
2026 年 4 月 23 日,Anthropic 在官方部落格上把 Claude Code 這兩個月來的「變笨」事件(社群常稱為「降智」)寫成一份 post-mortem 公開。過去幾週在 X、Reddit、GitHub 上幾乎天天都有人抱怨:同樣的指令以前 Claude Code 一次就能做好,現在常常漏讀檔案、忘記剛才做過什麼、或直接把額度噴光。Anthropic 一開始的態度是「API 與模型本身沒動過」,但最後還是承認——確實是 Claude Code 這一層出了問題,而且不是一個 bug,是三個獨立 bug 疊加。
這篇文章整理三個 bug 各是什麼、Anthropic 為什麼從否認轉向承認、公開同日發下去的補償方式,以及他們承諾後續要做的改善措施。這次事件跟 4 月初的 Claude Code 原始碼意外洩漏 事件時間上很接近,但是兩回事——洩漏事件揭露的是 autocompact bug,這次 post-mortem 處理的是另外三個不同 bug。
三個 Bug 各是什麼
Anthropic 把整個事件的關鍵時間點整理出來,看得出來是三個獨立調整先後疊在一起,不是一次性的錯誤:

| 日期 | 事件 | 結果 |
|---|---|---|
| 2026-03-04 | Claude Code 預設 reasoning effort 從 high 調為 medium | Bug 1 開始影響 |
| 2026-03-26 | 引進一個 caching 優化 | Bug 2 開始影響 |
| 2026-04-02 | AMD AI 總監 Stella Laurenzo 在 GitHub 上公開附帶遙測資料的 issue | 輿論壓力升高 |
| 2026-04-07 | reasoning effort 回復 high | Bug 1 修復 |
| 2026-04-10 | caching 優化修掉 (v2.1.101) | Bug 2 修復 |
| 2026-04-16 | 新增 verbosity system prompt(限制字數) | Bug 3 開始影響 |
| 2026-04-20 | verbosity prompt 移除 (v2.1.116) | Bug 3 修復 |
| 2026-04-23 | 公布 post-mortem、重置所有訂閱者額度 | 事件收尾 |
