
OpenAI 在 2026-04-23 發表 GPT-5.5(內部代號 Spud),距前代 GPT-5.4 只有六週,是這一年來 AI 前線競賽節奏最密集的一次。這篇文章整理幾件開發者最想知道的事:GPT-5.5 到底進步在哪、官方透露了多少架構細節、ChatGPT/Codex/API 三種入口各自怎麼用到新模型、API 價格怎麼變動、以及這代漲價放在 Claude Opus 4.7 隱性 tokenizer 漲價事件旁邊看的對比。文章寫作的當下 API 尚未開放,所以速度與品質的實測只能等 API 開放後另外寫追蹤文,本文以官方資料與第三方評測交叉引用為主,合理推測的部分都會明確標示。
發表脈絡與時間軸
OpenAI 這一年的發表節奏加速非常明顯。回顧 GPT-5 家族從去年底到現在的時序:
- GPT-5(2025 年中):5 系列的首發版本
- GPT-5.2(2026-01):強化推理與工具使用
- GPT-5.4(2026-03 初):引入 Pro 變體與更長 context
- GPT-5.5(2026-04-23):本篇主角,代號 Spud
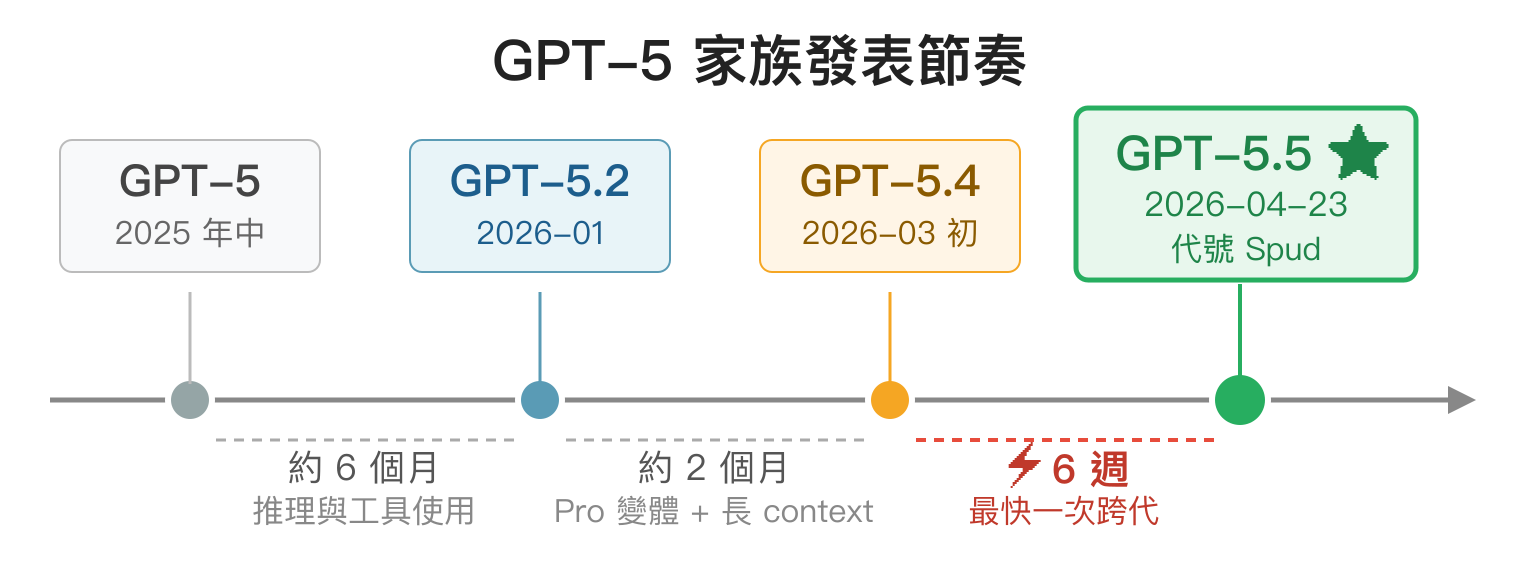
6 週推一個大版本——不是小 patch 而是「smartest model yet」級別的改版——在前幾年是不敢想的速度。Fortune、TechCrunch 普遍將這波節奏解讀為 OpenAI 跟 Anthropic、Google 在企業市場的貼身肉搏:Anthropic 兩週前才推 Claude Opus 4.7(2026-04-16 發表),Google 則在 3 月底更新 Gemini 3.1 Pro。三家都在搶一個敘事——「agentic coding 時代誰家模型最強」。
這次的代號 Spud(馬鈴薯)延續 OpenAI 喜歡用生活化代號的習慣,VentureBeat 的標題也直接拿「這顆 Spud 不是馬鈴薯」開玩笑。不過代號的事情不重要,對開發者重要的是下面這些。
架構有什麼變化
先說結論:OpenAI 沒公開詳細架構。這是 OpenAI 自 GPT-4 之後一貫作風,模型本身的 parameter count、專家數、layer 設計都是商業機密。這次的官方 blog 與 System Card 也只寫「更大的後訓練、更多代理能力、對齊機制改善」這種高層敘述。可以確認的技術面向只有幾點:
NVIDIA 硬體合作
GPT-5.5 co-designed、trained、served 在 NVIDIA GB200 與 GB300 NVL72 系統上。這是 NVIDIA 這兩年主推的 AI 伺服器架構,單櫃 72 顆 GPU 並用 NVLink 共享記憶體,對跨節點通訊密集的大模型訓練特別有利。OpenAI 跟 NVIDIA 聯名發了 一篇 blog,是這次發表週比較罕見的硬體面披露。
同 latency、更聰明的秘訣
