
手邊同時開著 Claude Code 跟 OpenAI Codex 的開發者越來越多,兩個工具用久了難免會冒出疑問:它們背後的 prompt cache 是不是同一套東西?畢竟兩邊都是「對話越長、帳單越高」,也都靠快取把重複送進去的內容壓低成本。快取的骨架幾乎一樣,但計價結構與自動化程度差很多,這些差異會直接反映在每個月的帳單和使用習慣上。
關於 Claude Code 這邊的快取怎麼運作、什麼操作會打斷快取、怎麼用 statusline 監控,先前已經整理過一篇完整的 Claude Code 節省 Token 與快取指南 ,這篇就不再重講細節。兩家共通的原理只占一小節,重點留給「Codex 與 Claude Code 不一樣的地方」。
兩家共通的快取原理
什麼是快取
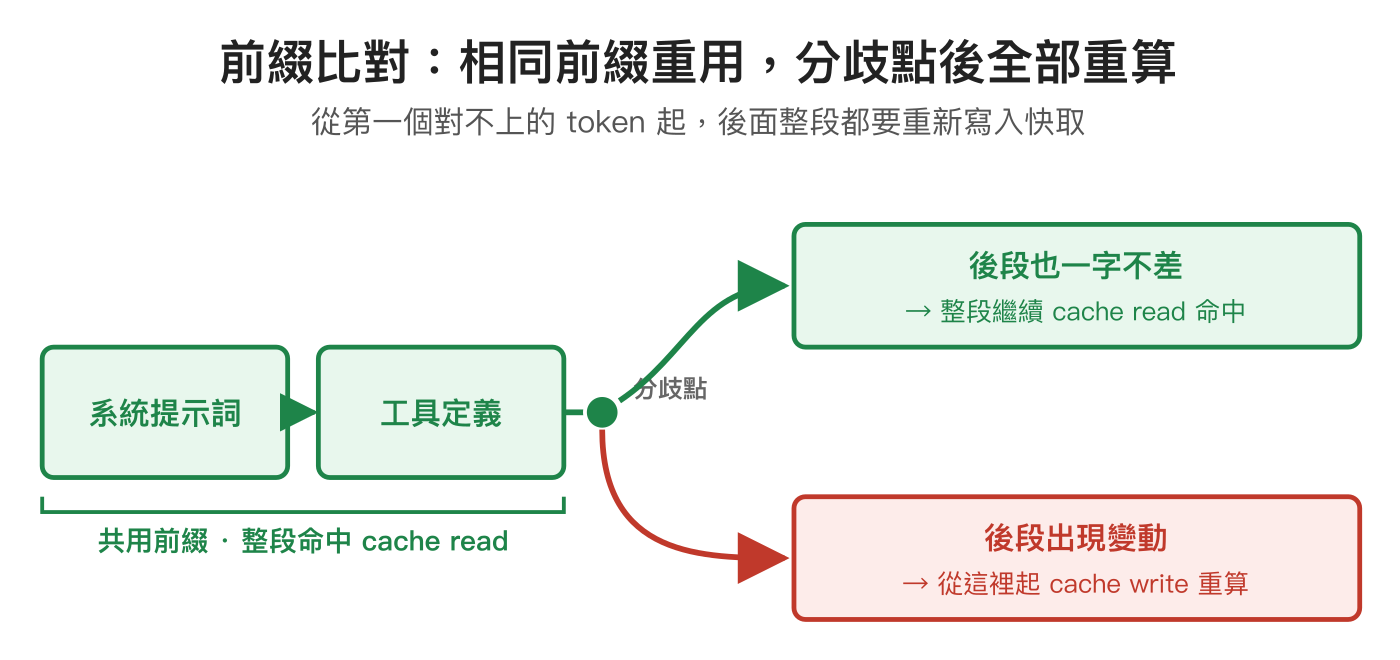
不管是 Anthropic 還是 OpenAI,prompt cache 的核心機制是同一套前綴比對(prefix matching):伺服器把每次送進去的 prompt 從頭往後切,下一次請求進來時從第一個 token 開始比對,對得上的前綴直接用快取的便宜價結帳,從第一個對不上的位置往後就全部重算並寫入新快取。這也是為什麼兩個工具都有同一個鐵則——前綴只要動到一個字,後面整段就全部失效。改了系統指令、調了工具定義、在開頭插一段會變動的內容,都會讓那一輪的快取從變動點崩掉。
為什麼快取一定是「前綴」而不能是「任意片段」?這跟語言模型的運算方式有關:模型在讀一段 prompt 時,每個 token 的內部狀態都是建立在它前面所有 token 之上算出來的——前文只要變了,後面每個 token 的狀態就跟著不同。所以只有「從開頭到某個位置完全一字不差」的那段前綴,先前算好的中間結果才能原封不動拿回來重用;一旦中間某個 token 被改動,從那裡往後每一個 token 都得重新計算。