
多數資料表的主鍵習慣用自增整數,像 PostgreSQL 的 BIGSERIAL 或 MySQL 的 AUTO_INCREMENT。單一資料庫的時代這樣很夠用,數字小、排序快、JOIN 也省空間。但是當系統要在多台機器上各自生成不重複的 ID、要把好幾個資料庫的資料合併在一起而不撞號,或者不希望外部從 /users/1001 這種網址反推出總用戶數時,自增整數就開始綁手綁腳。
這正是 UUID 派上用場的地方。不過 UUID 本身分成很多版本,從最早的 v1 到近年新增的 v7,設計目標差很多;而且如果拿錯版本來當資料庫主鍵,反而會把寫入效能拖垮。這也是 UUIDv7 與 ULID 這兩年特別常被討論的原因。這篇就把 UUID 各版本的差異、它們各自要解決什麼問題,以及 ULID 這類後起方案的取捨整理清楚。
UUID 是什麼
UUID 是 Universally Unique IDentifier 的縮寫,中文常譯作「通用唯一識別碼」,在微軟的世界裡也叫 GUID。它的核心很單純:一個 128 位元的數字,靠位元數夠多來保證「幾乎不可能」重複,不需要任何中央伺服器發號就能各自生成。
習慣上會把這 128 位元寫成 32 個十六進位數字,用連字號切成 8-4-4-4-12 五段,例如 550e8400-e29b-41d4-a716-446655440000。其中第三段的第一個數字記錄「版本(version)」,第四段的開頭幾個位元記錄「變體(variant)」——版本就是這篇要談的 v1 到 v8,變體則用來標示這個 UUID 遵循哪一套位元佈局規則。
UUID 的規格最早是 2005 年的 RFC 4122 ,定義了 v1 到 v5。2024 年 5 月,RFC 9562 正式取代了 RFC 4122,新增 v6、v7、v8 三個版本,並補上一段關於「時間可排序 UUID 對資料庫的好處」的明確指引。原本的 v1 到 v5 行為維持不變,所以舊系統不會受影響。
各版本的差異與設計背景
UUID 的版本號不代表「越新越好」,而是對應不同的生成策略。理解每個版本當初想解決什麼問題,比死記版本號實用得多。
| 版本 | 組成 | 可排序 | 典型用途 |
|---|---|---|---|
| v1 | 時間 + MAC | 否 | 早期帶時間的 ID,會洩漏 MAC |
| v2 | DCE Security | 否 | 幾乎不使用 |
| v3 | MD5(命名空間 + 名稱) | 否 | 同輸入對應固定 ID |
| v4 | 122 位元隨機 | 否 | 最常見,隨機 ID 與 token |
| v5 | SHA-1(命名空間 + 名稱) | 否 | 同 v3,雜湊較安全 |
| v6 | 重排的時間 + 節點 | 是 | v1 系統的可排序遷移選項 |
| v7 | 毫秒時間 + 隨機 | 是 | 資料庫主鍵首選 |
| v8 | 自訂 | 視實作 | 實驗與特殊需求 |
v1:時間加上網卡位址(2005)
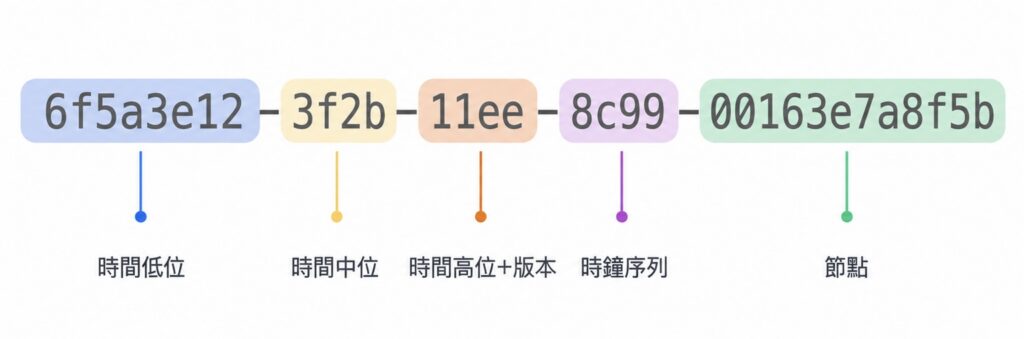