OpenAI 這次特別強調一件事:GPT-5.5 維持跟 GPT-5.4 一樣的 per-token latency,但模型能力明顯提升。這通常不可能——更大的模型推理一定更慢。他們給的解釋是「把推論當成一個完整系統重新設計,不只是針對某幾個節點做微優化」,意思是從硬體、編譯器、kernel、服務編排到快取策略的端到端重做。這個敘述比較像行銷語言,具體細節沒有講。
「重新訓練基座」的傳聞
發表當天有第三方評測站(ofox.ai)說 GPT-5.5 是「自 GPT-4.5 以來第一個完全從頭訓練的基座模型」,但 OpenAI 官方沒有證實。從 benchmark 結果來看(下面會詳述),長上下文能力的跳躍幅度驚人,不像只是微調產生的效果,這個傳聞看起來不離譜,但仍屬於未驗證的推測。
Tokenizer 有沒有換
這點是開發者現階段最關心的,因為 Anthropic 的 Claude Opus 4.7 兩週前才被揭發新 tokenizer 會讓同樣內容吃掉更多 tokens,等於隱性漲價。Anthropic 官方文件寫的倍率是 1×–1.35×,但發表後幾位熟 LLM 的獨立測試者(Simon Willison、byteiota、CloudZero 等)重新量測,發現技術文件與程式碼最嚴重的案例可以衝到 1.47×,中日韓則是 1.005×–1.07×(差異很小)。目前官方沒有提到 GPT-5.5 換 tokenizer,社群也沒有類似的測試報告出來。從 API 定價直接大漲、而非以 tokenizer 動手腳的行為模式看,OpenAI 這次走「明帳漲價」路線——這在稍後的定價章節會有更細的對比。
價格提升
伴隨這次架構升級的是 API 價格大幅調漲:標準版 GPT-5.5 是 $5 input/$30 output per 1M tokens,剛好是 GPT-5.4 的 2 倍;另外新增最高階的 GPT-5.5 Pro,單價 $30 input/$180 output,是標準版的 6 倍。Codex 端的 credit 消耗也跟著 API 價格翻倍,但訂閱方案給的每 5 小時訊息數只縮 20–25%,OpenAI 把「5.5 完成任務所需 tokens 更少」的效率加成折回來。跟同期 Anthropic 保持 Opus 4.7 定價不變但偷換 tokenizer 的「隱性漲價」路線形成明顯對比。這段比較簡單先提一下,後面「API 價格與週邊影響」章節會用完整表格與圖表展開,包含跟 Claude Opus 4.7、Gemini 3.1 Pro 的對照。
提升幅度實測
以下數字來自 OpenAI 官方發表簡報、System Card,以及第三方評測站 llm-stats.com 與 BenchLM 的交叉彙整。10 個跨代共用 benchmark 中 GPT-5.5 在 9 題進步。
| 測試項目 | GPT-5.4 | GPT-5.5 | 提升 | 測什麼 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 75.1% | 82.7% | +7.6 pp | 命令列 agentic coding |
