
Anthropic 在 2026 年 5 月 28 日正式推出 Claude Opus 4.8,距 Opus 4.7 發表只有六週。價格維持與 4.7 相同的 input $5 / output $25 每 1M tokens,但帶來三個比較有感的改動:程式可信度提升(官方說的是「把 code 裡的 flaw 放過不評論的機率比 4.7 少 4 倍」)、Claude Code 新增 Dynamic Workflows 同時可以跑數百個平行 subagent 處理 codebase 級的遷移,以及 Fast Mode 跑得 2.5 倍快、收費比上代 Fast Mode 便宜三倍。
這篇文章把 Opus 4.8 跟 4.7 的差異、與 Sonnet 4.6/Haiku 4.5/GPT-5.5/Gemini 3.1 Pro 的價格對照、Benchmark 表現、API 與 Claude Code 端的新行為,以及升級時要注意的小細節一次整理起來。
Claude Opus 4.8 是什麼
Opus 4.8 是 Anthropic 三條產品線(Haiku、Sonnet、Opus)裡的旗艦,定位處理最複雜的推理、agent 任務與長時間 coding 工作流。Claude 的 Pro、Max、Team、Enterprise 訂閱方案都已同步可用,模型 ID 是 claude-opus-4-8;要走 API 的話,Claude API、Amazon Bedrock、Google Vertex AI 與 Microsoft Foundry 也都同時上架。在 Microsoft Foundry 上 context window 是 200K,其他平台都是 1M tokens。
Anthropic 這次強調的是「更可靠的協作者」。官方原文是 “early testers have found Claude Opus 4.8 to be more reliable and sharper in its judgement when it’s performing agentic tasks“,重點放在長任務維持、agent 行為穩定度、以及對自己作品的誠實度。整體 benchmark 還是有進步,但這代真正想推的方向是「跑 agent 跑得久跑得穩」。
快速比較
先用三張表把開發者最常關心的項目對齊:跟前一代 Opus 4.7 的差異、跟同代 Sonnet 4.6/Haiku 4.5 的分工,以及跟 OpenAI、Google 旗艦的定價對照。
與 Opus 4.7 的差異
| 項目 | Opus 4.7 | Opus 4.8 |
|---|---|---|
| 模型 ID | claude-opus-4-7 | claude-opus-4-8 |
| Input 價格 | $5 / 1M tokens | $5 / 1M tokens |
| Output 價格 | $25 / 1M tokens | $25 / 1M tokens |
| Context window | 1M tokens | 1M tokens |
| Max output(同步 API) | 128K tokens | 128K tokens |
| Max output(Batch API beta) | 300K tokens | 300K tokens |
| Adaptive thinking | 有 | 有 |