這就是「動到前綴、後面整段失效」的根本原因,也是兩家不約而同都做成前綴快取、而不是任意比對片段的設計背景。快取真正省下的,是這段內容「重新計算」的算力,計費上的折扣只是把省下的運算反映到帳單而已。
另一個共通點是快取會過期。兩家都採「活躍時延長、閒置時清掉」的精神:有請求持續命中就把存活時間往後續,放著沒人戳超過一段時間,整段快取就被回收,回來第一句一定 miss。連最低門檻都很接近,兩邊都要累積到一定 token 量(常見是 1,024 tokens)才會開始快取,太短的內容不進快取也不會報錯。
如何保持快取
理解這點之後,會帶出一個對兩家都適用的擺放原則:越固定不變的內容放越前面,越會變動的內容放越後面。系統指令、工具定義這種每輪幾乎一樣的東西擺在最前面,被重複命中、省下重算的機會就最高;反過來,像時間戳、每次不同的識別碼、隨對話增長的歷史這類會變的內容要盡量往後放——把它們塞在前段,等於每一輪都親手把後面整段快取打掉。Claude Code 與 Codex 在內部組裝請求時都遵循這個原則,前一篇提到「編輯 CLAUDE.md 會打斷快取」,正是因為 CLAUDE.md 被放在很靠前的位置,動它一個字,後面所有內容都得重算。
所以從「概念骨架」來看,理解了其中一個,另一個的大方向就懂了。Claude Code 與 Codex 也都是靠「讓前綴保持穩定」來吃快取——把固定的系統指令、工具定義放前面,新訊息往後接,而不是去改前面已經送過的內容。真正的分歧在底下三個地方。
三個關鍵差異
觸發方式:手動標記 vs 全自動
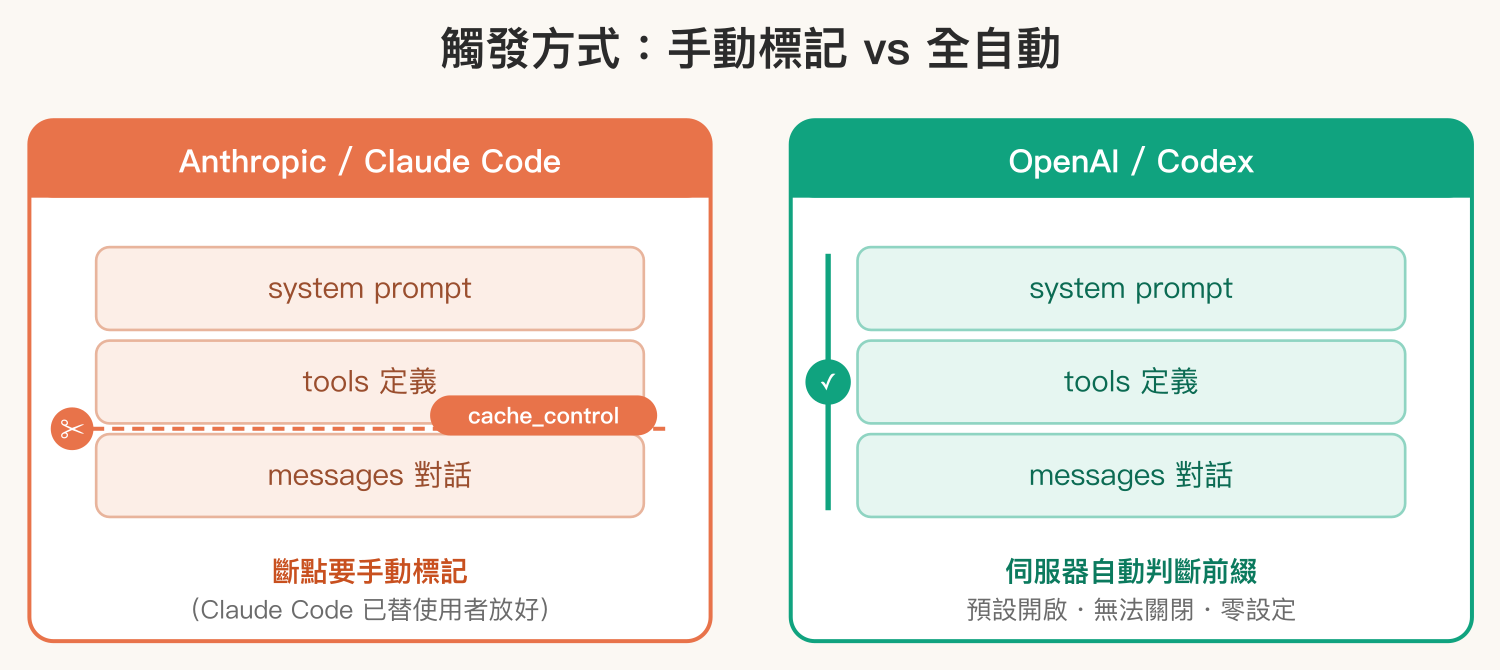