| ARC-AGI-2 | — | — | +11.7 pp | 抽象推理,刻意設計抗飽和 |
| MCP Atlas | — | — | +8.1 pp | MCP 工具使用綜合 |
| MRCR v2(512K–1M ctx) | 36.6% | 74.0% | +37.4 pp | 長上下文多段記憶 |
| Graphwalks BFS(1M ctx) | 9.4% | 45.4% | +36.0 pp | 長上下文結構化推理 |
| CyberGym | 79.0% | 81.8% | +2.8 pp | 資安攻防 |
| 內部 CTF | 83.7% | 88.1% | +4.4 pp | OpenAI 內部資安測試 |
| BigLaw Bench | 91.0% | 91.7% | +0.7 pp | 法律實務 |
| GDPval | — | 84.9% | — | 經濟價值工作模擬 |
| OSWorld-Verified | — | 78.7% | — | 桌面電腦自動操作 |
| Tau2-bench Telecom | — | 98.0% | — | 電信領域任務 |
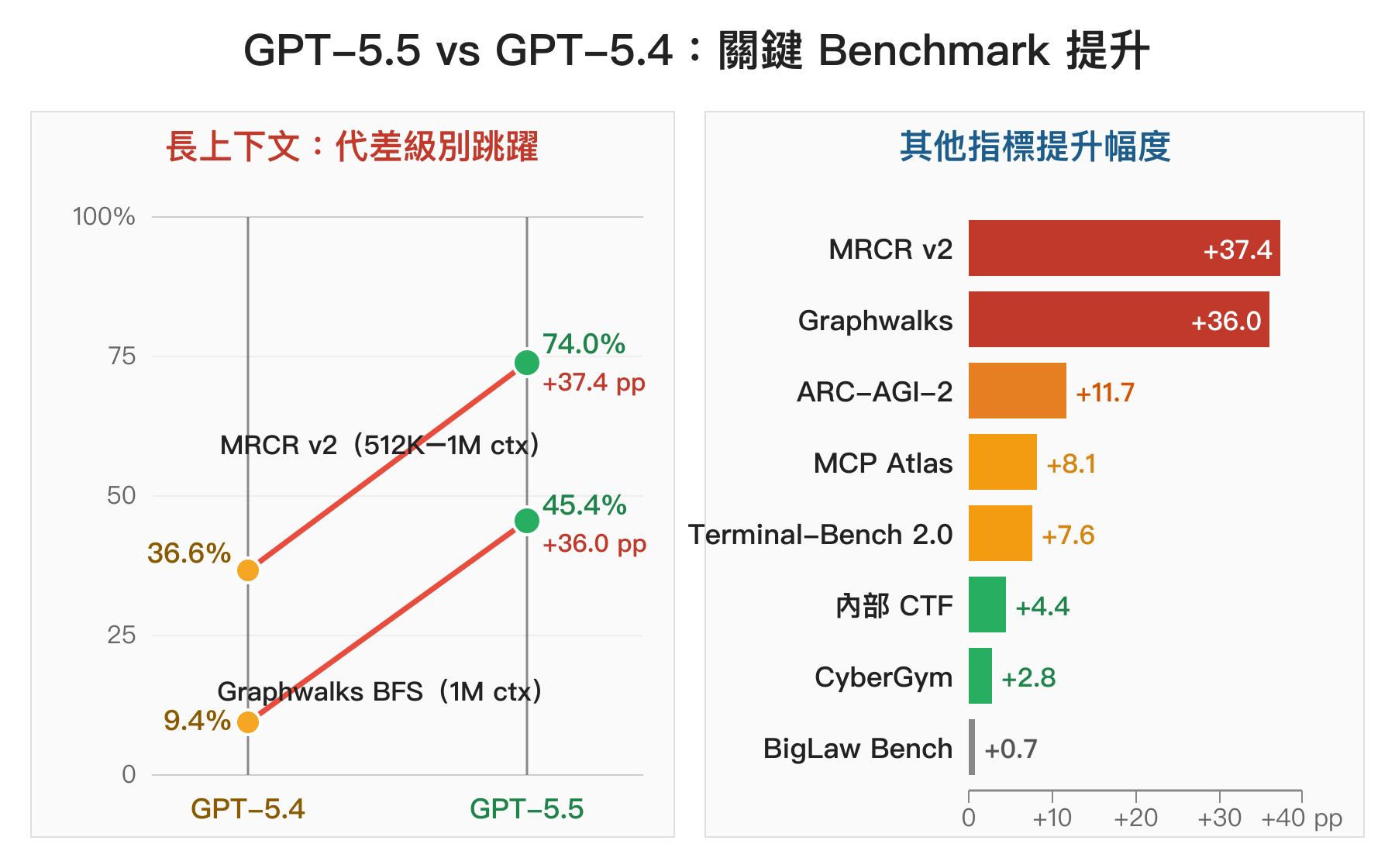
真正值得停下來看的是中間那兩列粗體:MRCR v2 從 36.6% 跳到 74.0%、Graphwalks BFS 從 9.4% 跳到 45.4%。這兩個 benchmark 是在 512K 到 1M tokens 的超長上下文下測模型能否穩定記憶與推理,GPT-5.4 時代基本是「裝得下但用不好」,5.5 一下把它變成堪用的能力。這個幅度在 AI 發展史上算級別的跳躍,不是微調能達到的。從這點回推「重新訓練基座」的傳聞有一定可信度,但仍需官方證實。
Terminal-Bench 2.0 的 82.7% 是 OpenAI 這次主打的賣點之一,意義在於它贏了 Anthropic 同期的 Claude Mythos Preview(Opus 後續版本的 research preview),但只贏一點點(VentureBeat 標題用「narrowly beats」)。所以「agentic coding 之王」這個稱號目前是 GPT-5.5,但領先差距不大。
效率方面 OpenAI 宣稱「同樣任務下 GPT-5.5 產生的 tokens 數與重試次數都比 GPT-5.4 少」,這會影響實際成本(見下方價格章節)。這點沒有單一量化指標,但 Harvey、CodeRabbit 等第三方的早期 review 也都有類似印象。
ChatGPT、Codex、API 三種入口怎麼用
GPT-5.5 依入口不同有些微差異,這點官方 Help Center 的頁面寫得比較散,以下整理為一張對照表:
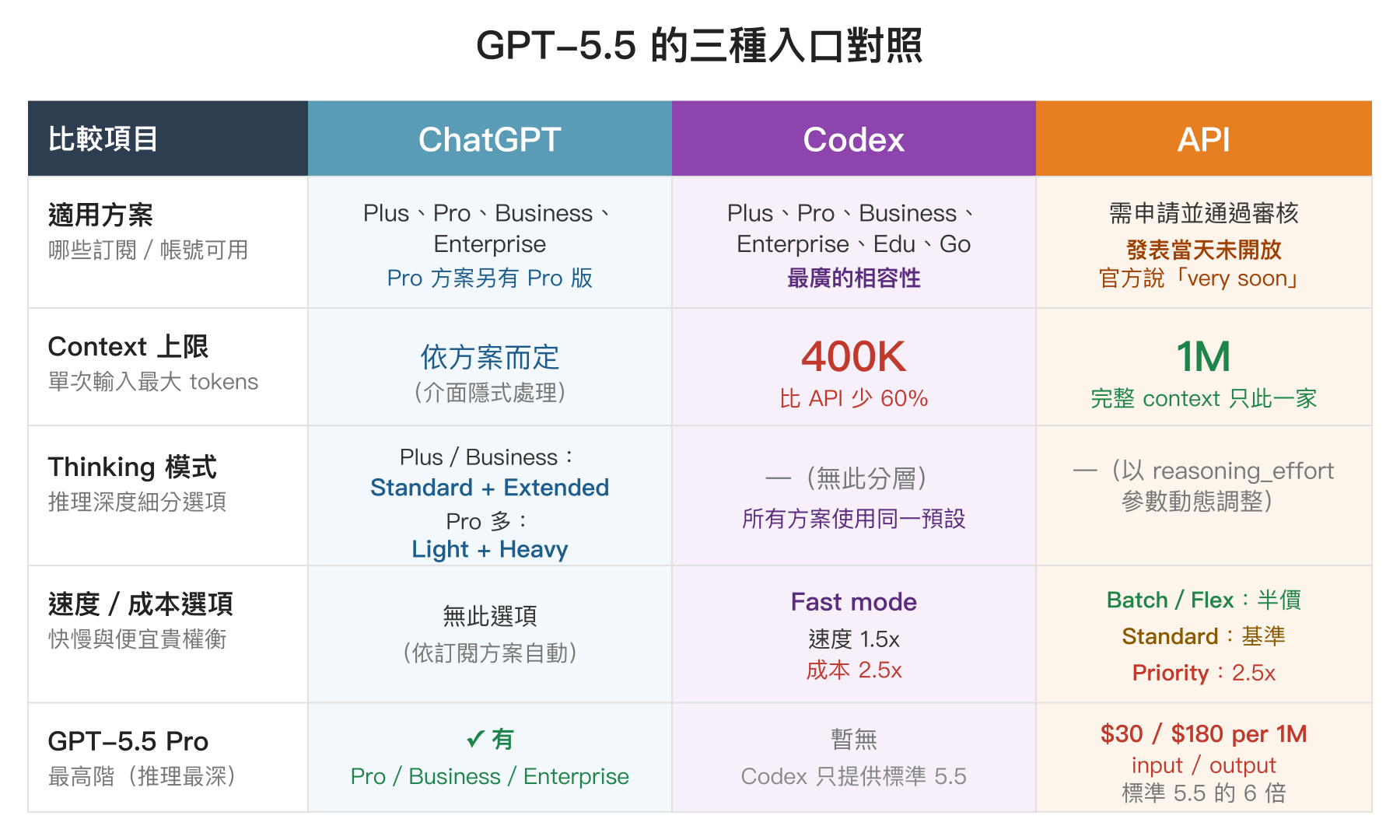
| 入口 | 可用方案 | Context 上限 | Thinking 模式 | GPT-5.5 Pro | 其他 |