| Effort 預設值 | Claude Code 預設 xhigh | 所有 surface 預設 high |
| Fast Mode | 無 | 新增,2.5× 速度,$10 / $50 每 1M tokens |
| Dynamic Workflows | 無 | Claude Code 新增(Enterprise/Team/Max) |
| Messages API system 訊息 | 只能放在 system 欄位 | 可放進 messages array 中段插入 |
| 知識截止 | 2026-01 | 2026-01 |
價格、context window、max output 與知識截止這幾條完全沒動,等於現有的成本估算模型可以直接沿用。比較值得展開講的是 Fast Mode、Dynamic Workflows、effort 預設值改變這三件,後面分別說。
Claude 同代產品線價格比較
把 Opus 4.8 跟同代的 Sonnet 4.6、Haiku 4.5 擺在一起,比較容易看出該選哪一條。所有單價都是每 1M tokens 美元,long context 在 Anthropic 這邊已經不再額外加價。
| 模型 | Input | Output | Context | Max output | 定位 |
|---|---|---|---|---|---|
| Opus 4.8(Fast Mode) | $10 | $50 | 1M | 128K | 2.5× 速度,延遲敏感場景 |
| Opus 4.8(一般模式) | $5 | $25 | 1M | 128K | 旗艦,複雜推理與長任務 agent |
| Opus 4.7 | $5 | $25 | 1M | 128K | 上一代旗艦,仍可使用 |
| Sonnet 4.6 | $3 | $15 | 1M | 64K | 速度與智能平衡,多數日常任務 |
| Haiku 4.5 | $1 | $5 | 200K | 64K | 最快、成本敏感場景 |
把表格的 input 單價畫成隨輸入 token 數變化的線圖,相對成本差距更直觀。和前面三家旗艦那張不同,這四條都是從原點出發的直線——因為 Anthropic 全段同費率、沒有長 context 跳階,斜率本身就是每 1M tokens 的 input 單價:
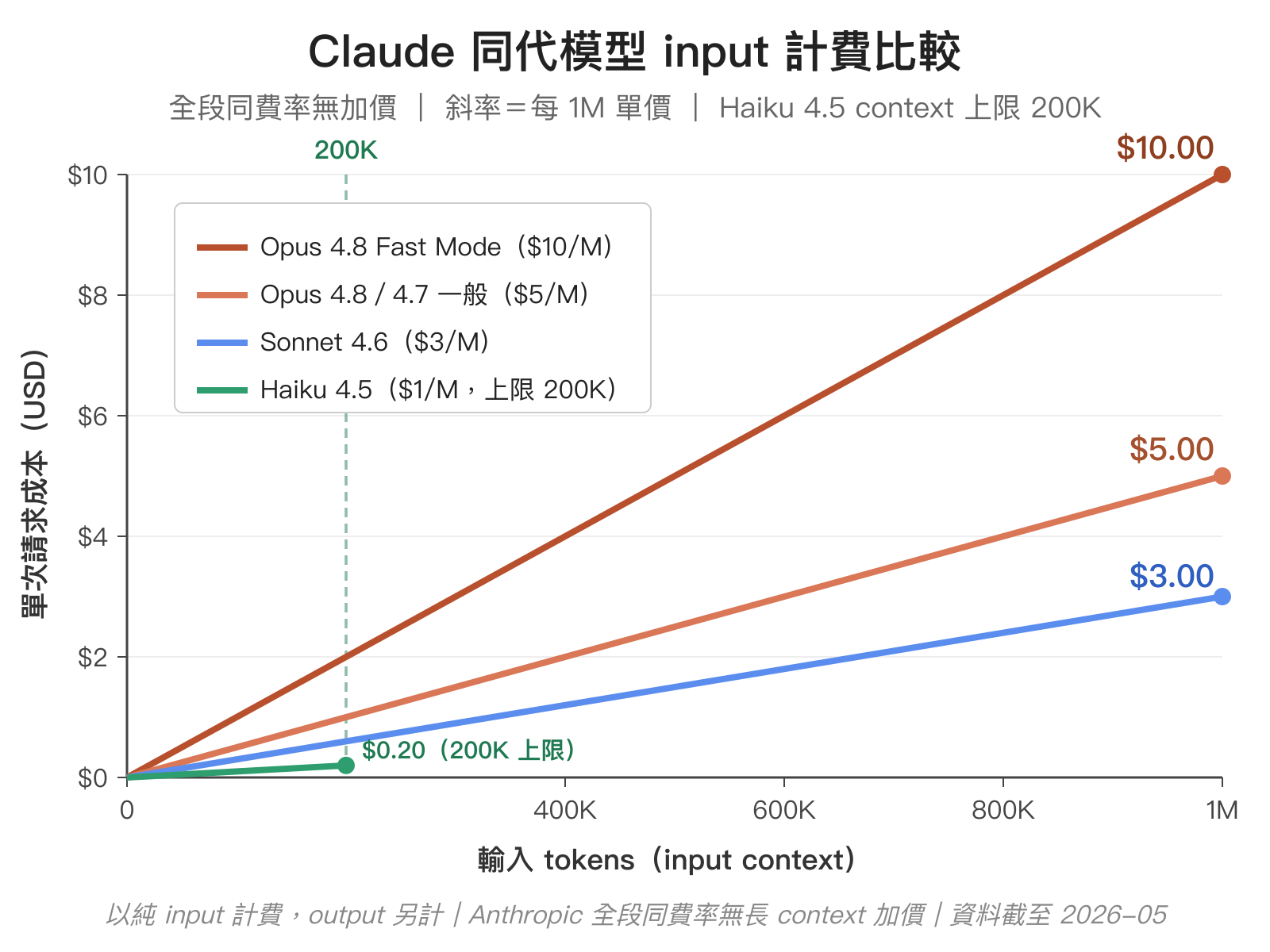
Opus 4.8 跟 Sonnet 4.6 的單價差是 input 1.67×、output 1.67×,跟 Haiku 4.5 比則是 5×。一個務實的判斷標準:如果任務 Sonnet 4.6 跑得起來而且品質夠用,沒必要硬切到 Opus 4.8 多付錢;只有在 long-horizon agent、複雜 codebase migration、需要極高可信度的場合,Opus 4.8 的價格差才換得回來。
Prompt caching(命中省 90%)與 Batch processing(非即時省 50%)在 4.8 全線都繼續支援,這兩個機制疊上去之後實際帳單會比表格上的單價低不少。
與 OpenAI、Google 對照
把同期三家旗艦模型放在一起看,定價策略的差異比較直觀:
| 模型 | Input | Output | Context | 長 context 加價 |
|---|---|---|---|---|
| Claude Opus 4.8 | $5 | $25 | 1M | 無,全段同費率 |