v1 把「時間戳」加上「節點識別」組合起來。時間戳用的是從 1582 年起算、100 奈秒為單位的計數;節點識別原始設計是直接拿機器的網卡 MAC 位址。這樣兩台機器即使在同一瞬間生成,靠 MAC 不同也不會撞號。
v1 有兩個為人詬病的地方。一是 MAC 位址會被寫進 ID 裡,等於把生成這個 ID 的機器資訊公開出去,有隱私與安全疑慮。二是它的時間欄位是「低位在前」擺放的,所以兩個照時間先後生成的 v1,字串本身排起來卻不照時間順序——這個細節在後面談資料庫主鍵時會發現很要命。
v2:DCE Security,幾乎用不到(2005)
v2 是為 DCE(分散式運算環境)設計的變形,會把 POSIX 的 UID/GID 之類的資訊嵌進去。實務上幾乎沒人用,多數函式庫甚至沒有實作,知道有這個東西即可。
v3 與 v5:用名稱算出固定的 ID(2005)
v3 和 v5 是「決定性」的:給定一個命名空間(namespace)加上一個名稱(name),算出來的 UUID 永遠一樣。差別在雜湊演算法,v3 用 MD5,v5 用 SHA-1。在不需要與舊系統相容的前提下,RFC 建議優先用 v5。要留意這兩種雜湊放到現在都不適合用於安全敏感的場合,UUID 這裡只是借它們把名稱轉成固定的值,不涉及加密強度。
這類 UUID 適合「同樣的輸入要對應同樣的 ID」的場景,例如把一個網址或一段固定字串映射成穩定的識別碼,不同機器算出來的結果會一致。
v4:純隨機,最普及的一種(2005)
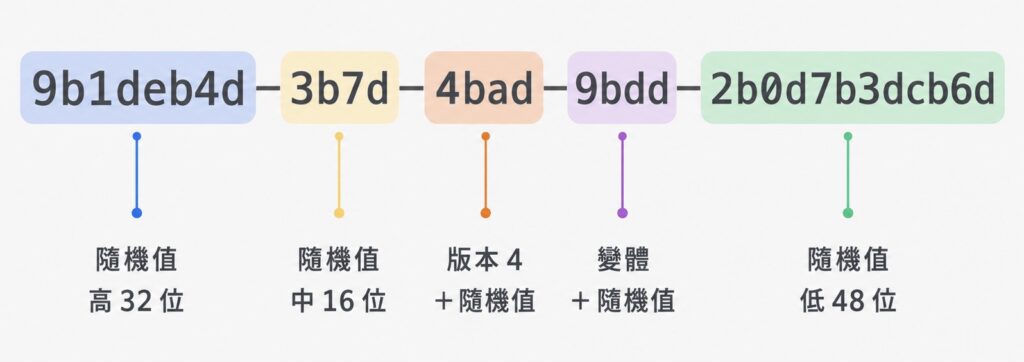
v4 把扣掉版本與變體之外的 122 個位元全部填上隨機值。它不帶任何時間或機器資訊,生成簡單、碰撞機率極低,是目前最常見的 UUID。各語言內建的「隨機 UUID」函式,像 crypto.randomUUID() 或 Java 的 UUID.randomUUID(),產生的都是 v4。
v4 拿來當隨機 token、做去識別化的對外 ID 都很合適。但是把它當資料庫主鍵就會踩到一個不小的坑,這點留到下一節細談。
v6:把 v1 重新排序(2024)
v6 是 RFC 9562 新增的,本質上是 v1 的「重排版」:用同樣的時間與節點資訊,但把時間欄位改成高位在前,這樣字串的字典序就會跟時間順序一致。它存在的主要意義是給既有 v1 系統一條遷移路徑——想保留 v1 的資訊結構、又想要可排序,就換成 v6。如果是全新系統,多半會直接跳到 v7。
v7:為資料排序而生(2024)
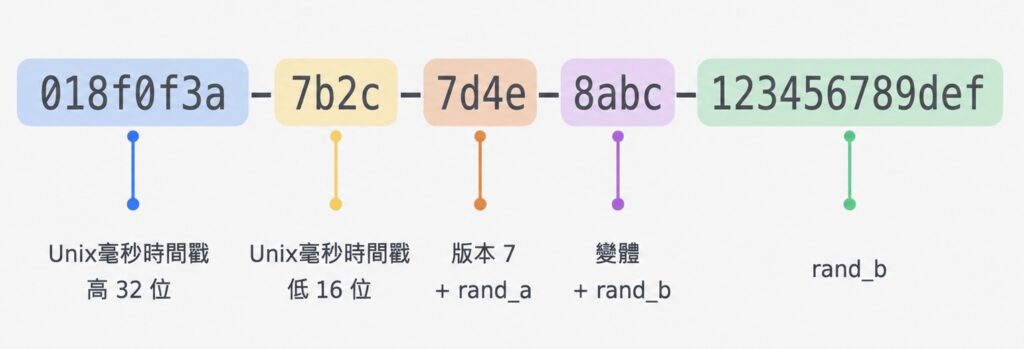
v7 是這次新版本裡相當受矚目的一個。它的結構很乾脆:前 48 位元放 Unix 紀元(1970 年起算)的毫秒時間戳,扣掉版本與變體之後,其餘約 74 位元放隨機值,部分實作還會用其中一段當計數器,確保同一毫秒內生成的多個 ID 也照順序遞增。
因為時間在最前面,v7 天生就照時間排序,新生成的 ID 永遠排在後面。這個性質讓它很適合當資料庫主鍵,也是 RFC 9562 特別點名推薦的用途。可以說 v7 就是為了解決 v4 當主鍵的問題而設計的。48 位元的毫秒時間戳理論上可以記錄到西元 10889 年,對任何實際系統都不構成上限。