|---|---|---|---|---|---|
| ChatGPT | Plus、Pro、Business、Enterprise | 網頁介面(實際上限依方案) | Plus/Business:Standard + Extended Pro:加 Light + Heavy | Pro/Business/Enterprise 可用 | 從 model picker 選「GPT-5.5 Thinking」 |
| Codex | Plus、Pro、Business、Enterprise、Edu、Go | 400K(不是 1M) | — | 暫無 | Fast mode 1.5x 速度、2.5x 成本 |
| API | 已申請並通過的帳號 | 1M | — | 有($30/$180 per 1M) | Batch/Flex 半價、Priority 2.5x 價 |
ChatGPT 用戶
ChatGPT 付費用戶從發表日當天起就能直接用。打開 ChatGPT 介面左上角的模型選擇器,會看到 GPT-5.5 Thinking 出現在清單上。要注意的是 Thinking 模式有細分:
- Standard(新預設):平衡速度與智能
- Extended(以前的 Plus 預設):更深推理
- Light(Pro 限定):速度最快
- Heavy(Pro 限定):最深推理,適合困難研究題
想用 GPT-5.5 Pro(不是 Thinking 模式,是完全不同的更高階模型)要 Pro 方案以上。Pro 現在分兩層:Pro $100/月(Plus 的 5x 用量)與 Pro $200/月(Plus 的 20x 用量),兩個子層都可以用 GPT-5.5 Pro,差別只在每日可用的額度上限,模型權限完全一樣。這個版本針對極難題目優化,代價是 API 價格也翻倍到 $30 input/$180 output(見下方)。
Codex 用戶
Codex 是 OpenAI 的 coding 助手產品,現在所有付費方案(含 Edu 教育版、Go 輕量版)都能用 GPT-5.5,算是這次相容性最廣的入口。但要注意 Codex 的 context 上限是 400K,不是 API 的 1M——這個差距影響很大,長專案全文檢索可能塞不下。我猜測這是 OpenAI 為了保留 context 作為 API 層差異化而刻意設的限制。
Codex 這次新增了 Fast mode,產 token 速度 1.5 倍、成本 2.5 倍。簡單算一下:延遲少三分之一、錢多一倍半。互動場景(inline autocomplete、快速答疑)值得付,批次場景(code review、大重構)則不划算。
API 用戶
API 部分是這次比較特別的安排:發表當天沒有立刻開放,OpenAI 的說法是「API 部署需要不同層級的安全措施,目前正與 partner 與客戶討論服務端的安全與安全性需求」。這跟 Preparedness Framework 把 GPT-5.5 生物/資安能力評為 High 有關——更強能力需要更嚴的管控。上線時間沒有明確給,官方用字只說「very soon」。想第一時間拿到可以先去 OpenAI API 申請等待名單。