| Claude Opus 4.8 Fast Mode | $10 | $50 | 1M | 無,全段同費率 |
| OpenAI GPT-5.5 | $5 | $30 | 1M | > 272K input 改 2× input / 1.5× output |
| OpenAI GPT-5.5 Pro | $30 | $180 | 1M | 同上規則 |
| Google Gemini 3.1 Pro | $2 | $12 | 1M | > 200K input 改 $4 / $18 |
單看表格不容易感受到「長 context 加價」實際影響有多大,把三家旗艦的 input 計費畫成隨輸入 token 數變化的線圖會比較直觀:
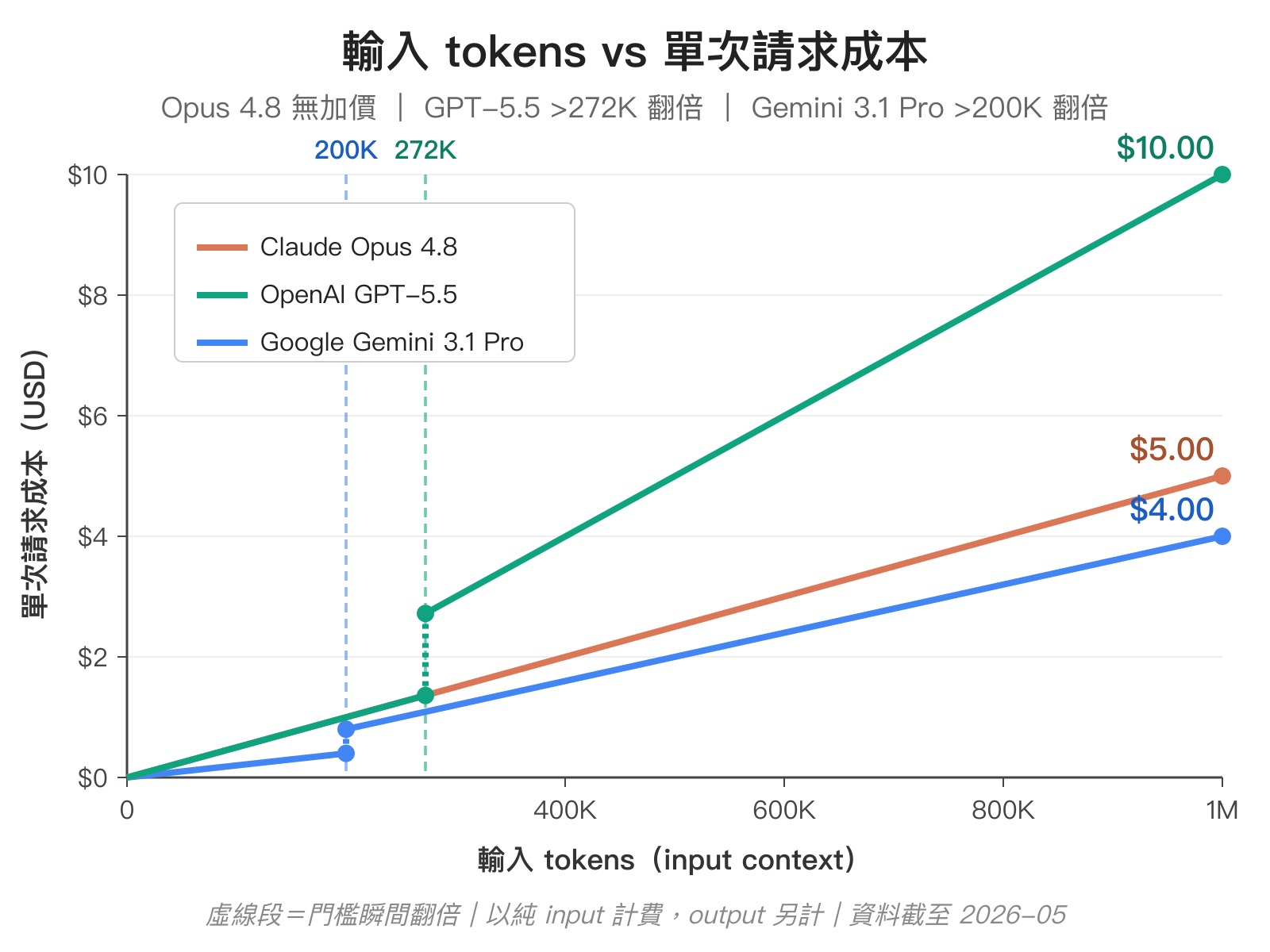
注意 GPT-5.5「超過 272K」的計價方式!OpenAI 官方文件寫的是 “prompts with >272K input tokens are priced at 2x input and 1.5x output for the full session“。一旦 input 超過 272K,整段 input 從第 1 個 token 開始全部重新計價,不是只把超過 272K 的部分加價。
實際差異很顯著:輸入 272K tokens 整段以 $5/M 計,成本約 $1.36;輸入 273K tokens 整段以 $10/M 計,成本立刻變成 $2.73,瞬間翻倍。圖中 272K 那條垂直虛線就是這個 session-wide 跳價的瞬間。Gemini 3.1 Pro 在 200K 的加價規則邏輯一樣。原始規則可以在 OpenAI API Pricing 與 Gemini Developer API Pricing 找到。
從這張圖可以一眼讀出幾個值得停下來看的點:
- Input 單價:Gemini 3.1 Pro 最便宜($2),Opus 4.8 與 GPT-5.5 同價($5),GPT-5.5 Pro 最貴($30)
- Output 單價:Gemini 3.1 Pro 一樣最低($12),Opus 4.8 次之($25),GPT-5.5 標準版 $30,Pro 版 $180
- 長 context 計費:Anthropic 從 Opus 4.6 開始就統一不加價,整段 1M 都同費率;OpenAI 在 272K、Google 在 200K 之後就會切成更貴的長 context 區段,而且是從第一個 token 開始重新計費
- Opus 4.8 vs GPT-5.5:短 context 下 input 同價($5)、output Anthropic 便宜 17%($25 vs $30);一旦 input 超過 272K,GPT-5.5 整段 input 重計 $10,1M 時是 $10 vs Opus 4.8 的 $5,差距正好翻倍。長 prompt 工作流 Opus 4.8 帳單會明顯比 GPT-5.5 低
- Gemini 3.1 Pro 仍是最便宜的選項:在能力夠用的場景下,光是 input/output 單價就比 Opus 4.8 便宜一半以上;要選 Opus 4.8 通常是因為 agent 行為、誠實度、Claude Code 整合這些 Gemini 還沒對齊的點
