
Google DeepMind 在 2026 年 4 月 2 日發布 Gemma 4,這代開放權重模型一次推出四個規格:E2B、E4B、26B A4B 與 31B。本地跑 31B 至少要 RTX 4090 或 M4 Max 這類規格才合適,看到硬體需求大部分人就退縮了。好消息是 Google 把 Gemma 4 都放上 Google AI Studio,完全免費、不需要綁信用卡就可以透過 API 呼叫,額度夠日常實驗與小型應用使用。
這篇文章會先介紹 AI Studio 是什麼、怎麼註冊、怎麼拿 API key,接著用 Python 腳本實際呼叫 26B 與 31B 兩個模型,比較它們的速度與品質差異。然後整理在 RTX 顯示卡與 Mac 系列上要多少等級的硬體才能順暢跑這兩個模型、大概要多少錢,最後說明怎麼把 Gemma 4 接到 OpenClaw、opencode、Claude Code 這些 Agent CLI 上使用。如果對 Gemma 4 本身的能力還不熟悉,可以先看 Google Gemma 4 介紹 以及 Claude Code 搭配 Ollama Gemma 4 本地化 這兩篇。
Google AI Studio 是什麼
Google AI Studio 是 Google 給開發者測試 Gemini 與 Gemma 系列模型的官方網頁介面,網址是 https://aistudio.google.com。可以簡單理解成「Gemini 與 Gemma 的 Playground」,左邊選模型與調參數、右邊寫 prompt 看回覆,試好了之後點「Get API Key」就拿得到 API 金鑰,拿來在自己的程式裡呼叫同樣的模型。
AI Studio 跟另一個容易混淆的產品 Vertex AI 是兩套東西。Vertex AI 是 Google Cloud 底下的企業級 AI 平台,要開 GCP 專案、綁信用卡、走 Cloud IAM 那一整套;AI Studio 比較像是個人開發者用的輕量入口,用 Google 帳號登入就能用,API 走 generativelanguage.googleapis.com 這個網域。兩個其實都能呼叫 Gemini 模型,但計費規則、模型版本、頻寬額度、權限管理機制都不同,本文講的都是 AI Studio 這邊。
免費層的實際限制
AI Studio 的免費層並不是無限用到飽,Google 其實沒有在公開文件上列出 Gemma 4 的精確配額(只說「請到 AI Studio 看目前的限額」),我這邊透過連續壓測 API、觀察 429 錯誤裡面的 quota 細節,實際把數字拿出來對照整理。
| 項目 | 限制 | 備註 |
|---|---|---|
| 信用卡 | 不需要 | 只用 Google 帳號登入即可 |
| RPM(Requests Per Minute) | 15 | 429 回傳的 quotaId 是 GenerateRequestsPerMinutePerProjectPerModel-FreeTier,每個模型獨立計算,26B 與 31B 的配額不共用 |
| TPM(Tokens Per Minute) | 官方未公開 | burst 壓測 15 RPM 時只觸發 RPM quota,沒看到 TPM violation;Google 文件也沒列 Gemma 的 TPM,以實際 429 body 顯示的 quota 為準 |
| RPD(Requests Per Day) | 官方未公開 | Gemma 官方未公布,社群推估 Gemma 4 約 1,000–1,500;Gemini 2.5 Flash-Lite 同期是 1,000 |
| Context window(輸入) | 256K tokens | 模型 metadata 回傳 inputTokenLimit: 262144,實測丟約 120K tokens 的 prompt 仍能正常回覆 |
| 輸出長度上限 | 32K tokens | 模型 metadata 回傳 outputTokenLimit: 32768,需要更長輸出得分段呼叫 |
| 隱私 | 請求內容會被訓練 | 敏感資料請升級付費層或改用 Vertex AI |
上面這張表的數字是實際用 models.get API 抓模型 metadata、加上故意 burst 壓測觸發 429 之後,從錯誤 body 的 QuotaFailure 欄位確認出來的。Google 官方文件對 Gemma 的配額描述很模糊(只寫「請到 AI Studio 查看」),不想自己壓測的話可以到 aistudio.google.com/rate-limit 直接看目前帳號的 per-model 配額。
15 RPM 換算下來大概等於每 4 秒可以發一個請求。這個速度適合個人開發、批次腳本、hobby 專案;不適合多用戶同時使用的前端服務、高頻 polling、需要立即回應的互動應用。觸發 429 錯誤之後 API 會回傳 retryDelay 欄位告訴我們要等多久(實測在 16–53 秒之間),照著等就好。