API 上線後會走 Responses API 與 Chat Completions API 兩條路,Batch/Flex/Priority 三種速度 / 成本權衡,選擇跟 GPT-5.4 時代相同邏輯。
API 價格與週邊影響
這次最有爭議的點就是 API 漲價。官方定價:
| 模型 | Input $/1M | Output $/1M | Context | 相對 5.4 倍率 |
|---|---|---|---|---|
| GPT-5.4(前代) | $2.50 | $15.00 | 1M | 1x(基準) |
| GPT-5.5 | $5.00 | $30.00 | 1M | 2.0x |
| GPT-5.5 Pro | $30.00 | $180.00 | 1M | 12x |
| Claude Opus 4.7 | $5.00 | $25.00 | — | 對照 |
| Gemini 3.1 Pro(≤200K) | $2.00 | $12.00 | 2M | 對照 |
| Gemini 3.1 Pro(>200K) | $4.00 | $18.00 | 2M | 對照 |
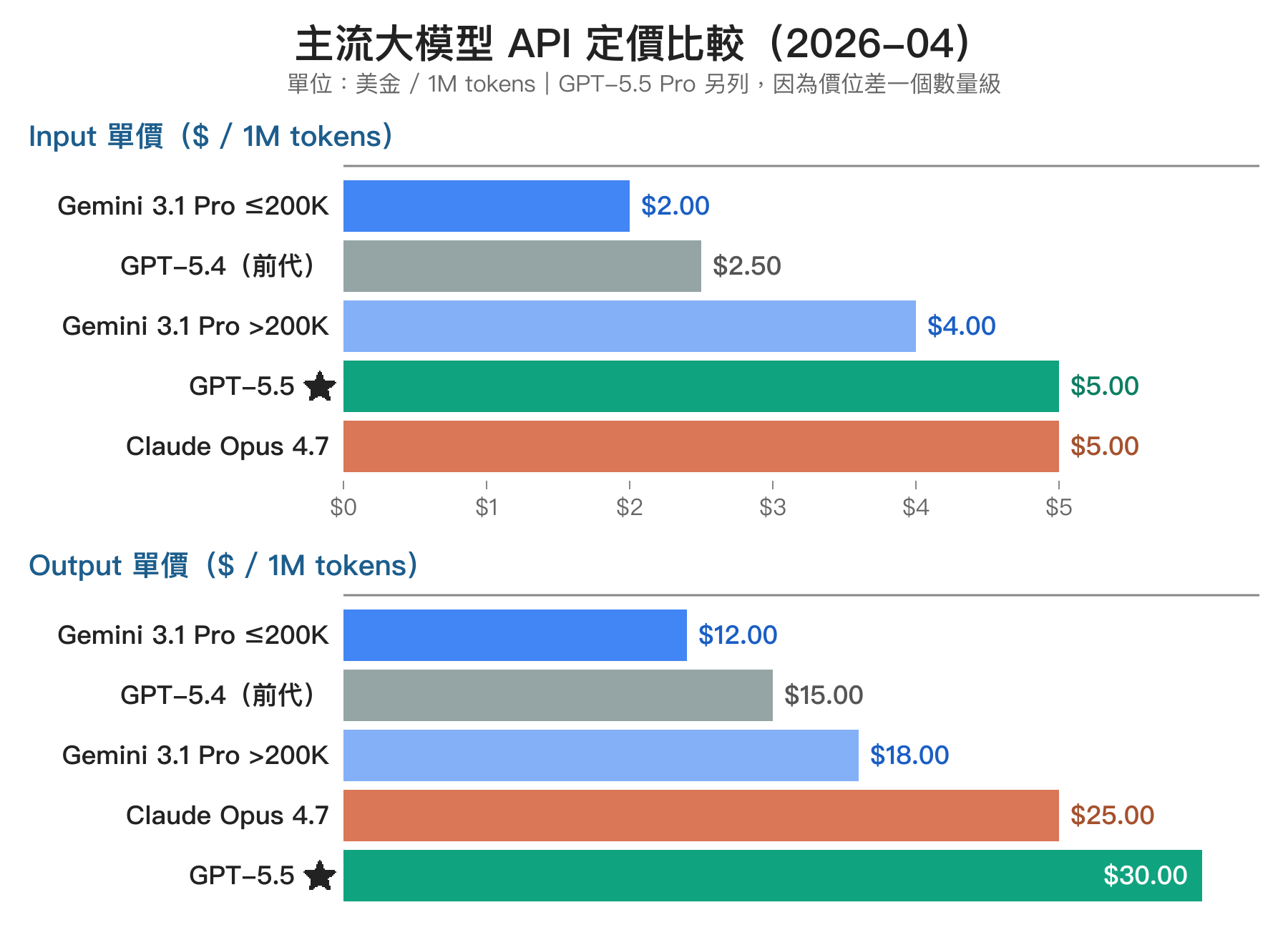
看對照組會發現幾件有意思的事:GPT-5.5 的 input 跟 Claude Opus 4.7 完全一樣、output 比 Opus 4.7 貴 20%;Gemini 3.1 Pro 在 200K context 以下比 GPT-5.5 便宜 60%,即使加上長 context 加乘也還是最划算。OpenAI 這次漲到跟 Anthropic 同一階段,Gemini 仍保持低位策略。
顯性漲價 vs 隱性 tokenizer 膨脹
Anthropic 兩週前推 Claude Opus 4.7 時走了完全不同的策略:保持 $5/$25 定價不變、換新的 tokenizer。官方文件標註的倍率是 1×–1.35×,但社群很快(Simon Willison 2026-04-20 的文章、byteiota、CloudZero 等)量測發現實際上限更高——英文文字會吃掉最多 1.47 倍的 tokens,程式碼還更嚴重,中日韓則只增 1–7%。意思是對英文/Code 重度使用者,Opus 4.7 實質漲價上限可以到 47%,而且完全鋪在 rate card 底下看不出來。
OpenAI 這次走了相反路線——直接在 rate card 上翻倍,沒有玩 tokenizer 魔術。兩家的邏輯大概是:
- Anthropic(隱性):rate card 數字不變,客戶心理較不抗拒;但對技術敏感讀者會覺得被算計、信任受損。Simon Willison 那篇文章其實是個引爆點,引來大量轉發與批評