另外要提的是 GPT-5.5 在 Opus 4.8 發表前剛經歷一次明帳漲價,標準版從 GPT-5.4 的 $2.5 / $15 一口氣翻倍到 $5 / $30,這部分背景可以參考之前寫過的 GPT-5.5 發表整理。Anthropic 這次 Opus 4.8 維持與 4.7 同價,沒有跟進漲價節奏。
程式可信度大幅提升
這代最被強調的改動是誠實度。Anthropic 在公告裡用的數字是「Opus 4.8 比 4.7 大約少 4 倍機率把自己寫的 code 裡的 flaw 放過不評論」。意思是當模型在寫完 code 後做自我檢查時,更願意主動指出有問題的地方,而不是默默讓 bug 滑過去。
原文是 “around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked”,另外早期測試者回饋的整體現象是「more likely to flag uncertainties about its work and less likely to make unsupported claims」——對自己沒把握的地方會講出來,比較不會硬編一個看起來合理但其實沒根據的答案。
這件事對長時間 agent 工作流影響很大。過去 4.6 / 4.7 在跑長任務時偶爾會出現一種狀況:模型寫完 code、跑了測試、測試失敗,但結論卻寫成「完成」交回來。實際上是 hallucination 跟 over-confidence 的混合症狀。Opus 4.8 在這方面被刻意校準過,對於依賴模型自我評估結果的 pipeline(例如 CI 裡接 Claude Code、或者自動 PR 審查)會比較放心。
不過要注意,「少 4 倍」是相對於 4.7 的比例,不是絕對保證——關鍵的程式碼還是建議搭配 lint、測試與真人 code review 作為最後一道防線,模型對自己的評估再準也只是輔助。
Claude Code 的 Dynamic Workflows
Claude Code 端最大的新功能叫做 Dynamic Workflows,目前以研究預覽(research preview)形式開放給 Enterprise、Team、Max 方案。簡單講,這是讓 Claude Code 在單一 session 內可以同時跑數百個平行 subagent,自動把大任務拆解、分派、收集結果,然後回到主對話彙整結論。
Anthropic 給的典型場景是「codebase-scale migrations across hundreds of thousands of lines of code from kickoff to merge」——也就是跨數十萬行 code 的大型遷移,從動工到 merge 都可以由 Claude Code 自己跑完。例如:
- 把整個 monorepo 從 ESLint 9 升到 ESLint 10,每個 package 一個 subagent 平行修
- 把整個專案的單元測試從 Mocha 改用 Vitest 重寫,每個檔案一個 subagent
- 跨數千個 endpoint 補上同樣模式的 input validation,平行掃 + 平行改 + 平行跑測試
過去這種任務在 Opus 4.7 上其實也能跑 subagent,差別在於 4.7 時代的 subagent 通常是序列觸發、規模不大、生命週期偏短;4.8 的 Dynamic Workflows 是把這件事 productize,讓主模型自己決定要不要拆、要拆幾個、各自跑多久,並且系統面也撐得住長時間運作。對需要做 codebase-scale 修改的團隊來說,這是這代 Opus 升級最有感的部分。