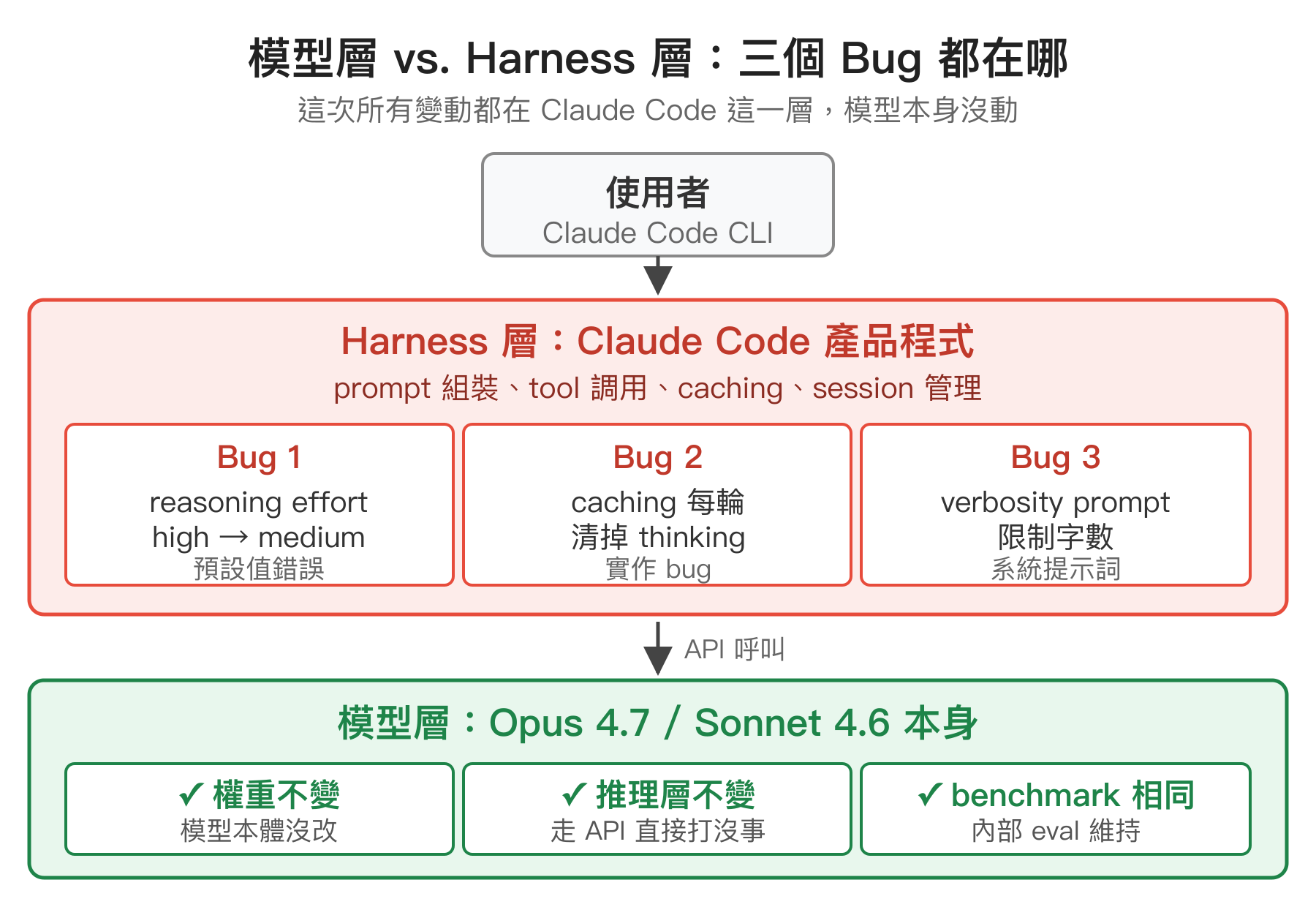
Bug 1:reasoning effort 被降級
3 月 4 日 Anthropic 把 Claude Code 的預設 reasoning effort 從 high 調降為 medium。背後的動機是降低「尾端延遲」——複雜任務偶爾會讓 Opus 思考一分鐘以上,UI 看起來像凍結了,團隊希望把這種感受降下來。內部評估當時認為這樣「只會稍微降低智能」,但實際跑出來使用者感受落差非常大。Anthropic 在 post-mortem 裡直接承認這是「錯誤的取捨」,4 月 7 日已經復原。
順便把新的預設寫清楚:Opus 4.7 現在預設是 xhigh、其他模型預設是 high。換句話說就算這次沒踩到坑的使用者,現在也等於吃到預設強度的升級,推理任務會比事件前更願意多花時間深思。
Bug 2:caching 優化清掉了 thinking 記憶
這個 bug 大概是三個裡面最難察覺、也最傷的。Claude Code 有一個叫 clear_thinking_20251015 的 header,搭配 keep:1 參數,原本的設計是「如果對話閒置超過 1 小時才是 stale session,觸發一次清理就好」,用來節省長期閒置 session 的快取空間。但實作出問題,條件判斷沒有「只在 stale 時執行」,變成 session 開始之後每一輪 turn 都清一次。
清掉的是模型的 thinking blocks(思考區塊)——那是 reasoning model 在生成最終回覆前的推理步驟。當 thinking 每一輪都被清掉,Claude 仍然會繼續呼叫工具、繼續回應,但「為什麼上一步要這樣做」的脈絡逐漸消失。使用者體感就是:AI 該讀的檔案沒讀、該檢查的東西沒檢查、同一件事問它兩次得到不一致的答案。4 月 10 日發布的 v2.1.101 把這個 bug 修掉。
Bug 3:verbosity 系統提示詞把 coding 分數壓低 3%
4 月 16 日 Anthropic 想解決另一個問題:Opus 4.7 在 Claude Code 裡容易囉嗦,動不動就寫一大段「我現在要做 X」的解釋,token 也因此變貴。他們加了一段系統提示詞:
Length limits: keep text between tool calls to ≤25 words.