第一個差異藏在最底層的 API 設計。Anthropic 的快取預設不會自己發生,呼叫端要在請求裡明確標出 cache_control 這個記號,告訴伺服器「從這裡以前的內容請快取起來」,最多可以放四個這種斷點。這代表直接打 Anthropic API 的開發者得自己規劃斷點要擺哪。好消息是用 Claude Code 的人完全不必管這件事——Claude Code 在組每一輪請求時已經把斷點放好了,前一篇指南裡也因此完全沒提到要手動設定什麼。
OpenAI 這邊更徹底:根據 官方文件 ,prompt caching「對所有 API 請求自動生效,不需要改任何程式碼」,而且預設開啟、無法關閉。連 cache_control 這種欄位都不用傳,伺服器自己判斷哪段前綴可以重用。換句話說,Anthropic 的「自動」是 Claude Code 幫使用者把手動的事做掉了;OpenAI 則是從 API 層就是真正的全自動。
計價結構:讀取折扣相同,差別在寫入
這是兩家最有感、也最影響帳單的差異。回顧一下計價會拆成三塊:沒命中的 fresh input、寫入快取的 cache write、命中讀回的 cache read。關鍵在後兩塊的單價。
Anthropic 的 cache read 只要標準輸入價的 10%(1 折),命中之後便宜很多;但代價是 cache write 要額外加價——5 分鐘 TTL 的寫入是標準輸入的 1.25 倍,1 小時 TTL 更是 2 倍。也就是說,每次把新內容寫進快取,要先付一筆比原價還貴的「寫入稅」,之後靠後續的便宜命中把它賺回來。
OpenAI 的命中折扣一樣低:根據 官方文件 ,現行的 GPT-5.x 系列模型(Codex 跑的就是這一支)cache read 同樣是標準輸入價的 10%(1 折),跟 Anthropic 一模一樣。真正不同的在寫入端——OpenAI 的 cache write 不額外收費,就用標準輸入價,沒有 Anthropic 那種寫入溢價。命中一樣便宜,但 OpenAI 連寫入都不必先繳那筆「寫入稅」。