關於 subagent 的細節與一般 Claude Code 用法可以參考之前寫過的 Claude Code Skills 介紹 與 Claude Code 效能事後檢討,這邊不再重複展開。
Effort 控制與 Fast Mode
claude.ai 上的 Effort 選單
過去 effort level(low/medium/high/xhigh/max)只有 API 與 Claude Code 看得到,這代 Anthropic 把它端到 claude.ai 與 Cowork 的 UI 上:模型選單旁邊多了一個控制條,使用者可以決定 Claude 對每次回應投入多少 effort。
官方對選項的描述是「higher effort 讓 Claude 想得更頻繁、更深;lower effort 讓 Claude 回得更快、rate limit 也耗得更慢」。對日常聊天類的問題,調低一點可以省 rate limit;對複雜推理或 coding 任務,調高就是預期會等久一點、token 也吃多一點,換來品質。
Effort 預設值改變
有一個容易忽略但會直接影響帳單的改動:Opus 4.8 的 effort 預設值在所有 surface(Claude API、Claude Code、claude.ai)統一改為 high。Opus 4.7 時代 Claude Code 預設是 xhigh,所以直接從 4.7 切到 4.8 的開發者,會發現預設 token 消耗變少、但反應時間也變快。
如果原本依賴 4.7 上 xhigh 的深度思考行為,記得在 API 或 Claude Code 設定裡明確把 effort 指定為 xhigh 或 max,否則行為會默默變成 high 等級。
Fast Mode:2.5× 速度、3× 便宜
Fast Mode 是 Opus 4.8 新增的執行模式,跑得比一般模式快 2.5 倍,並且收費比過去 Anthropic 的 Fast Mode 便宜 3 倍。Opus 4.8 Fast Mode 的單價是:
- Input:$10 / 1M tokens
- Output:$50 / 1M tokens
對比 Opus 4.8 一般模式的 $5 / $25,Fast Mode 大約是 2 倍價格換 2.5 倍速度——對延遲敏感的場景(例如 IDE 內即時 completion、客服機器人、需要即時 streaming 回應的 web 應用)是划算的選項。如果工作流本來就是非同步 batch 為主,繼續走一般模式比較省。
Benchmark 表現
Anthropic 在公告頁附了一張四個模型的對照表,把 Opus 4.8 跟 Opus 4.7、GPT-5.5、Gemini 3.1 Pro 放在 coding、agent、推理與知識工作幾類任務上比較。整理成表格如下,HLE 分成有無工具兩種設定,GDPval-AA 是 Elo 分數、其餘為百分比:
| Benchmark | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro | 評測說明 |
|---|---|---|---|---|---|
| Agentic coding(SWE-Bench Pro) | 69.2% | 64.3% | 58.6% | 54.2% | 解真實 GitHub 專案的軟體工程任務(修 bug、加功能),改完要通過測試 |