v8:留給自訂用途(2024)
v8 幾乎不規定內部格式,只保留版本與變體欄位,其餘位元任由開發者自行定義。它是給有特殊需求、想塞自家編碼規則但又想掛在 UUID 標準下的情境用的,一般應用很少會碰到。
UUIDv4 當主鍵為什麼會變慢
這一節是整篇的關鍵。很多人把 v4 拿來當主鍵,跑一陣子發現寫入越來越慢,問題就出在「隨機」這個特性跟資料庫索引的運作方式不合。
關聯式資料庫的主鍵通常用 B-tree 索引,資料大致照鍵值大小順序存放。如果主鍵是自增整數或時間排序的值,新資料永遠接在最後面,等於一直往同一個地方追加,索引尾端的頁面待在記憶體裡就能一直命中。
v4 是純隨機的,每筆新資料的主鍵都可能落在索引中間任何一個位置。這會帶來幾個連鎖反應:插入點分散,常常要把已經寫滿的索引頁面拆成兩半(頁面分裂),造成寫入放大;要動到的頁面四處都是,記憶體快取很難命中,磁碟 I/O 跟著上升;索引也比照順序插入時更鬆散、佔用更多空間。在 MySQL 的 InnoDB 這種「資料直接照主鍵叢集存放」的引擎上,影響又更明顯。
v7 和 ULID 就是針對這點下手:把時間戳放在最前面,新資料的鍵值總是比舊的大,插入點重新集中到尾端,B-tree 頁面分裂與快取失誤都跟著減少。它們在保留「分散式各自生成、不撞號」這個 UUID 優點的同時,把寫入行為拉回到接近自增整數的樣子。
ULID 是什麼,為什麼會出現
ULID 全名 Universally Unique Lexicographically Sortable Identifier,2016 年提出時,UUID 標準還停在只有 v1 到 v5、沒有官方的時間排序版本。ULID 想同時解決 v4 的兩個不便:不可排序,以及帶連字號的十六進位字串既長又不好讀。
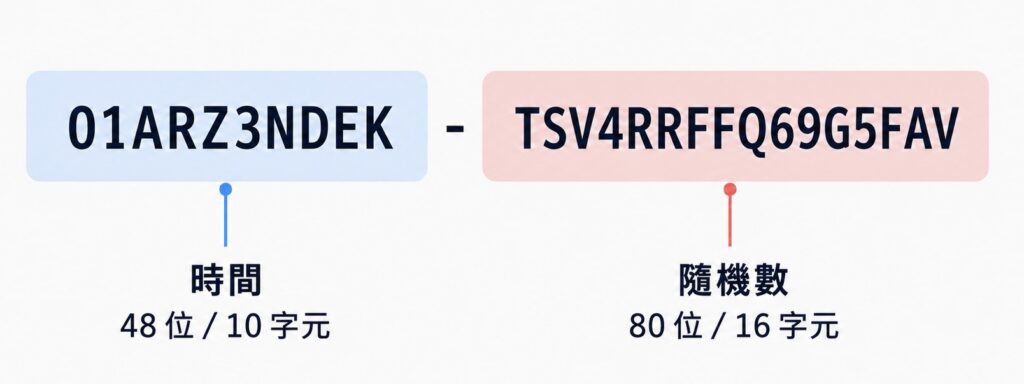
它一樣是 128 位元,切成前 48 位元的毫秒時間戳,加上後 80 位元的隨機值。表示法不用十六進位,而是用 Crockford Base32 編成 26 個字元,例如 01ARZ3NDEKTSV4RRFFQ69G5FAV。這套 Base32 刻意拿掉了容易看錯的字母(I、L、O、U),所以人眼讀寫不易混淆,整串也是 URL 安全、可直接照字典序排序、大小寫不敏感。
UUIDv7 與 ULID 的同與異
看到這裡會發現 v7 跟 ULID 幾乎是同一個想法:128 位元、時間戳在前、可排序、解決 v4 當主鍵的索引問題。它們的差異主要在標準地位與表示法。
| 面向 | UUIDv7 | ULID |
|---|---|---|
| 標準地位 | IETF 標準(RFC 9562) | 社群規格,非 RFC |
| 位元結構 | 48 位元時間 + 版本/變體 + 約 74 位元隨機 | 48 位元時間 + 80 位元隨機 |
| 預設表示法 | 36 字元十六進位(含連字號) | 26 字元 Crockford Base32 |
| 二進位儲存 | 16 位元組 | 16 位元組 |