另外 Google 這幾年對免費層節奏有兩次明顯收緊:2025-12 把各模型 RPM/RPD 砍了 50–80%;2026-04 再把 Gemini 3.1 Pro 這類高階模型完全移出免費層。Gemma 與 Flash 系列現在還在免費層,但長期來看不保證不會再變動,寫程式時不要把免費層當作永久無限資源。
取得 API Key
開啟 aistudio.google.com,用 Google 帳號登入,右上角點「Get API Key」或直接開 aistudio.google.com/apikey。第一次會要求建立一個 Project(預設叫 Default Gemini Project),建立後就可以點「Create API key」產生金鑰。金鑰格式是 AIza 開頭的字串,Billing tier 會顯示 Free tier,代表還在免費層。
拿到 key 之後,建議存到環境變數或 .env 檔,不要直接寫死在程式碼裡,避免不小心推上 GitHub:
# 專案目錄內建立 .env
echo 'GOOGLE_API_KEY=AIza...your_key_here' >> .env
# 把 .env 加進 .gitignore,避免跟程式碼一起推上去
echo '.env' >> .gitignore
# 載入到環境變數(bash/zsh)
source .env
export $(grep -v '^#' .env | xargs)AI Studio 網頁介面快速體驗
拿 API key 之前,可以先在 AI Studio 網頁上直接跟 Gemma 4 聊天。登入後左側 Model 選單選 Gemma 4 26B A4B IT 或 Gemma 4 31B IT,中間寫 prompt,右邊可以調 temperature、max output tokens、system instruction 等。試好的 prompt 可以點「Get Code」按鈕,AI Studio 會產生對應的 Python、curl、JavaScript 呼叫程式碼,把這份程式碼搬到自己的環境就能跑。
實務上這個網頁介面很適合調 prompt、測 system instruction、確認回覆格式,prompt 確定了之後再轉到 API 批次呼叫,流程順很多。
可用的 Gemma 4 模型 ID
呼叫 API 時要用精確的模型 ID,這是 2026 年 4 月 24 日用我的 key 實測列出的名單:
| 模型 ID | 顯示名稱 | 架構 | 建議用途 |
|---|---|---|---|
gemma-4-26b-a4b-it | Gemma 4 26B A4B IT | MoE,總 26B/活躍 3.8B | 速度與品質兼顧,首選 |
gemma-4-31b-it | Gemma 4 31B IT | Dense 31B | 難題、長推理 |
gemma-3n-e2b-it | Gemma 3n E2B | Edge 2B | 行動裝置或低延遲 |
gemma-3n-e4b-it | Gemma 3n E4B | Edge 4B | 行動裝置或低延遲 |
這邊也看得到 Gemma 3 舊版本還在提供,想做跨代比較的讀者可以一起測。
用 Dashboard 監控使用量
AI Studio 左側選單的「Usage & Billing」或直接開 aistudio.google.com/usage 可以看到目前 Project 的用量儀表板,分成 Overview(整體請求數、成功率、錯誤統計)與 Generate content & Live API(各模型細節)兩大區塊。寫自動化腳本跑批次任務時,習慣先看這個儀表板確認沒吃掉太多配額,比看 429 錯誤才發現超支直覺很多。
這個儀表板支援 Last Hour/Last 24 Hours/Last 28 Days 等時間區間,寫長期批次任務時特別實用。另外切到「Quotas & system limits」還能看到各個 quota 當前的用量與上限數字,想確認 15 RPM 有沒有被打滿就是看這邊。
Python 實際應用範例
AI Studio 的 REST API 直接打就好,不一定要安裝 SDK,用 Python 內建的 requests 就能跑。以下範例全部都是我在寫這篇文章時實際跑的結果,輸入輸出一字未改。
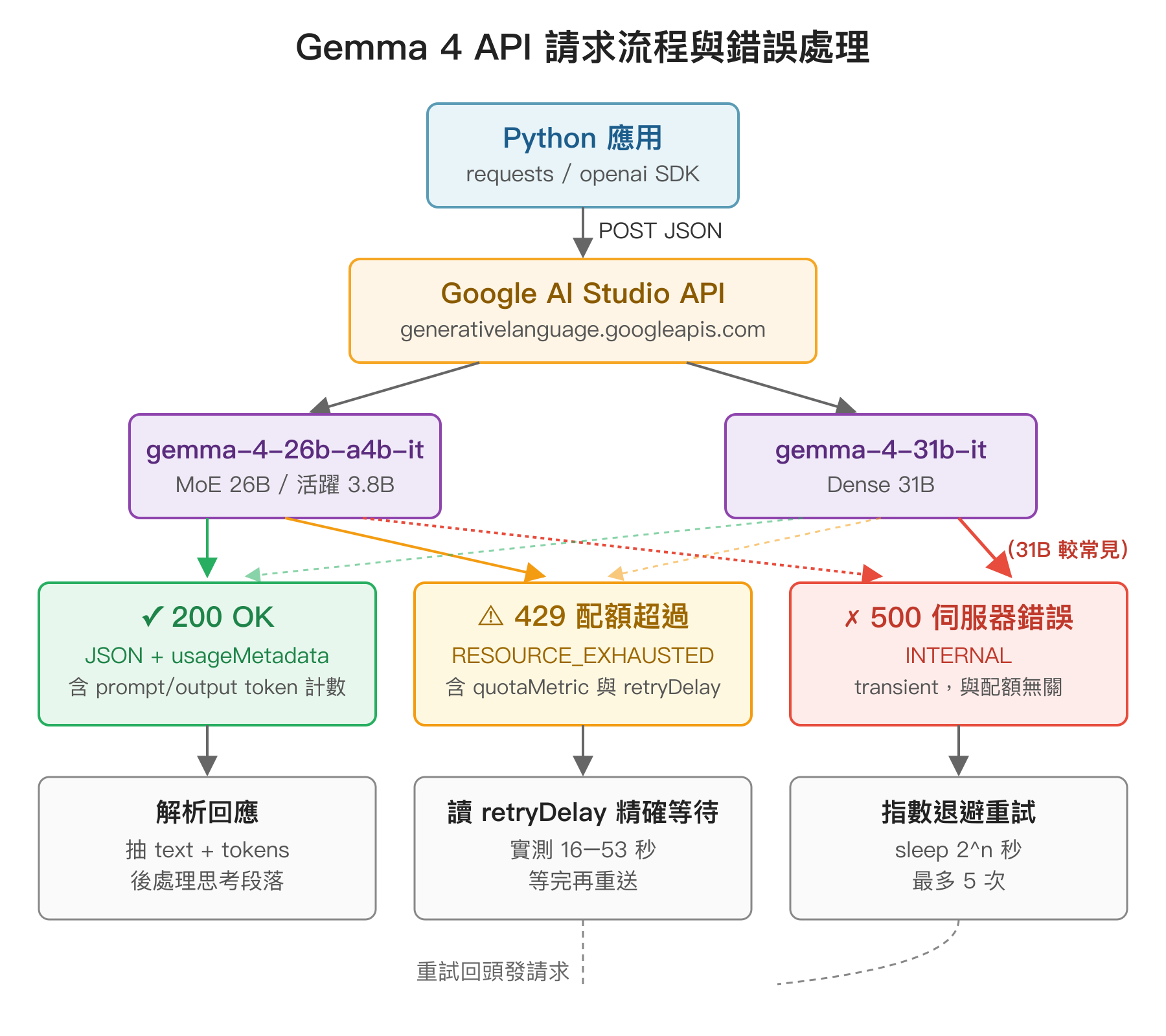
200 順利解析、429 讀 retryDelay 等待、500 走指數退避重試,兩種重試路徑都回到應用端重送請求。
基本呼叫
import os
import requests
API_KEY = os.environ["GOOGLE_API_KEY"]
MODEL = "gemma-4-26b-a4b-it"
URL = f"https://generativelanguage.googleapis.com/v1beta/models/{MODEL}:generateContent?key={API_KEY}"
payload = {
"contents": [