| Agentic terminal coding(Terminal-Bench 2.1) | 74.6% | 66.1% | 78.2% | 70.3% | 在終端機環境內用 shell/CLI 指令完成多步驟任務 |
| Multidisciplinary reasoning(HLE,無工具) | 49.8% | 46.9% | 41.4% | 44.4% | 跨學科高難度學術題,測純推理廣度,不給外部工具 |
| 同上(含工具) | 57.9% | 54.7% | 52.2% | 51.4% | 同一份題目,但允許呼叫搜尋、程式執行等外部工具 |
| Agentic computer use(OSWorld-Verified) | 83.4% | 82.8% | 78.7% | 76.2% | 直接操作真實電腦桌面(點按、輸入、跨 app 切換)完成任務 |
| Knowledge work(GDPval-AA) | 1890 | 1753 | 1769 | 1314 | 模擬真實知識工作的產出品質,由人類偏好評比換算成 Elo 分數 |
| Agentic financial analysis(Finance Agent v2) | 53.9% | 51.5% | 51.8% | 43.0% | 金融分析 agent 任務:讀財報、估值、做投資分析 |
幾個值得停下來看的點:Opus 4.8 在七個項目裡有六項居首,其中 SWE-Bench Pro 從 4.7 的 64.3% 拉到 69.2%、GDPval-AA 從 1753 跳到 1890(領先第二名 GPT-5.5 的 1769 超過一百分),是進步幅度最明顯的兩項。OSWorld-Verified 的 83.4% 代表它直接操作電腦完成現實任務的能力,對想做瀏覽器 agent 或 RPA 類產品的開發者來說,這個分數比純 coding benchmark 更貼近實際表現。
唯一沒拿下第一的是 Terminal-Bench 2.1:Opus 4.8 的 74.6% 輸給 GPT-5.5 的 78.2%。這項評估的是在終端機環境裡完成多步驟任務的能力,意味著純 shell/CLI 操作密集的工作流,GPT-5.5 目前仍保有優勢。
除了這張對照表,官方系統卡另外列了傳統評測的成績,例如 SWE-bench Verified 88.6%、GPQA Diamond 93.6%,可在 官方公告 與系統卡查到。Anthropic 也在客戶回饋段落引用了幾個第三方 benchmark 數字——Online-Mind2Web 達 84%、Legal Agent Benchmark 成為第一個在 all-pass 標準突破 10% 的模型——這些屬於 testimonial 引用,與上面的官方主對照表分開看會比較準確。
Messages API 的小改動
API 層面 4.8 有一個對長 agent 場景滿實用的改動:Messages API 允許 system 訊息插在 messages array 中間。原文是 “the Messages API now accepts system entries inside the messages array. Developers can update Claude’s instructions mid-task without breaking the prompt cache.”
