自主執行多步驟任務到完成。過去 Sonnet 4.6 常在複雜任務中途「做到一半就停下來」的狀況,Sonnet 5 明顯改善
- 自我檢查:不需要額外提示就會主動檢查自己的產出,這點跟 Opus 4.8 強調的「誠實度」改進方向一致
- coding 與推理能力:在程式碼生成、工具呼叫、知識工作等項目上都比 Sonnet 4.6 有明顯進步,部分項目已經接近 Opus 4.8 的水準
Zapier 的 Daniel Shepard 在 Anthropic 公告中的回饋是:「That used to stall halfway. For day-to-day automation, it’s a no-brainer.」——過去跑到一半會卡住的自動化任務,現在能完整跑完了。
Benchmark 表現
把 Sonnet 5 跟前一代 Sonnet 4.6、旗艦 Opus 4.8 的官方 benchmark 放在一起看。SWE-bench Pro 是 agentic coding、HLE 是跨學科推理、OSWorld-Verified 是電腦桌面操作。百分比越高越好:
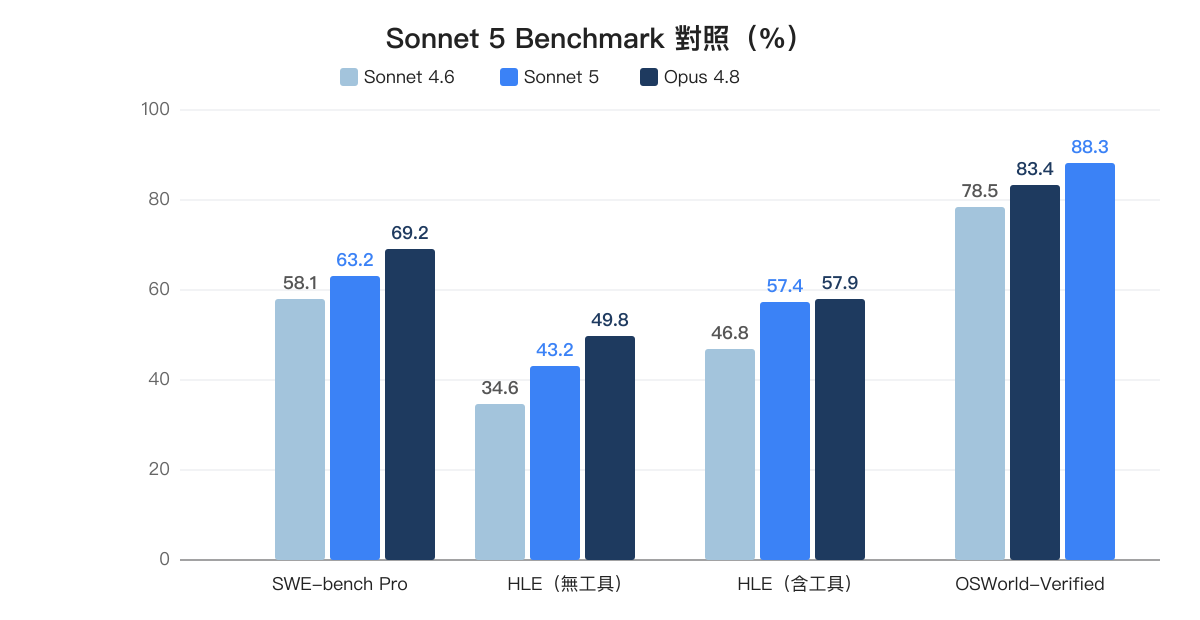
| Benchmark | Sonnet 5 | Sonnet 4.6 | Opus 4.8 | 評測說明 |
|---|---|---|---|---|
| Agentic coding(SWE-bench Pro) | 63.2% | 58.1% | 69.2% | 解真實 GitHub 專案任務,改完要通過測試 |
| HLE(無工具) | 43.2% | 34.6% | 49.8% | 跨學科高難度學術題,純推理 |
| HLE(含工具) | 57.4% | 46.8% | 57.9% | 同上,但可用搜尋與程式執行 |
| OSWorld-Verified | 88.3% | 78.5% | 83.4% | 操作真實電腦桌面完成任務 |
Sonnet 5 在多數項目上介於 Sonnet 4.6 和 Opus 4.8 之間,但 OSWorld-Verified 的 88.3% 直接超過了 Opus 4.8 的 83.4%,代表 Sonnet 5 在電腦桌面操作這個維度上已經領先旗艦。SWE-bench Pro 從 Sonnet 4.6 的 58.1% 拉到 63.2%,進步了 5 個百分點,但離 Opus 4.8 的 69.2% 還有一段距離。
HLE 含工具的 57.4% 跟 Opus 4.8 的 57.9% 幾乎打平(差距不到 1 個百分點),代表 Sonnet 5 的跨學科推理能力已經逼近旗艦水準。不過 HLE 無工具的差距還有 6.6 個百分點(43.2% vs 49.8%),對純推理場景 Opus 4.8 仍有優勢。
換個角度看:Sonnet 5 的 SWE-bench Pro 63.2% 已經接近 Opus 4.7 時代的 64.3%,等於開發者用 Sonnet 的價格就能拿到接近一兩個月前 Opus 等級的 coding 能力。這對預算有限但需要跑 agent 的團隊來說是好消息。
安全性改進
Anthropic 在安全性上做了幾個明確的改善:
- 幻覺與附和率降低:比 Sonnet 4.6 更少捏造事實,也更少無條件同意使用者的說法
- 惡意請求拒絕:對明顯有害的指令拒絕率提升
- Prompt injection 防禦:在 agent 場景中對 prompt 注入攻擊的抵抗力更強,這對把模型接進自動化工作流的開發者來說很重要
- 網路安全限制:Sonnet 5 在漏洞利用測試中的成功率為 0%(Firefox 漏洞測試),代表它在危險的網路攻擊能力上被刻意限制,比 Opus 4.8 的限制更嚴格
Lovable 的 Fabian Hedin 在公告中的評語是:「A model that knows when to say no is just as important as one that knows how to build.」——對產品導向的團隊來說,模型會拒絕危險操作跟模型會寫 code 一樣重要。
優惠價格的時間窗口
Sonnet 5 的定價有兩個階段:
| 時期 | Input | Output | 與 Sonnet 4.6 比較 |
|---|---|---|---|
| 2026/06/30 – 2026/08/31(優惠價) | $2 / 1M tokens | $10 / 1M tokens | 便宜 33% |
| 2026/09/01 起(正式價) | $3 / 1M tokens | $15 / 1M tokens | 相同 |
Prompt caching 命中省 90%、Batch API 非即時省 50% 在 Sonnet 5 上繼續支援。優惠價期間疊 cache 的實際成本會非常低——input $2 打一折只要 $0.2/1M tokens,對需要大量反覆讀取 system prompt 或長文件的工作流來說,成本可以壓得很低。Prompt caching 的運作方式可以參考之前寫的 Token 省錢與 Cache 指南。