{"role": "user", "parts": [{"text": "用繁體中文寫一個 Hello World 程式範例,只要程式碼。"}]}
],
"generationConfig": {"temperature": 0.3, "maxOutputTokens": 512},
}
r = requests.post(URL, json=payload, timeout=60)
r.raise_for_status()
data = r.json()
text = data["candidates"][0]["content"]["parts"][0]["text"]
usage = data["usageMetadata"]
print(text)
print(f"input tokens: {usage['promptTokenCount']}, output tokens: {usage['candidatesTokenCount']}")整個流程就是 POST 一個 JSON、拿回一個 JSON 這麼簡單。usageMetadata 會告訴我們 prompt 與輸出各用了多少 token,可以拿來估計是否還在免費額度內。
實測範例一:SEO 標題生成
用 26B 生成一篇 PostgreSQL 遷移教學文的 SEO 標題(關於 PostgreSQL 的寫作可以參考 給 MySQL/SQL Server 用戶的 PostgreSQL 入門):
Prompt:
我寫了一篇技術文章,內容是教 MySQL/SQL Server 用戶怎麼轉 PostgreSQL,
重點包含識別字大小寫、自增主鍵、UPSERT 寫法、Schema 命名空間、連線模型。
請給我 5 個可用的 SEO 標題,60 字元以內,包含主關鍵字 PostgreSQL。
直接列編號清單,不要多餘說明。
輸出(節錄最終標題):
1. MySQL/SQL Server 轉 PostgreSQL 完整指南:五大關鍵差異
2. 從 MySQL/SQL Server 遷移到 PostgreSQL:開發者必讀手冊
3. PostgreSQL 入門:MySQL 與 SQL Server 用戶轉移必知重點
4. PostgreSQL 遷移攻略:處理大小寫、UPSERT 與 Schema 差異
5. 告別 MySQL/SQL Server:PostgreSQL 核心語法與架構轉換
耗時 14.8 秒、93 output tokens、6.28 tok/s這邊有一個 Gemma 4 很特別的行為要記一下:就算 prompt 寫得清楚「直接列編號清單、不要多餘說明」,模型還是會先在輸出最前面列出它的分析步驟、草稿、檢查清單,最後才輸出最終 5 個標題。這個特性在所有測試題上都一樣,即使換成 31B 也差不多。
實務上要拿到乾淨輸出有幾種做法:加 system instruction 強調「不要任何推理過程」、在 prompt 最後加一行「Answer:」暗示直接給答案、用 stopSequences 設定終止符號、或是直接在程式裡用正規表達式抽最後一段。最後這招最實用,因為 Gemma 4 通常會把最終答案放在最後。
那改成要求 JSON 輸出會不會更穩?實測同一個 SEO prompt 開 generationConfig.responseMimeType = "application/json",Gemma 4 還是一樣先列關鍵字分析、草稿選項、驗證清單,preamble 長達好幾百 token,最後才吐一個可 parse 的 JSON 陣列。換句話說 JSON 格式本身沒辦法把 preamble 壓掉——Gemma 4 就是會先想出聲,跟輸出格式無關。responseMimeType 唯一的好處是保證結尾有一段合法 JSON 可以 regex 抽出來,不會被中英混雜的自然語言包住。
還有一個陷阱:Gemini API 另一個強制結構化輸出的欄位 responseSchema(給一份 JSON Schema,模型會嚴格照欄位產出),Gemma 4 不支援。實測把 schema 設為 {"type": "ARRAY", "items": {"type": "STRING"}},API 會在 0.76 秒內回傳一個空陣列 [],完全沒產生內容。這個行為在 Google 的文件裡沒有明寫,社群也沒大量案例——結論是 responseSchema 是 Gemini 專屬功能,要嚴格 schema 限制得換成 Gemini Flash。
實測範例二:結構化 JSON 輸出
Prompt:
從下面這段文字抽出結構化資料,以有效 JSON 輸出(不要 markdown fence,不要其他文字)。
欄位:model_name, parameters_b, release_date, context_window_k。
Gemma 4 31B 是 Google DeepMind 於 2026 年 4 月 2 日發布的開放權重模型,
擁有 310 億參數,支援最長 256K tokens 的上下文視窗。
輸出(最終 JSON):