- OpenAI(顯性):rate card 直接翻倍,客戶第一時間可能覺得貴,但至少看得懂、預算好估。論壇反應反而比 Opus 4.7 那波低——因為數字寫在那裡沒什麼可爭論的
對開發者實務上,預算規劃建議用 rate card 加上量測後的 tokens,別只看價格標籤。遷移 Opus 4.6 → 4.7 要預留 20–47% 成本上升空間(尤其英文 heavy 的專案);使用 GPT-5.4 → 5.5 則直接乘 2 估算即可。反過來說如果 GPT-5.5 真的能用比 5.4 少的 tokens 完成相同任務(OpenAI 的宣稱),實質成本倍率可能落在 1.5x–1.8x 而不是 2x,但這要等 API 上線實測。
GPT-5.5 Pro 值不值得
GPT-5.5 Pro 是這次新加的最高階層,API $30 input/$180 output。價位大概是標準 5.5 的 6 倍、Gemini 3.1 Pro 的 15 倍。值不值得取決於具體場景:對要壓縮研發週期、買回 engineer 時間的團隊(金融模型、新藥研究、法律複雜議題),這個價差是合理的 ROI;對一般工程師問答、日常 coding 任務,標準 5.5 完全夠用,花 Pro 的錢會是浪費。
ChatGPT Pro 方案訂閱用戶可以直接無額外付費用到 GPT-5.5 Pro,這算是 Pro 訂閱這幾年最有吸引力的時刻——因為 API 費率太高,一次性訂閱比跑 API 划算很多。中度使用者選 Pro $100(5x 用量)就夠,重度使用者再升 Pro $200(20x 用量);兩個子層的模型權限一模一樣,只差用量上限。
Codex 用戶的計費變化
Codex 這邊同時有三層倍率變化,訂閱 Codex 整合 IDE/CLI 的開發者特別要留意,不然一不小心就被扣爆 credit。
第一層:計費單位本身改了。Codex 從 2026-04-02 起計費從 request-based 改成 token-based,還是用「credits」作為單位,但消耗是照 input、cached input、output tokens 的量計算,等同於 API。
第二層:模型間 credit 倍率。GPT-5.5 在 Codex 內每 token 消耗的 credits 是 GPT-5.4 的 2 倍,跟 API 漲幅完全一致:
| 模型 | Input credits / 1M tok | Output credits / 1M tok |
|---|---|---|
| GPT-5.4 | 62.5 | 375 |
| GPT-5.5 | 125 | 750 |
第三層:各訂閱方案的訊息數上限(5 小時視窗)。雖然 credit 費率翻倍,OpenAI 在方案的「每 5 小時可發訊息數」上對 GPT-5.5 只是小縮 20–25%,推測是把「5.5 完成任務所需 tokens 更少」的效率加成折進去了。
| 訂閱方案 | GPT-5.4 訊息數 | GPT-5.5 訊息數 |