過去想在對話中途改 system prompt,要嘛整個 system 欄位重寫,要嘛塞 user 訊息假裝是新指令。前者會破壞 prompt cache,後者語意上比較難看。4.8 之後可以直接在 messages array 中段插入 {"role": "system", "content": "..."},告訴模型「從這一輪開始指令變成 X」,而且不影響上面的 cache hit。
典型用法包括長 session 中切換任務階段(例如從「規劃」切到「執行」)、agent 在發現新限制條件時即時加進 system context、或是 RAG 場景下隨任務階段切換不同的 instruction set。對於有複雜 prompt cache 策略的 production 工作流,這是省 token 的好東西。Prompt caching 本身的省錢機制可以參考之前寫過的 Claude Code Token 省錢與 Cache 指南。
如何開始用
Opus 4.8 已經「available everywhere today」,但不同 client 拿到 4.8 的時間點略有落差,依入口分開說明。
網頁與手機 App
Claude Pro/Max/Team/Enterprise 訂閱者在 claude.ai 上直接就能用,這次模型選單旁多了一個 effort 控制條可以調投入強度。實測兩個 client 的拿到 4.8 的方式:
- 網頁版(claude.ai):重新整理頁面,模型選單就會出現 Opus 4.8
- 手機 App(iOS/Android):從 App Store/Play 商店把 app 更新到最新版本、重啟一次後即可選用
Claude Code
個別開發者最主要的 Opus 4.8 入口是 Claude Code,升級流程很短。在終端機直接執行:
# 更新 Claude Code 到最新版本
claude update
# 確認版本(4.8 預設需要 v2.1.x 以上)
claude --version更新完之後重新進 Claude Code,啟動畫面就會直接寫上 Opus 4.8 已是預設模型。下面這張是 v2.1.154 的歡迎畫面:
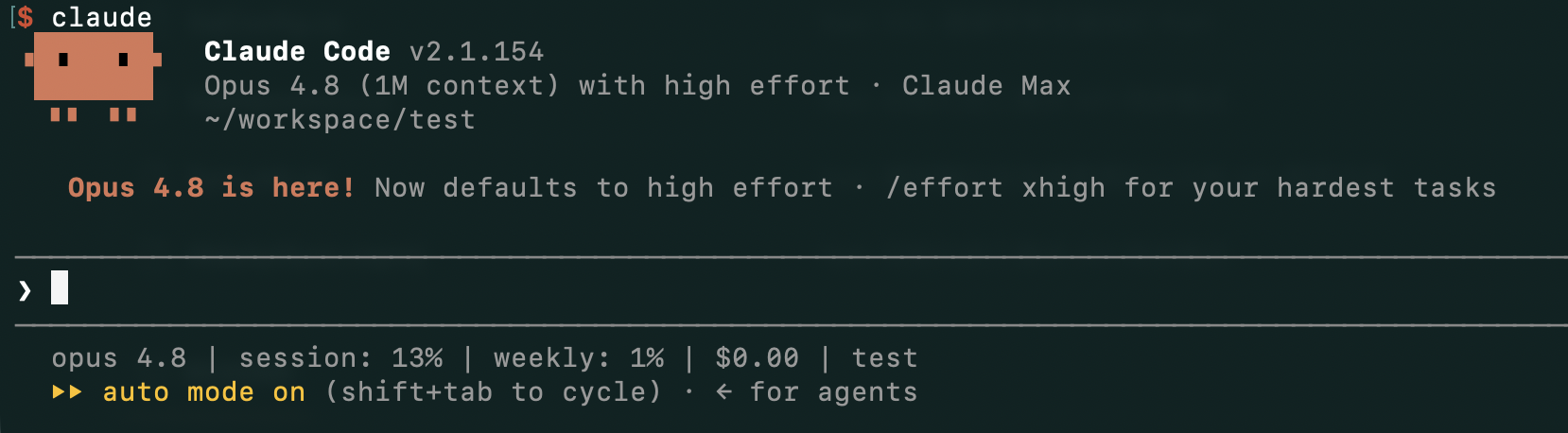
幾個從歡迎畫面與底部狀態列可以一眼讀出的訊息:
- Opus 4.8(1M context)with high effort:升完版開新 session 預設就是 4.8、1M 上下文、high effort,不需要額外設定
- 「Now defaults to high effort · /effort xhigh for your hardest tasks」:Claude Code 自己會在歡迎詞提示,effort 已經從 4.7 時代的
xhigh降為high。遇到真的需要深度思考的任務,直接打/effort xhigh切換即可 - 底部狀態列
opus 4.8 | session: 13% | weekly: 1% | $0.00:這行是自製的 statusline,把目前模型、本次 session 用量、週用量、累計花費即時印出來,方便評估升級到 4.8 之後實際成本變化。設定方式與腳本可以參考之前寫過的 Claude Code 節省 Token 與快取指南,裡面有完整的~/.claude/statusline.sh範例
另外 Enterprise/Team/Max 方案在 Claude Code 裡會看到 Dynamic Workflows 的選項,個人 Pro 方案目前還沒有。如果想暫時回到 4.7 比對行為(例如 prompt 原本針對 4.7 微調),可以用 /model 指令切換到 claude-opus-4-7,無需重新啟動。Claude Code 入門與常用功能可以參考之前寫過的 Claude Code 入門使用教學。
Claude Desktop
Claude Desktop(macOS/Windows 桌面版)的拿到 4.8 的方式:
- 非最新版:先把 Claude Desktop 更新到最新版本
- 已是最新版:直接重啟程式,模型選單就會出現 Opus 4.8
其他平台
走 API 或雲端平台的部分一次列出來:
- Claude API:把
model欄位設成claude-opus-4-8。預設 effort 是high,要更深的請求記得明確指定xhigh或max - Amazon Bedrock:透過 Claude in Amazon Bedrock(Messages-API endpoint)使用