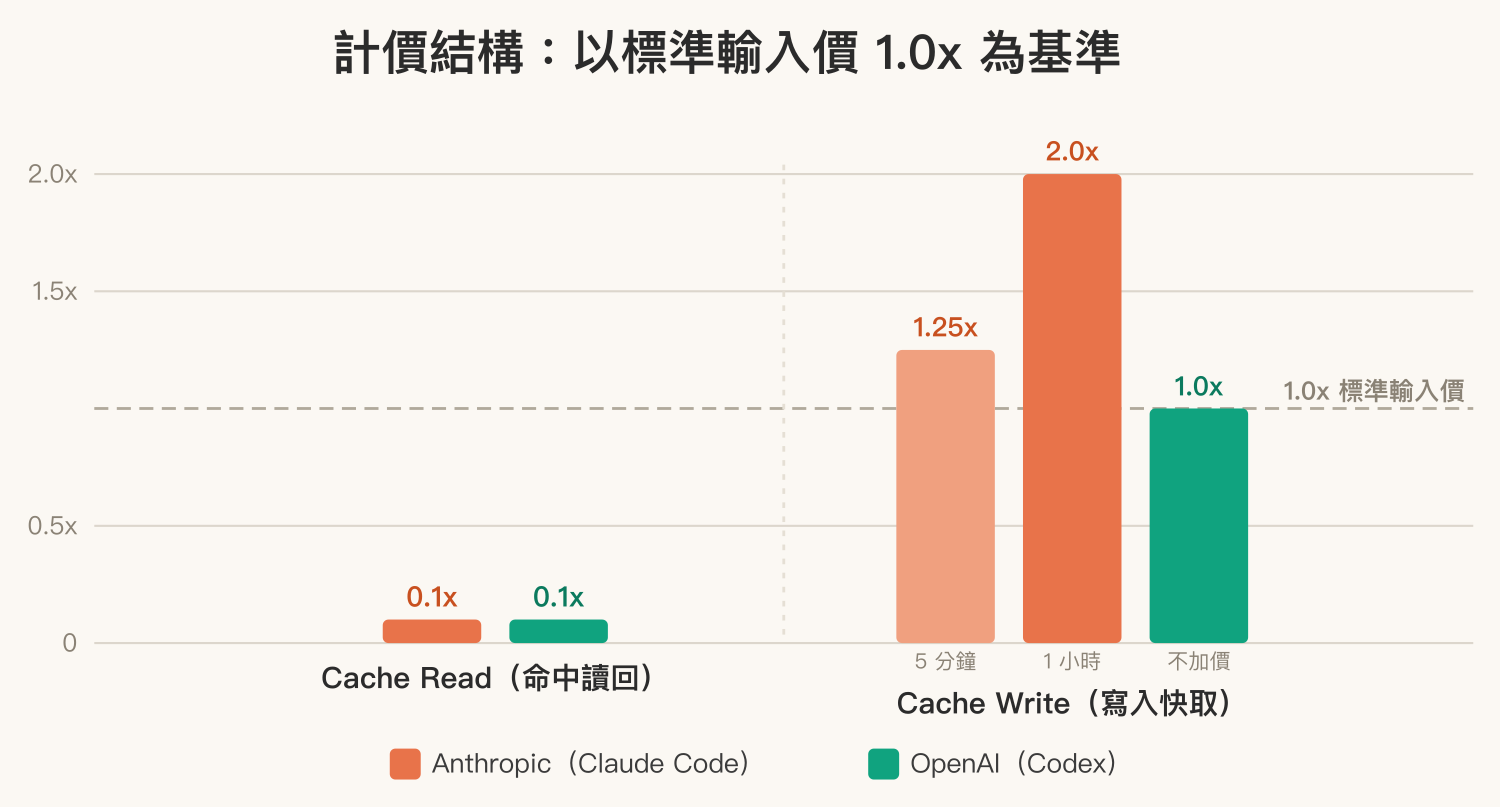
這個差異該怎麼解讀?既然命中折扣兩家相同,計價上的差別就集中在寫入端。Anthropic 每寫一次快取都要先繳 1.25x/2x 的寫入稅,得靠後續夠多次的便宜命中才回本;一段前綴若會被大量重複命中(長時間在同一個 session 連續工作、固定的系統指令被反覆讀取),這筆寫入稅攤下來就不明顯。但工作型態若偏向頻繁開新對話、前綴很少被重複利用,寫入稅就難回本,這種零碎場景下 OpenAI 寫入免費的結構負擔更輕。單看快取計價的倍率結構,OpenAI 少了寫入溢價是它佔優的地方;至於每月帳單實際誰高誰低,還要看兩邊模型本身的輸入單價,那是另一個層次的比較。
TTL:固定兩段 vs 浮動衰減
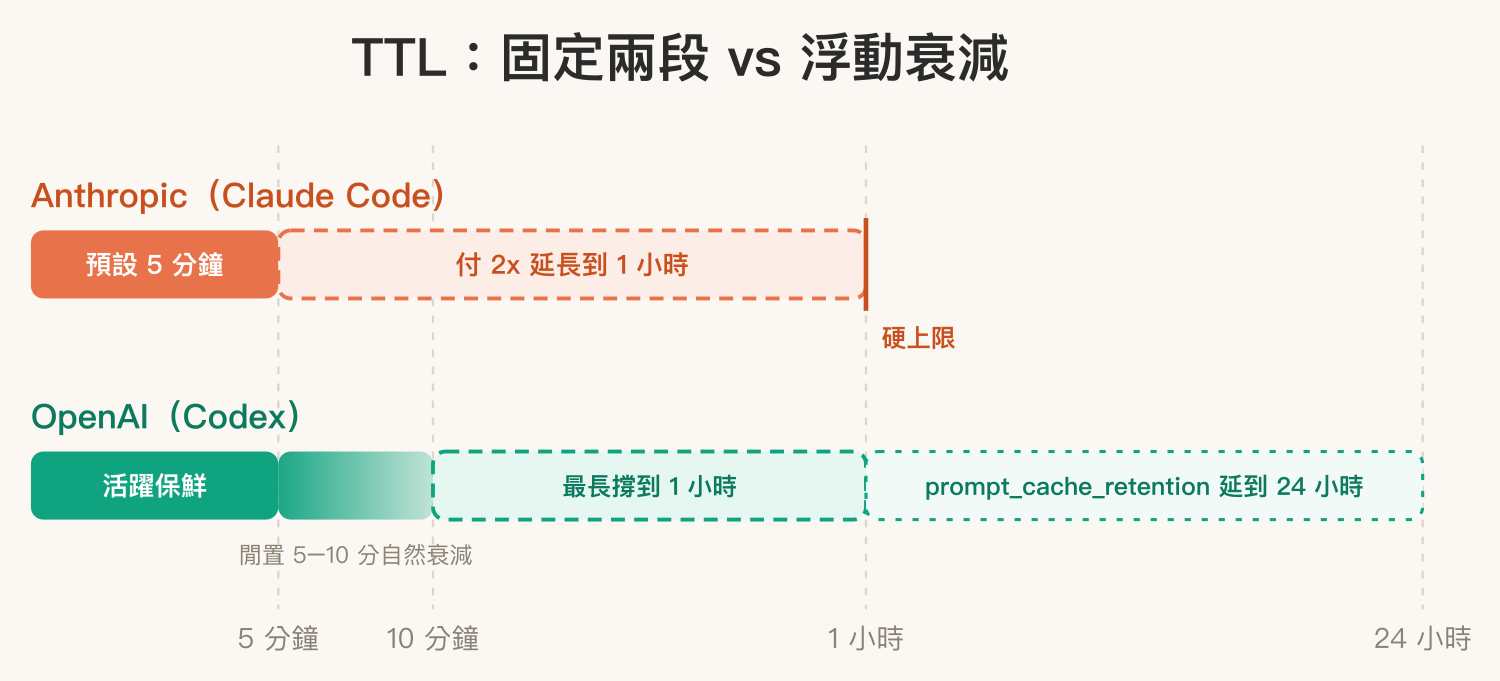
快取能撐多久,兩家的設計邏輯也不同。Anthropic 是固定兩段式 TTL:預設 5 分鐘,每次命中免費往後續;想要更長就在請求裡指定 1 小時版本,代價是寫入價翻倍。對 Claude Code 使用者來說,這對應到的就是前一篇提過的觀察——平常工作節奏下,Max 方案約 1 小時 TTL 幾乎不會自然過期,Pro 方案約 5 分鐘就要留意。
OpenAI 則是浮動衰減:根據官方文件,快取通常在閒置 5 到 10 分鐘後清掉,而且不論如何,最後一次使用後一小時內一定會被回收。它不像 Anthropic 那樣分成兩個明確檔位,而是一段「閒置就自然衰減、上限一小時」的模式。不過 OpenAI 多給了一個延長選項:透過 prompt_cache_retention 參數可以把保留時間拉到 最長 24 小時,這個上限比 Anthropic 的 1 小時長很多,適合那種「今天先做一半、明天接著做同一份脈絡」的場景。