Keep final responses to ≤100 words unless the task requires more detail.看起來是合理的節流指令,但實測跑內部 coding benchmark 時,Opus 4.6 跟 4.7 都掉了大約 3%。Anthropic 的解讀是:字數限制壓抑了模型寫出中間推理、列出 assumption 的空間,而這些看似冗餘的文字其實在 coding 任務裡幫助模型保持一致性。題外話,這個現象跟我們在 Google AI Studio 免費跑 Gemma 4 那篇觀察到的 Gemma preamble 效應有點像——模型的「想出聲」不是噪音,是它維持思緒的手段,硬壓下去就會付出代價。4 月 20 日 v2.1.116 把這段 prompt 拿掉。
Anthropic 為什麼這次願意承認
Anthropic 過去對「模型變笨」這類抱怨長期是否認態度,給的標準回應是「我們從來沒有故意降級模型,而且 API 跟推理層面都沒有被更動過」。這次會轉向,最大的推力不是一般使用者的抱怨,而是 AMD AI 總監 Stella Laurenzo 在 4 月 2 日公開的一份遙測分析。
Laurenzo 分析了 6,852 個 session 檔案、共 234,760 次 tool call、17,871 個 thinking block,抓出兩個很難反駁的數字:
- 編輯檔案前先讀過的次數從平均 6.6 降到 2.0(Claude 變懶、假設代替查證)
- 可見的 thinking 長度中位數從大約 2,200 字元塌到 600 字元(模型在想的越來越少)
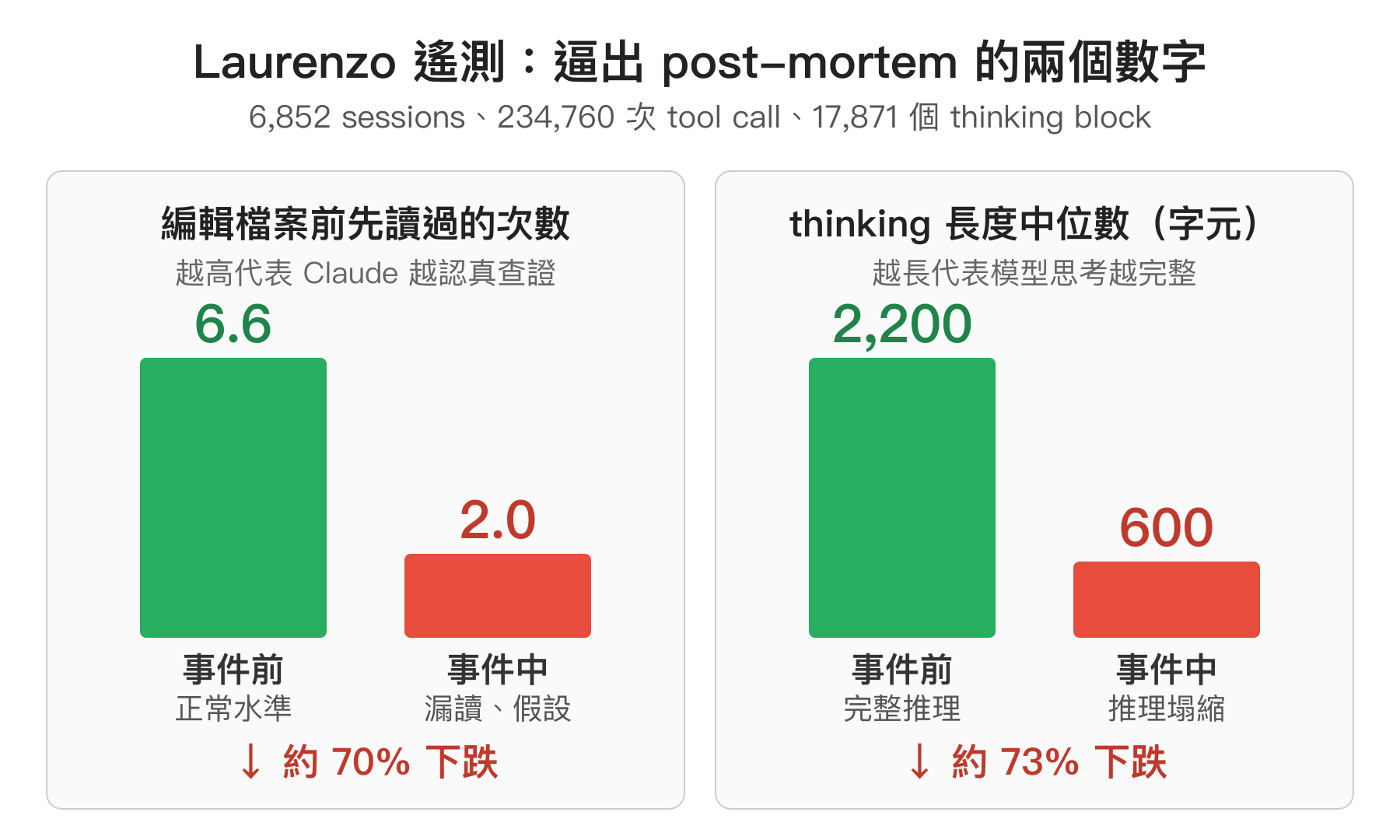
這兩個數字是工程師最熟悉的那種「數據擺在你面前」的證據,不是感受也不是樣本偏差,Anthropic 很難繼續只用「API 沒動」一句話擋掉。Claude Code 負責人 Boris Cherny 在 post-mortem 裡的原話是:
this has probably been the most complex investigation we’ve had … the root causes were not obvious, and there were many confounders.
這句話其實也是在幫自己緩頰——三個 bug 的時間分散、影響方式各不相同,單獨看任何一個都很難歸因。但是反過來說,一家做 frontier model 的公司在生產環境疊三個調整都沒跑完整的 regression test 就推出去,這件事本身就值得反省。
補償方式:全訂閱者額度重置
4 月 23 日與 post-mortem 同時生效的補償只有一個動作:所有 Claude 付費訂閱者當下的額度計數直接歸零。也就是說這個月原本已經用掉的額度不算,大家都從零開始跑到下一個帳單週期。簡單粗暴,但可能是最誠實的方案——因為 bug 期間誰消耗多誰消耗少很難追溯,直接清零對所有訂閱者都有好處。