|---|---|---|
| Plus | 20–100 | 15–80 |
| Pro 5x | 100–500 | 80–400 |
| Pro 20x | 400–2000 | 300–1600 |
| Business | 20–100 | 15–80 |
| Enterprise/Edu | 依 credit 彈性配置,沒有固定訊息數上限 | |
Fast mode 的 2.5x 成本是再乘上去——所以 GPT-5.5 Fast mode = 125 × 2.5 = 312.5 credits/1M input tokens,相當於 GPT-5.4 標準速度的 5 倍。用在互動式 autocomplete、快速答疑很值得;批次 code review、大重構就別開,credits 會燒很快。
題外話:2026-05-31 前 Pro $100 方案有 2x Codex 用量促銷,Pro 5x 變成 Pro 10x(GPT-5.5 訊息數上限 160–800)。重度 Codex 用戶可以把握這段時間。
安全與使用限制
OpenAI 在 System Card 裡特別標註:GPT-5.5 在 Preparedness Framework 下的生物能力與資安能力都被評為 High。這是 OpenAI 內部風險分級最高的等級之一,代表模型具備被濫用於合成生物武器或大規模資安攻擊的潛在能力。
實務上這對開發者會有幾個影響:
- API 先給 partner/enterprise:高風險評級是 API 沒有 day-one 開放的主要原因,要走核准流程
- Trusted Access for Cyber 計畫:資安專業人士可透過這個專用計畫取得能跑 CTF、vulnerability research 這類敏感任務的許可
- Safety fine-tuning 會更緊:拒答率可能比 GPT-5.4 高一點,特別是生物醫學、資安相關問題
一般 coding、知識工作、資料分析用途不受影響,按正常付費流程使用即可。
實務建議與觀察
值得升級的情境
- 長上下文重度使用者:MRCR、Graphwalks 的跳躍幅度意味著 500K+ context 的任務現在才真正可行。原本只能拆分小片送的超長文件可以考慮整份丟
- Agentic coding workflow:Terminal-Bench 2.0 第一,搭配 Codex Fast mode 做 inline 開發體驗會明顯比 5.4 順
- 電腦操作自動化:OSWorld-Verified 78.7% 意味著桌面自動化 agent 可靠性進入堪用門檻
- 科學與資料分析:GeneBench 等新 eval 有明顯提升,研究型用戶值得試
可以先不換的情境
- 成本敏感的批次任務:GPT-5.4 用 $2.5/$15 就能搞定的東西,沒必要為了 5–8 pp 的 benchmark 差異付 2 倍
- 簡單問答:BigLaw 只漲 0.7 pp、CyberGym 只漲 2.8 pp,非極端任務下兩代差距感覺不到