Codex 多了一個手動旋鈕
除了上面三個計價與機制差異,Codex 還多了一個 Anthropic 沒有對應物的旋鈕:prompt_cache_key。這是個可以手動指定的參數,會跟前綴的 hash 一起影響請求被路由到哪台機器,藉此提高命中率。OpenAI 的 cookbook 舉過例子,某個寫程式的客戶靠調整這個 key,把命中率從 60% 拉到 87%。要注意的是同一組前綴加 key 如果每分鐘請求量太高(約 15 次以上),反而會溢出到其他機器造成 miss,所以它是把雙面刃。
有意思的是,Codex 的 CLI 文件不像 Claude Code 指南那樣集中講快取。前一篇 Claude Code 指南把「切模型、compact、改設定會打斷快取」講得很清楚,Codex 則把快取相關的說明放在開發者 cookbook,而不是日常使用文件裡。它的設計哲學是讓 agent 內部自動維持前綴穩定——系統指令、工具定義、sandbox 設定每一輪都保持完全一致、順序不變,新訊息一律用 append,把「怎麼吃到快取」這件事藏在內部,不讓使用者操心。從「使用者要不要主動管快取」這個角度看,Codex 比 Claude Code 更黑箱,但也更省事。
一張表看完所有差異
把上面的內容濃縮成一張對照表,方便快速翻閱:
| 項目 | Anthropic(Claude Code) | OpenAI(Codex) |
|---|---|---|
| 觸發方式 | 要標 cache_control 斷點,Claude Code 代勞 | API 層全自動、預設開、無法關閉 |
| 比對機制 | 前綴比對,動前綴後面全失效 | 前綴比對,動前綴後面全失效 |