| 生態支援 | 資料庫與標準庫逐漸內建 | 需第三方函式庫 |
兩者都能存成 16 位元組的二進位,所以 ULID 其實可以直接塞進資料庫的 uuid 欄位,只是顯示時的字串格式不同。實務上的取捨大致是這樣:想要標準背書、想讓資料庫與語言原生函式幫忙生成,選 v7;偏好較短、人眼友善的字串,或專案裡已經有成熟的 ULID 工具鏈,選 ULID。因為標準已經把時間排序需求收進 v7,新專案若沒有特別理由,從 v7 起步通常比較省事。
實務上該選哪一個
時間排序的 ID 雖然好用,但不代表每個欄位都該換掉。幾個務實的判斷:
- 自增整數仍然合理的情況:單一資料庫、不需要分散式生成、ID 也不對外暴露時,自增整數省空間、JOIN 也快,沒必要為了趕流行換成 UUID。
- v4 也不是不能用:如果這個 ID 不拿來當叢集索引主鍵,或本來就只當隨機 token、不在乎排序,v4 簡單夠用。
- v7 或 ULID 的主場:需要在多處各自生成、又要拿來當主鍵、還在意寫入效能時,時間排序的 ID 正合適。
有一個反向提醒值得放在心上:v7 與 ULID 的時間戳是可以反推出來的,等於把「這筆資料大約何時建立」公開了。如果某個對外 ID 的建立時間屬於敏感資訊,例如不想讓人從帳號 ID 推算註冊先後或成長速度,這時用帶時間的 ID 當對外識別碼反而不妥,改用 v4 或另外包一層對外編號會更穩妥。
其他類似的識別碼方案
時間排序的唯一 ID 不是只有 UUID 與 ULID,幾個常見方案各有取捨,了解它們有助於判斷手上的需求該往哪靠。
| 方案 | 長度 | 帶時間 | 特點 |
|---|---|---|---|
| Snowflake | 64 位元 | 是 | Twitter 提出,時間 + 機器 ID + 序號,整數型省空間,但機器 ID 需要事先協調分配 |
| KSUID | 160 位元 | 是 | 秒級時間 + 隨機,27 字元 Base62,時間範圍涵蓋很長 |
| NanoID | 可調,預設 21 字元 | 否 | 純隨機、字串短、URL 友善,定位接近 v4 |
| CUID2 | 可調 | 否 | 強調防碰撞且不外洩時間資訊 |
簡單歸納:要塞進整數欄位、很在意空間,Snowflake 這類 64 位元方案有優勢,但要付出維護機器 ID 的成本;只要隨機短字串、不需要排序,NanoID 很俐落;要兼顧時間排序與標準相容,回到 UUIDv7 或 ULID 仍是較穩的選擇。
各語言與資料庫怎麼產生 v7 與 ULID
最後看實際怎麼生成。要留意的是,各語言內建的隨機 UUID 函式產生的都是 v4,v7 與 ULID 多半要靠較新的版本或第三方函式庫。
PostgreSQL
PostgreSQL 18(2025 年 9 月發布)內建了 uuidv7() 函式,可以直接當欄位預設值。更早的版本只有產生 v4 的 gen_random_uuid(),要 v7 得自己寫函式或裝擴充套件。
-- PostgreSQL 18 起內建,直接當主鍵預設值
CREATE TABLE orders (