anthropic.claude-opus-4-8 - Google Vertex AI:model ID 為
claude-opus-4-8 - Microsoft Foundry:可使用
claude-opus-4-8,但 context window 在 Foundry 上是 200K(其他平台是 1M),有長 context 需求要注意
Opus 4.7 沒有被立刻下架,仍可繼續使用 claude-opus-4-7,所以線上環境如果有依賴 4.7 行為(特別是預設 xhigh effort 的 Claude Code 工作流)暫時不會被強制切換。但建議在升級到 4.8 前先把 effort 預設值改變、Messages API 行為這幾個變動跑過一輪測試,避免成本或行為的微小差異累積成大問題。
對使用者的意義
把 Opus 4.8 的改動攤開看,方向其實很清楚:Anthropic 把焦點放在「讓 Claude 變成可信任的長時間協作者」這件事上。誠實度提升、Dynamic Workflows、effort 預設改為 high 而不是 xhigh、Messages API 支援 mid-task 指令更新,再加上 effort 控制條端到 claude.ai——這些加起來,受影響的已經不只是工程師。以下按角色拆開看實際差別在哪。
- 軟體開發者:日常 coding 從 4.7 切到 4.8 的體感變化不大——畢竟價格、context、max output 都沒動。真正有感的是寫完 code 後的自我檢查更願意主動指出問題(誠實度 4 倍改善),對於把 Claude Code 接進 CI、或拿來做自動 PR 審查的 pipeline 會比較放心。
- 跑 production agent 的團隊:誠實度提升疊上 Dynamic Workflows,是這代最值得直接切換的理由——可以放心把它丟進連續跑數小時、跨上百個檔案的 codebase 級遷移,而且結果可以被相信。
- 延遲敏感的應用開發者:Fast Mode 用 2.5 倍速把過去高延遲的 Opus,變成能放進 IDE 即時補完、客服機器人、即時 streaming 回應這類互動場景的選項。
- 知識工作者(寫作、研究、簡報):claude.ai 新增的 effort 控制條讓投入強度可調——日常問答調低一點省 rate limit、複雜任務調高換品質;GDPval-AA 從 1753 跳到 1890,也反映在實際知識工作產出的品質上。
- 金融、法律等專業使用者:Finance Agent v2 與 Legal Agent Benchmark 的進步,代表它在讀財報、估值、法律文件分析這類專業 agent 任務上更堪用;不過高風險決策仍建議搭配真人覆核,模型的自我評估再準也只是輔助。
- 行政、營運與 RPA 場景:OSWorld-Verified 的 83.4% 對應的是直接操作電腦桌面(點按、輸入、跨 app 切換)的能力。對每天在沒有 API 的軟體裡做重複操作的職務——跨系統登打資料、報表整理、在老舊內部系統查詢與更新——這意味著過去要養一套綁死按鈕位置、畫面一改就壞的 RPA 腳本,現在可以改用看畫面臨機應變的 agent 來處理。
- 單純當高品質 LLM 用的使用者:沒有要做 agent、也不在意延遲的話,繼續用 4.7 是合理的選擇——沒有強制要升,功能也不會少。新模型發佈不一定都要立刻全面切換,這次特別如此。
參考資料
- Introducing Claude Opus 4.8 — Anthropic 官方發表公告,含誠實度、Dynamic Workflows、Fast Mode 與 Online-Mind2Web/Legal Agent/Super-Agent 等 benchmark 的官方說法
- Models overview — Claude API Docs — 模型 ID、context window、max output、各雲端平台 ID 與 effort 預設值說明
- OpenAI API Pricing — GPT-5.5 標準版與 Pro 的單價、長 context(> 272K)加價規則
- Gemini Developer API Pricing — Gemini 3.1 Pro 標準與長 context(> 200K)的計費資訊