- 已經綁定 Claude 工作流:Opus 4.7 的 Terminal-Bench 只比 5.5 低一點點,工具生態(Claude Code、MCP server)更豐富,沒有急著切過來的理由
- 中文內容為主:這幾個 benchmark 都是英文/code 任務,中文能力 OpenAI 官方沒特別宣稱進步,Gemini 系列在中文場景依然有競爭力
Portfolio 思路
現階段三家主流大模型(GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro)各有強項與價位,全押一家不是最佳解。常見的 portfolio 組合:
- 日常 coding:Claude Sonnet/Opus 4.7(Claude Code 生態最成熟)+ GPT-5.5(處理 Claude 卡住的題目當 fallback)
- 大量批次分析:Gemini 3.1 Pro(低價大 context)+ GPT-5.5(重要任務)
- 長文件處理:GPT-5.5(MRCR 優勢)或 Gemini 3.1 Pro(2M context)看任務類型挑
- 本地/隱私:Gemma 4、Llama 系列(參考 Google AI Studio 免費跑 Gemma 4)
實際怎麼接這些 provider,可以參考前幾篇 Claude Code 搭配本地 Gemma 4、Claude Code 自動化 Routines 這些實戰文,把 GPT-5.5 加進自己的 LLM 工具箱裡不困難。
等 API 開放後的追蹤點
這篇成文時 API 還沒開放,有幾個問題要等 API 上線後才有答案,我列下來做為後續追蹤:
- 實際 tokens 消耗:OpenAI 宣稱 5.5 用比 5.4 少的 tokens 完成相同任務,實質成本倍率是 1.5x 還是 2x 要實測
- Streaming TTFT:同 per-token latency 不代表 first-token 一樣快,要測
- 中文與繁中表現:官方沒披露,但對華文讀者最重要
- Tool use 相容性:接 Claude Code 這類工具時 tool calling 協議是否有 breaking change
- Pro 版到底值多少:$30/$180 是純性能稅還是真的推理強到會有對應 ROI 的場景
整體看下來 GPT-5.5 這代是 OpenAI 自 GPT-5 以來最「有感」的升級,長上下文兩個 benchmark 的跳躍尤其接近代差。但代價是 API 價格翻倍,加上發表當天沒開 API,短期內真正能拿到的是 ChatGPT 與 Codex 訂閱戶。熱度會在 API 開放後重新起一波,有興趣的開發者可以現在就去申請 API 等待名單、在 ChatGPT 裡先用 Thinking 模式摸索 prompt 風格,等 API 開放就能無縫接上。寫這篇的時候離發表才一天,後面一兩週各家第三方 review 會陸續出,值得持續追蹤。