id uuid PRIMARY KEY DEFAULT uuidv7(), -- 時間排序,寫入對索引友善
memo text
);
-- 舊版本只有 v4(純隨機),當主鍵會有前面提到的索引碎片問題
SELECT gen_random_uuid();Java
JDK 內建的 java.util.UUID 只能透過 UUID.randomUUID() 產生 v4,到目前為止沒有原生的 v7 生成方法。需要 v7 或 ULID 時,常用 uuid-creator 這個函式庫。
import com.github.f4b6a3.uuid.UuidCreator;
import com.github.f4b6a3.ulid.UlidCreator;
// JDK 內建:只能產生 v4(隨機)
UUID v4 = UUID.randomUUID();
// uuid-creator 函式庫:時間排序的 v7
UUID v7 = UuidCreator.getTimeOrderedEpoch();
// 同一套函式庫也能產生 ULID
String ulid = UlidCreator.getUlid().toString();JavaScript 與 Node.js
瀏覽器與 Node 內建的 crypto.randomUUID() 同樣只產生 v4。官方的 uuid 套件從 9.1.0(2023 年)起支援 v7;ULID 則用 ulid 套件。
// 內建:只有 v4
const v4 = crypto.randomUUID();
// uuid 套件 9.1.0 起支援 v7
import { v7 as uuidv7 } from "uuid";
const v7 = uuidv7();
// ULID 用獨立套件
import { ulid } from "ulid";
const id = ulid();Python
Python 3.14 起,標準庫的 uuid 模組新增了 uuid6()、uuid7()、uuid8(),不必再裝第三方套件就能產生 v7。更早的版本可以用 uuid6 套件補上。ULID 則用 python-ulid 之類的套件。
import uuid
# 一直都有:v4(隨機)
v4 = uuid.uuid4()
# Python 3.14 起內建:時間排序的 v7
v7 = uuid.uuid7()
# ULID 用第三方套件
from ulid import ULID
my_ulid = ULID()小結
UUID 從 v1 一路走到 v7,其實是一條「先求唯一,再求好排序」的演進線。v4 解決了不靠中央發號就能生成的需求,卻在當主鍵時撞上索引碎片的問題;v7 與 ULID 把時間戳放到最前面,補上了可排序這塊,讓分散式生成的 ID 也能像自增整數一樣對資料庫友善。如果現在要為新系統挑一個主鍵方案,又需要分散式生成,UUIDv7 是相容性與資料庫支援都到位的起點;偏好短字串就換成 ULID。至於要不要從自增整數換過去,還是回到那句老話——先看實際需求,沒有分散式或對外暴露的顧慮,原本的整數主鍵其實就很好。