{
"model_name": "Gemma 4 31B",
"parameters_b": 310,
"release_date": "2026-04-02",
"context_window_k": 256
}
耗時 15.1 秒、60 output tokens結構化抽取準確度很高,四個欄位型別都對(數字是真的 integer、不是字串),日期也自動轉成 ISO 8601。但同樣模型還是會先輸出思考步驟,最後才給 JSON。如果程式要直接餵給 json.loads(),要先把輸出裡最後一個 { ... } 抽出來:
import json
import re
def extract_last_json(text: str) -> dict:
"""從模型輸出中抽出最後一個 JSON 物件。"""
matches = re.findall(r'\{[^{}]*(?:\{[^{}]*\}[^{}]*)*\}', text, re.DOTALL)
if not matches:
raise ValueError("no JSON found")
return json.loads(matches[-1])
clean = extract_last_json(text)
print(clean)實測範例三:Code Review
丟一段有 SQL injection 漏洞的 Python 程式碼請模型審查:
# 給模型審查的原始程式碼
def get_user(user_id):
conn = sqlite3.connect('users.db')
cursor = conn.cursor()
cursor.execute(f"SELECT * FROM users WHERE id = {user_id}")
result = cursor.fetchone()
return result兩個模型都準確抓到四個問題:SQL Injection、資源洩漏(連線與 cursor 沒關)、缺少 try/except、連線沒有共用。26B 用 38.2 秒產出 1099 tokens,31B 用 53.2 秒產出 1240 tokens,內容細緻度相近,31B 額外提到「SELECT * 不建議、應該指定欄位」這點。在這個類型的任務上兩個模型差距不大,26B 的 CP 值比較高。
Streaming 實時輸出
前面的 generateContent 是一次回傳完整答案,要等模型完全生成結束。改用 streamGenerateContent 可以像 ChatGPT 網頁那樣逐字流出來,互動感好很多,而且可以量測 Time To First Token(首個 token 出現的時間):
import json
import os
import time
import requests
API_KEY = os.environ["GOOGLE_API_KEY"]
MODEL = "gemma-4-26b-a4b-it"
URL = (
f"https://generativelanguage.googleapis.com/v1beta/models/"
f"{MODEL}:streamGenerateContent?alt=sse&key={API_KEY}"
)
payload = {
"contents": [{"role": "user", "parts": [{"text": "列出 Python 10 個最實用的標準庫"}]}],
"generationConfig": {"temperature": 0.3, "maxOutputTokens": 1024},
}
t0 = time.perf_counter()
first_token_at = None
buffer = ""
with requests.post(URL, json=payload, stream=True, timeout=180) as r:
r.raise_for_status()
r.encoding = "utf-8" # 注意:Gemini SSE 沒宣告 charset,要明確設 utf-8
for raw in r.iter_lines(decode_unicode=True):
if raw == "":
if buffer.startswith("data: "):
data = json.loads(buffer[6:])
try:
text = data["candidates"][0]["content"]["parts"][0]["text"]
if first_token_at is None:
first_token_at = time.perf_counter() - t0
print(f"[TTFT {first_token_at:.2f}s]")
print(text, end="", flush=True)
except (KeyError, IndexError):
pass
buffer = ""
elif raw is not None:
buffer += raw
print()實測下來 TTFT 大概在 1–7 秒之間波動,平均約 3 秒。這個延遲不算短,跟 Anthropic Claude 或 OpenAI GPT 差不多量級,但比本地 Ollama 跑模型慢很多(本地 TTFT 通常 <0.5 秒)。所以 AI Studio 的 Gemma 4 適合拿來做批次、非即時的任務,不適合做需要即時回應的互動場景。這邊特別提醒:iter_lines(decode_unicode=True) 在 Gemini SSE 端點上預設會用 latin-1 解中文,要記得手動 r.encoding = "utf-8",不然中文會變亂碼。
26B 與 31B 實測對比
把同樣的七組 prompt 分別丟給兩個模型,每組都量測耗時、輸入輸出 token 數、有效 tokens/second,來看實際差別。以下數據都是 2026-04-24 用免費層 API 實測的結果。
| 測試項目 | 26B 秒數 | 26B 輸出 tok | 26B tok/s | 31B 秒數 | 31B 輸出 tok | 31B tok/s |
|---|---|---|---|---|---|---|
| 中文 SEO 標題生成 | 14.8 | 93 | 6.28 | 14.3 | 79 | 5.51 |
| 技術文章中翻英 | 21.2 | 76 | 3.59 | 24.6 | 77 | 3.13 |
| Python 程式題 | 71.9 | 498 | 6.93 | 80.8 | 493 | 6.10 |
| 邏輯推理題 | 69.3 | 631 | 9.10 | 47.2 | 724 | 15.34 |
| 長文摘要(1500 字輸入) | 19.4 | 143 | 7.37 | 20.5 | 144 | 7.04 |
| 結構化 JSON 抽取 | 14.0 | 87 | 6.23 | 19.8 | 78 | 3.94 |
| Code Review | 38.2 | 1099 | 28.76 | 53.2 | 1240 | 23.31 |
| 平均 | 35.5 | 375 | 9.75 | 37.2 | 405 | 9.20 |
從數據看得出幾個重點:
- 速度差距不大:平均 tok/s 兩個模型非常接近,9.75 vs 9.2。理論上 26B 因為 MoE 只有 3.8B 活躍參數應該快很多,實際透過 AI Studio API 看不出來差異,推測 Google 端對免費層的兩個模型應用了類似的頻寬上限。
- 輸出 token 數量相近:同樣 prompt 下 26B 與 31B 產出的內容長度很接近,沒有哪個明顯話比較多。
- 品質差異有但不大:Code Review 這種需要多點技術廣度的題目 31B 略勝(多點出幾個問題),數學推理 31B 的計算步驟更清楚,其他任務兩個差異幾乎察覺不到。
- 31B 穩定度較差:我實測時 31B 在 7 題裡有 6 題第一次打進去回 HTTP 500 Internal Error,需要退避重試;26B 全數一次成功。這暗示 31B 免費層伺服器端負載比較重,或是 Google 有限流機制。實作時一定要加 retry 邏輯。
結論是:大多數日常應用場景優先選 26B A4B 就好,速度跟品質差不多、穩定度更好、Token 用量也接近,免費額度更耐用。真的遇到長推理、多步驟的困難問題才切 31B。這也呼應 MoE 架構的設計初衷:用比較少的活躍參數達到近似 30B 模型的品質。
500 與 429 錯誤怎麼分
上面提到 31B 有不少 500 錯誤,很多人會以為是配額用完、觸發 rate limit。其實這兩個錯誤是不同原因,搞清楚才能寫出對的 retry 邏輯。我當天除了原本七題 benchmark 之外,另外跑了一輪 burst 壓測(20 個並發請求)、一輪大輸入測試(30 萬字 prompt 給 31B),專門觀察兩種錯誤的行為。
| 錯誤碼 | 含意 | 在 Gemma 4 上的觀察 | 應對 |
|---|---|---|---|
| 429 | RESOURCE_EXHAUSTED,配額已超過 | 只有在 burst 壓測時(> 15 RPM)才會觸發,回傳 body 會帶 quotaMetric、quotaValue、retryDelay 三個欄位 | 照 retryDelay 等待後重試,不要再用指數退避疊加 |
| 500 | INTERNAL,伺服器端內部錯誤 | 31B 單獨測試即使低頻連續發,仍有約 40% 機率回 500;26B 幾乎不會 | 指數退避重試 3–5 次通常都能救回來 |
| 503 | UNAVAILABLE,伺服器高負載 | 偶發,罕見 | 跟 500 類似,指數退避重試 |
這也解釋了為什麼前面 benchmark 可以只靠重試就把 31B 全部救回來:它的 500 是真的 transient server error,不是 quota 問題。一個實用的 retry wrapper 大概像這樣:
import time
import requests