補償沒有包含的東西也整理一下,避免讀者誤會:
- 沒有現金退款,也沒有延長訂閱期
- 沒有追加下個月的額度(只是「重置」,不是「加碼」)
- API 帳單沒有調整——這次事件只影響 Claude Code CLI 這一層,走 API 直接呼叫模型的開發者不在影響範圍內,自然也沒有退款
有一個插曲值得一提:4 月 21 日也就是事件收尾前兩天,Anthropic 做了一個小規模 A/B 測試,把 Claude Code 從 $20 Pro 方案裡拿掉,只有 Max 方案才能用。測試涵蓋大約 2% 的新註冊者,在社群炸鍋後不到一天就回滾了。這個時機選在使用者正在抱怨品質的當口,觀感非常糟,雖然只是測試但加深了外界對 Anthropic 溝通能力的負評。
個人經驗:時機沒對上,補償沒享受到
講一下自己的經驗。我的 weekly limit 原本就排在 4 月 24 日重置,Anthropic 4 月 23 日那次全體重置我幾乎沒感覺——因為隔一天我自己的週期也會歸零,收到的禮物其實只提早了大概一天。根據每個人訂閱的起算日不同,這次重置的實際價值落差很大,越接近原本重置日的人拿到的越少。
我是 Max $100 重度用戶,每天都會開好幾個小時、連假日也在跑——用途涵蓋程式規劃、實作、研究新專案的背景資料、把舊專案的架構讀一遍熟悉一下。整體用量不算輕,但這幾個月下來 session limit 跟 weekly limit 其實都沒有真的撞上過。一方面可能是運氣好剛好避開 bug 最嚴重的時段,另一方面也可能是即使沒有 bug、只要用得兇一點還是會碰到上限。後面有機會再寫一篇整理我自己控制 token 消耗的習慣跟幾個小技巧,這邊先按下不表。
不過「降智」這件事我的確感受到過。最明顯的症狀是 context 其實才用到一半,Claude Code 就開始忘記 CLAUDE.md 裡已經交代好的規則——像是事先講好的路徑慣例、特定流程要呼叫哪個指令之類的,明明還有很多上下文空間可用,但答案就是跳過了。這跟單純 context window 爆掉不一樣,是那種「規則還在視野內但模型就是沒拿出來用」的感覺。回頭看時間點也對得上,應該就是 Bug 2(caching 每輪清掉 thinking)在我 session 上的具體表現。
改善措施
Post-mortem 裡 Anthropic 承諾的後續改善主要有三項:
- Claude Code build 前多跑 regression test:針對工具調用、上下文保留、coding 品質三個面向,每次 release 前都要跑過才能推線上
- 系統提示詞要過 eval 才能上線:像這次 verbosity prompt 那種「看起來合理但會降品質」的微調,以後要先跑 coding benchmark 確認沒有 regression 才能部署
- 開新的 @ClaudeDevs X 帳號:用來發產品說明、回應使用者對變化的疑問,算是對「溝通不夠透明」這個批評的回應