Tokenizer 變更的影響
Sonnet 5 使用的是 Opus 4.7 開始導入的新版 tokenizer,同一段文字大約會產出比舊版多 30% 的 tokens。這意味著從 Sonnet 4.6 切換過來時,即使 prompt 內容完全沒變,token 數也會增加。
在正式價 $3/$15 下,多出的 30% tokens 會讓實際帳單比 Sonnet 4.6 貴一些。但在優惠價 $2/$10 期間,即使 token 數多 30%,$2 × 1.3 = $2.6 仍低於 Sonnet 4.6 的 $3。所以優惠期間不管怎麼算都是划算的。
9 月之後就要看使用場景了。如果 prompt 以英文為主,tokenizer 的影響大約在 15–25% 之間;中文或多語言混合的情境可能接近或超過 30%。估算成本時建議先用 Anthropic 的 pricing 頁面 實際跑一次 token 計數。
各平台使用方式
claude.ai 與手機 App
Sonnet 5 已經是 Free 和 Pro 方案的預設模型,打開 claude.ai 或手機 App 就會直接用到,不需要手動切換。模型選單裡也可以看到 Sonnet 5 的選項。
Claude Code
Claude Code 更新到最新版本後即可使用 Sonnet 5:
# 更新 Claude Code
claude update
# 確認版本
claude --version
# 切換模型(如果不是預設)
# 在 Claude Code 裡輸入
/model claude-sonnet-5Sonnet 5 在 Claude Code 裡的 effort 預設值是 high,跟 Opus 4.8 一樣。如果需要調整,用 /effort 指令即可。想了解 Claude Code 更多用法,可以參考之前寫的 Claude Code 入門使用教學 和 Claude Code 切換模型指南。
API 與雲端平台
- Claude API:
model欄位設成claude-sonnet-5。Effort 預設high - Amazon Bedrock:透過 Claude in Amazon Bedrock 使用
anthropic.claude-sonnet-5 - Google Vertex AI:model ID 為
claude-sonnet-5
Sonnet 4.6 目前仍可使用 claude-sonnet-4-6,沒有立刻下架。但如果沒有特殊理由繼續用 Sonnet 4.6,切到 Sonnet 5 在能力和成本上都是嚴格升級——特別是優惠價期間。
該選 Sonnet 5 還是 Opus 4.8
Sonnet 5 的出現讓 Claude 產品線的選擇變得更微妙。簡單的判斷方式:
- 大量跑 agent、對成本敏感:Sonnet 5 是更合理的選擇,特別是 8 月底前的優惠價期間。日常自動化、CI 內的 code review、客服機器人這類場景,Sonnet 5 的能力夠用,省下來的錢可以跑更多次
- 複雜推理、長時間 agent、codebase 級遷移:Opus 4.8 仍是更穩的選擇。HLE 含工具的差距(46.8% vs 57.9%)代表 Opus 4.8 在最難的推理任務上仍有明確優勢,加上 Dynamic Workflows 能平行跑數百個 subagent,大型遷移任務目前還是適合 Opus
- 需要頂級能力且預算不是問題:Fable 5($10/$50)在 benchmark 上進一步領先 Opus 4.8,在 benchmark 上進一步領先 Opus 4.8,適合對品質有極高要求的場景
- 速度優先、token 用量極大:Haiku 4.5($1/$5)仍是成本控制的終極選項,但 context 只有 200K、max output 只有 64K
一個實用的策略是把 Sonnet 5 當作預設、需要深度推理時再切 Opus 4.8。Claude Code 裡可以用 /model 隨時切換,API 端也可以根據任務複雜度動態選模型。以前 Sonnet 和 Opus 之間的能力鴻溝比較大,很多任務只有 Opus 跑得起來;現在 Sonnet 5 把這個差距縮小了,更多任務可以用比較便宜的模型完成。
參考資料
- Introducing Claude Sonnet 5 — Anthropic 官方公告,含 agent 能力說明、安全性評估、客戶回饋
- Models overview — Claude Platform Docs — 所有 Claude 模型的 ID、context window、max output、pricing 與 effort 預設值
- Anthropic launches Claude Sonnet 5 as a cheaper way to run agents — TechCrunch
- Claude Opus 4.8 發表整理 — 之前寫的 Opus 4.8 介紹,含與競品的詳細價格圖解
- Anthropic 與 Claude 模型入門指南 — Claude 產品線完整演進史