def call_with_retry(url, payload, max_retries=5):
for attempt in range(1, max_retries + 1):
r = requests.post(url, json=payload, timeout=180)
if r.status_code == 200:
return r.json()
if r.status_code == 429:
# 配額問題,讀 retryDelay 精確等待
info = r.json().get("error", {}).get("details", [])
delay = 60
for d in info:
if d.get("@type", "").endswith("RetryInfo"):
delay = int(d.get("retryDelay", "60s").rstrip("s"))
print(f" 429 rate limited, sleeping {delay}s")
time.sleep(delay)
continue
if r.status_code in (500, 503):
# 伺服器問題,指數退避
wait = 2 ** attempt
print(f" {r.status_code} transient, retrying in {wait}s")
time.sleep(wait)
continue
r.raise_for_status()
raise RuntimeError(f"failed after {max_retries} retries")本地硬體需求與價格
既然提到免費用雲端很划算,自然會有人問:那如果想離線跑、自己養機器,要買多少錢的設備?以下整理在使用 Ollama 這類 llama.cpp 基礎的工具、採用 Q4_K_M 量化(這是目前本地 LLM 的最實用平衡點)的情況下,要「順暢」跑的硬體門檻。
「順暢」這邊定義為 ≥ 20 tokens/sec 的穩態生成速度,這大致等於人類閱讀速度的 3 倍以上,對話互動不會有明顯卡頓。低於 15 tok/s 會覺得有點慢、低於 10 tok/s 只能當批次任務用。模型本身的 Q4 檔案大小約:
- Gemma 4 26B A4B(MoE)Q4_K_M:約 16 GB
- Gemma 4 31B Dense Q4_K_M:約 19 GB
實務上除了模型本身,上下文(KV cache)、作業系統、其他程式也會吃記憶體,建議預留 1.5 倍的 headroom。
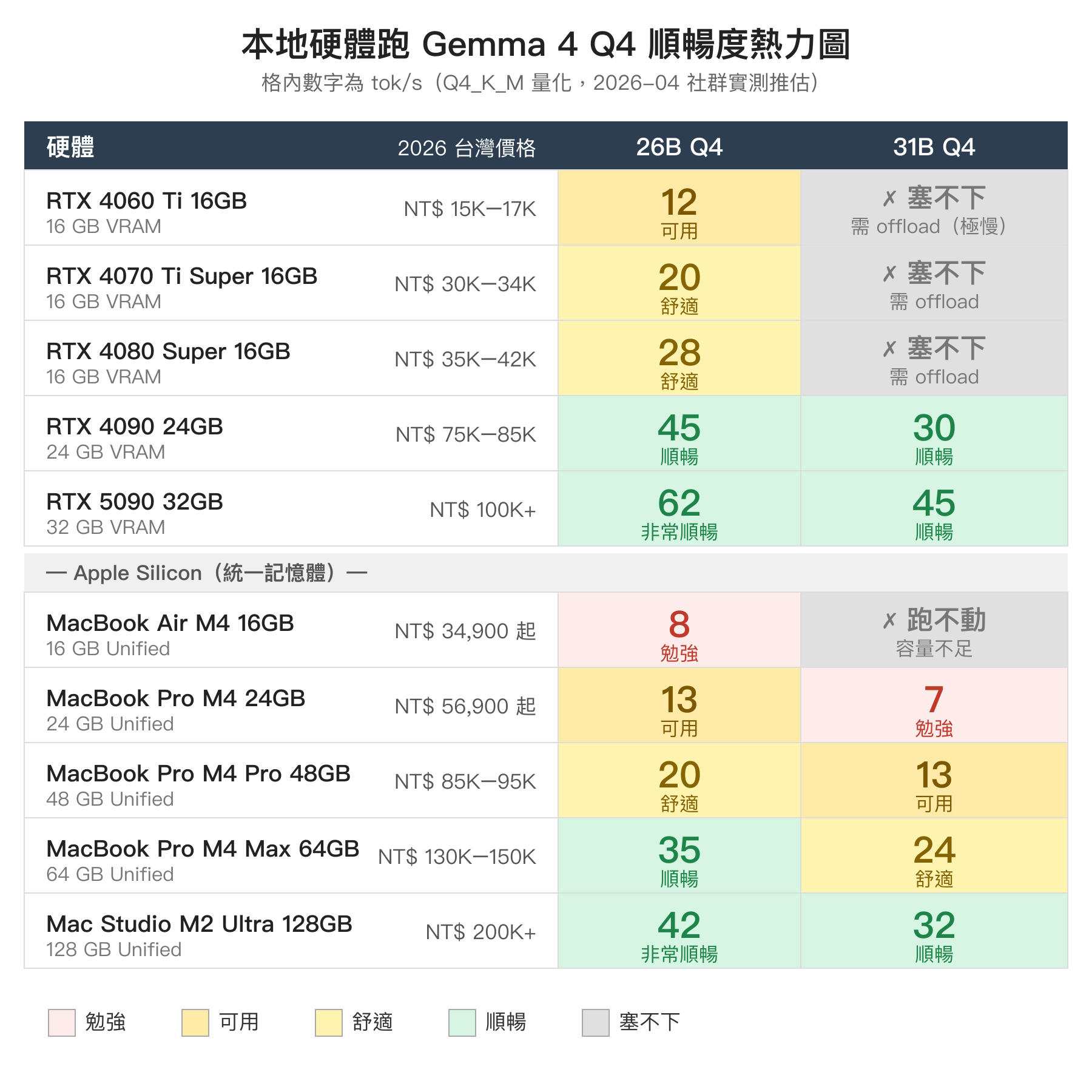
RTX 系列顯示卡
| 顯示卡 | VRAM | 2026 台灣價格約 | 26B Q4 順暢度 | 31B Q4 順暢度 |
|---|---|---|---|---|
| RTX 4060 Ti 16GB | 16 GB | NT$ 15,000–17,000 | 剛好塞得下,10–15 tok/s,偶爾 OOM | 塞不下,需 offload,< 5 tok/s 不建議 |
| RTX 4070 Ti Super 16GB | 16 GB | NT$ 30,000–34,000 | 可用,20 tok/s 上下 | 塞不下 |
| RTX 4080 Super 16GB | 16 GB | NT$ 35,000–42,000 | 舒適,25–30 tok/s | 塞不下 |
| RTX 4090 24GB | 24 GB | NT$ 75,000–85,000 | 舒適,40–50 tok/s | 可用,25–35 tok/s |
| RTX 5090 32GB | 32 GB | NT$ 100,000+ | 非常舒適,60+ tok/s | 舒適,40–50 tok/s |
結論非常清楚:想順暢跑 26B 最低要 RTX 4080 Super 16GB,想順暢跑 31B 要 RTX 4090 24GB 以上。如果預算有限只願意投 RTX 4060 Ti 16GB,建議還是留在 AI Studio 雲端跑,本地體驗會蠻挫折。反過來說如果已經有 RTX 4090 或 5090,那本地 + 雲端搭配使用最划算——需要快回應的工作本地跑、需要一次跑大量批次時雲端跑,免得把自己電腦吃滿一整天。
Apple Silicon Mac
Mac 的優勢是統一記憶體架構(Unified Memory),GPU 可以直接用系統記憶體,不用像 RTX 那樣分開算 VRAM 與 RAM。劣勢是記憶體頻寬比同價位 NVIDIA 低,實際 tok/s 會比 VRAM 數字相近的顯卡慢不少。Mac 實務經驗可以參考 Gemma 4 在 M2 Pro 的本地 Benchmark 這篇詳細實測。
| 機型 | Unified Memory | 2026 台灣價格約 | 26B Q4 順暢度 | 31B Q4 順暢度 |
|---|---|---|---|---|
| MacBook Air M4 16GB | 16 GB | NT$ 34,900 起 | 剛好,但系統吃緊,10 tok/s 以下 | 跑不動 |