這三項裡面,前兩項是工程層面的護欄,寫清楚了就可以檢驗。第三項比較虛——公司多開一個 X 帳號發文不難,但 post-mortem 本身能不能成為常態(下一次出問題幾週內就公開,而不是先否認一個月再承認)才是真正要看的指標。
這件事的一些觀察
結束前想講三個比較實用的觀察:
第一,「模型」跟「模型被包裝出來的產品」要分開看。這次三個 bug 都不在 Opus 或 Sonnet 模型本身,是 Claude Code 這一層的 prompt 設計與 caching 實作。使用 API 直接打模型的開發者從頭到尾沒感覺,受影響的只有走 Claude Code CLI 的使用者。這也說明了為什麼 Anthropic 一開始可以很堅決地說「模型沒動」——那句話在技術上是正確的,只是不是使用者想問的問題。未來看到類似爭議,區分「模型本身變動」跟「harness/product layer 變動」會更精準,這個觀點在 Harness Engineering|AI Agent 從提示詞工程、上下文工程演進的新顯學 那篇有更完整的討論。
第二,使用者遙測回報比感受回報有份量。這次能逼出 post-mortem 的不是 Reddit 上滿坑滿谷的「Claude Code 變笨了」發文,是 Laurenzo 把 session 檔案讀出來、做統計、畫圖的那份遙測分析。對第一線開發者的啟示是:遇到疑似品質下降,與其只在論壇抱怨,把自己的 session log 存下來做個時間序列比對會更有說服力,也能幫廠商更快定位問題。
第三,額度重置對本來就踩到 bug 的重度用戶是實際的好消息,但對只是輕度使用的人效果有限(本來就用不完)。如果這段時間有在 Max 方案跑批次任務、或是因為 caching bug 多噴了好幾倍 token 的重度開發者,建議打開 Claude Code 的 /cost 或儀表板看看,確認重置有生效,再順手把上次碰到上限的時間點記下來,有機會的話對照下個週期的消耗曲線,就能看出這次修正有沒有真的把 token 消耗拉回正常軌道。
參考資料:
- Anthropic Pins Claude Code Quality Drop on Three Changes (Implicator AI)
- Anthropic explains Claude Code’s recent performance decline after weeks of user backlash (Fortune)
- Mystery solved: Anthropic reveals changes to Claude’s harnesses and operating instructions likely caused degradation (VentureBeat)
- Anthropic admits it dumbed down Claude with ‘upgrades’ (The Register)