| 最低門檻 | 依模型 512~4,096 不等,Opus/Sonnet 為 1,024 | 1,024 tokens,之後以 128 為增量 |
| 命中折扣(read) | 標準輸入的 10%(1 折) | 標準輸入的 10%(1 折) |
| 寫入費用(write) | 5 分鐘 1.25x/1 小時 2.0x | 不額外收費(標準輸入價) |
| TTL | 5 分鐘,可延長 1 小時(付 2x) | 閒置 5–10 分清、上限 1 小時,可延長到 24 小時 |
| 手動旋鈕 | 無(靠斷點擺位) | prompt_cache_key 提高命中率 |
小結
Codex 跟 Claude Code 的快取,大方向是同一套:都走前綴比對、動到前綴就整段失效、有最低門檻、活躍延長閒置清除。理解了一邊的原理,另一邊的脈絡就通了。差別集中在三個地方——觸發要不要手動(Anthropic 要標斷點但 Claude Code 代勞,OpenAI 真正零設定)、計價結構(命中折扣兩家都是 1 折,差別在 Anthropic 寫入要付溢價、OpenAI 寫入免費)、以及 TTL 的彈性(Anthropic 兩段固定,OpenAI 浮動衰減但可延到 24 小時)。
對日常使用的影響可以這樣記:在同一個 session 長時間連續工作、前綴會被反覆命中時,Anthropic 的寫入稅會被攤平、影響不大;頻繁開新對話、脈絡很零碎時,OpenAI 寫入免費的結構負擔更輕。至於想壓低 Claude Code 帳單的具體做法——精簡 CLAUDE.md、用 Skills 取代靜態指令、適時 /clear、用 subagent 隔離雜訊、搭配 statusline 監控——都整理在 先前那篇快取指南 裡,這篇的對比可以當成它的延伸閱讀。