| MacBook Pro M4 24GB | 24 GB | NT$ 56,900 起 | 可用,12–15 tok/s | 勉強,5–8 tok/s |
| MacBook Pro M4 Pro 48GB | 48 GB | NT$ 85,000–95,000 | 舒適,18–22 tok/s | 可用,12–15 tok/s |
| MacBook Pro M4 Max 64GB | 64 GB | NT$ 130,000–150,000 | 非常舒適,30–40 tok/s | 舒適,20–28 tok/s |
| Mac Studio M2 Ultra 128GB | 128 GB | NT$ 200,000+ | 非常舒適,40+ tok/s | 非常舒適,30+ tok/s |
Mac 陣營想順暢跑 26B 的甜蜜點是 M4 Pro 48GB,想順暢跑 31B 要 M4 Max 64GB 起跳。MacBook Air 16GB 跟 MacBook Pro 24GB 可以「跑得起來」但是體驗不好,會搶系統記憶體影響其他程式。
本地 vs 雲端的 CP 值對比

把兩邊放在一起比:
- AI Studio 免費層:成本 0 元、速度 ~9 tok/s、每個模型 15 RPM 獨立計算、隱私條款寬鬆
- 本地 RTX 4090:硬體 8 萬、速度 40 tok/s+、無使用上限、完全離線
- 本地 M4 Max 64GB:硬體 13 萬、速度 30 tok/s+、無使用上限、完全離線、可攜帶
實務建議:只是想試水溫、一天跑個幾十次、不在乎速度,AI Studio 免費層完全夠。要每天跑上千次、要離線處理敏感資料、要把 LLM 嵌入個人工作流(像用 Claude Code 那樣整天使用),買 RTX 4090 或 M4 Max 才划算。介於中間的情境可以考慮 OpenRouter、Groq 這類付費雲端服務,成本可能比自己養機器還低。
接到 Agent CLI 使用
拿到 Gemma 4 的 API key 之後,可以把它接到現有的 Agent CLI 工具上,讓那些工具不再只綁在 Claude、GPT 這些付費服務上。以下整理四個常見 CLI 的接法。
OpenAI 相容端點
AI Studio 除了原生的 generativelanguage.googleapis.com 格式之外,也提供 OpenAI 相容端點,位置是 https://generativelanguage.googleapis.com/v1beta/openai/,多數 Agent CLI 只要能設定 OPENAI_BASE_URL 或 OPENAI_API_BASE 就能直接接過去。這個相容端點會把 OpenAI 的請求格式翻譯成 Gemini 格式、回傳時再翻譯回來,相容性很高。
export OPENAI_API_KEY=$GOOGLE_API_KEY
export OPENAI_BASE_URL=https://generativelanguage.googleapis.com/v1beta/openai/
# 之後任何支援自訂 OpenAI 端點的工具都能用 Gemma 4
# 模型名稱直接用 gemma-4-26b-a4b-it 或 gemma-4-31b-it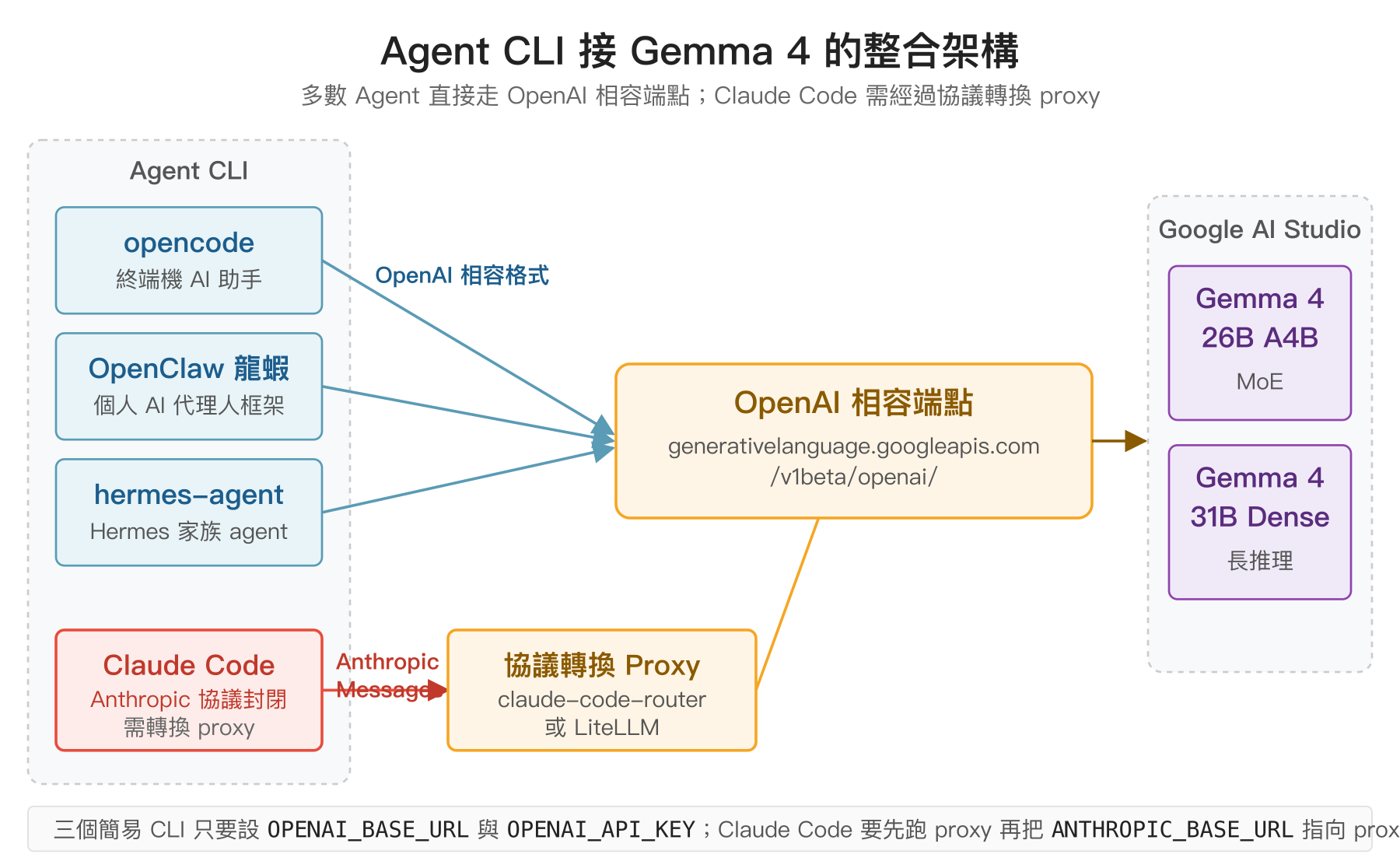
opencode
opencode 是開源的終端機 AI 助手,支援多家 provider。在它的設定檔 ~/.config/opencode/config.json 加上一個 provider:
{
"providers": {
"gemma": {
"name": "Google AI Studio Gemma",
"baseURL": "https://generativelanguage.googleapis.com/v1beta/openai/",
"apiKey": "{env:GOOGLE_API_KEY}",
"models": {
"gemma-4-26b-a4b-it": { "name": "Gemma 4 26B" },
"gemma-4-31b-it": { "name": "Gemma 4 31B" }
}
}
}
}重開 opencode 之後模型選單就會出現 Gemma 4 兩個選項。
OpenClaw(龍蝦)
OpenClaw(台灣社群暱稱龍蝦🦞)是 MIT 授權的個人 AI 代理人框架,以 Gateway + Skills 架構運作。它在 ~/.openclaw/config.yaml 支援自訂 LLM provider:
llm:
provider: openai
base_url: https://generativelanguage.googleapis.com/v1beta/openai/
api_key: ${GOOGLE_API_KEY}
default_model: gemma-4-26b-a4b-it
fallback_model: gemma-4-31b-it之後所有 OpenClaw 的 Skill(例如檔案處理、瀏覽網頁、工作排程)都會透過 Gemma 4 思考與決策。注意 OpenClaw 的 Skill 機制仰賴 function calling,Gemma 4 的工具呼叫能力相對 GPT-4 或 Claude Sonnet 稍弱,複雜的多步 Skill 遇到失敗率會比較高。
hermes-agent
hermes-agent 是基於 Nous Research 的 Hermes 模型家族衍生出的 agent 框架,同樣走 OpenAI 相容端點。設定方式類似 opencode,在 hermes.toml 加上:
[llm]
provider = "openai"
base_url = "https://generativelanguage.googleapis.com/v1beta/openai/"
api_key_env = "GOOGLE_API_KEY"
model = "gemma-4-26b-a4b-it"Claude Code
Claude Code 本身是 Anthropic 閉源協議的 CLI,沒有內建切換 LLM provider 的能力。要讓它改用 Gemma 4 得透過第三方的協議轉換 proxy,常見兩個選擇:
- claude-code-router:專門把 Anthropic Messages API 轉到其他 provider 的 proxy,社群維護,支援 Gemini/Gemma 為後端。
- LiteLLM:通用 LLM proxy,可以同時把 Anthropic、OpenAI、Gemini 格式互轉,功能較多但設定較複雜。
以 claude-code-router 為例,流程大致是本機起一個 proxy(例如 localhost:3000)配置後端為 Gemma 4,然後把 Claude Code 的 ANTHROPIC_BASE_URL 指向這個 proxy:
# 啟動 claude-code-router,後端指向 Gemma 4
npx claude-code-router start \
--backend gemini \
--base-url https://generativelanguage.googleapis.com/v1beta/openai/ \
--model gemma-4-26b-a4b-it \
--api-key $GOOGLE_API_KEY
# 另一個終端機把 Claude Code 指向本地 proxy
export ANTHROPIC_BASE_URL=http://localhost:3000
claude務實地反向說一件事:Claude Code 深度仰賴 Anthropic 特有的 Tool Use、System Prompt Caching、Extended Thinking 等功能。轉到 Gemma 4 之後,部分工具呼叫可能失敗、快取機制會失效、連續對話的效能會比原生 Claude 差。如果只是想省錢來跑日常 coding 任務,拿 Gemma 4 當輕量備援還行;但 Claude Code 主要的產品體驗就是來自 Claude 模型本身,完全改用 Gemma 4 並不建議。想要離線 AI coding 體驗建議直接用 opencode 搭配 Gemma 4,原生設計就是 provider-agnostic,遠比改裝 Claude Code 順。
實務使用建議
把前面所有測試與觀察整理成幾點使用建議:
- 先用 26B,32B 只在需要時切換:速度品質都接近,26B 穩定度明顯更好、免費額度更耐用。
- 一定要實作 retry:429(rate limit)讀 retryDelay 等待;500/503(transient)指數退避重試。兩個機制分開處理。
- 預期雲端 API ~9 tok/s:只有本地 RTX 4090 的 1/4。適合批次、非即時任務;互動場景會覺得慢。
- 輸出要後處理:Gemma 4 習慣先吐思考過程,最後才給答案。用 stop sequence、system instruction 或正規表達式抽最後一段才能拿到乾淨輸出。
- 中文輸出要手動設 UTF-8:requests 的 SSE streaming 預設會用 latin-1 解碼,
r.encoding = "utf-8"一定要加,不然中文亂碼。 - 隱私敏感資料不要直接送:免費層請求會用於產品改善。涉及個資、機密資料的場景升級付費層或改用 Vertex AI。
整體看下來,Google AI Studio 的免費層對個人開發者來說是現階段 CP 值最高的開放權重模型雲端試玩方案。不用花錢買顯卡就能摸到 26B、31B 這個等級的模型,夠用來做原型、寫 hobby project、學習 prompt engineering。真的要把 Gemma 4 整進日常工作流、頻繁使用,才值得投資本地硬體或付費層。這個免費機會現在還在,趁還沒收緊之前先把 API key 拿起來放著,有空多試幾種應用場景,對後續的選型判斷會有很實際的幫助。