
OpenAI 在 2026-04-22 推出 GPT Image 2(產品名 ChatGPT Images 2.0、API 模型名 gpt-image-2),是 DALL-E 3 與 GPT Image 1.5 的繼任者。最大的改變是把 o 系列的 reasoning 帶進生圖流程——模型會先規劃、自我檢查再下筆,加上原生 2K、多語言文字渲染(中日韓、Hindi、Bengali 都能寫對)與網路搜尋整合。這篇文章整理它跟前代的差異、API 價格與各種入口的使用方式,並附上幾組可以直接複製的提示詞範例。
GPT Image 2 是什麼
GPT Image 2 是 OpenAI 推出的新一代多模態生圖模型,產品端品牌叫「ChatGPT Images 2.0」、API 模型名是 gpt-image-2,發表日期是 2026-04-22。它直接取代過去 ChatGPT 內建的 DALL-E 3 與短暫存在過的 GPT Image 1.5,後續所有 ChatGPT 預設的生圖入口都會改走這顆新模型。
這次的發表方式很安靜——沒有 keynote、沒有 livestream、沒有預熱貼文,就是模型頁面上線、Image Arena 排行榜上多了一行新紀錄。但實測結果完全不安靜:上線 12 小時內,GPT Image 2 在 Image Arena 的文字轉圖(text-to-image)、單圖編輯、多圖編輯三個榜單同時拿下第一,文字轉圖領先第二名 +242 Elo,是這個榜單有紀錄以來最大的領先差距。Anthropic、Google、Black Forest Labs 這些對手在生圖榜上都被一次拉開。
OpenAI 沒有公開 GPT Image 2 的詳細架構,只說它的「思考」能力是由 GPT-5.4 同代的 reasoning 後端驅動,配合一個專門做圖像生成的解碼器。換句話說,這顆模型不是把過去 DALL-E 系列的擴散模型直接放大,而是「LLM 會 reasoning + 生圖 decoder」的混合體,這點跟 Google 那邊的 Nano Banana、Gemini Image 系列方向類似。
跟 DALL-E 3 與 GPT Image 1.5 差在哪
先用一張表把開發者最常關心的幾個項目對齊:
| 項目 | DALL-E 3 | GPT Image 1.5 | GPT Image 2 |
|---|---|---|---|
| API 模型名 | dall-e-3 | gpt-image-1 | gpt-image-2 |
| 原生最大解析度 | 1024×1792 | 1536×1536 | 2K(含 2048×2048、2048×1152 等) |
| 內建 reasoning | 無 | 無 | 有,o 系列思考 |
| 網路搜尋整合 | 無 | 無 | 有,可即時 fact-check |
| 文字渲染 | 常拼錯 | 英文堪用、CJK 不行 | 英文穩定、CJK/Hindi/Bengali 也能寫對 |
| 多圖一致性 | 難維持 | 有限 | 同一 session 多次出圖可保留主角/場景 |
| 圖片編輯 | 限制多 | 支援 | 單圖、多圖編輯都領先 |
| 知識截止 | — | — | 2025-12 |
幾個要展開的點下面分別來看。
三大核心升級
會思考的生圖流程
過去的生圖模型基本上是「prompt 進、圖出來」的一次性過程,模型沒有時間檢查自己畫的對不對。GPT Image 2 的 reasoning 流程把這件事整個改了——拿到 prompt 之後模型會先規劃畫面結構(有哪些主角、放哪裡、視角怎麼擺)、檢視語意一致性(如果說「七位坐成弧形」,會先想清楚七個人各自的位置),對複雜場景才下筆。對於需要精準佈局的 infographic、UI mockup、含多個角色的插畫,差距非常明顯。
實際使用上感受得到的是兩件事:第一,輸出時間比 DALL-E 3 長一些,因為要思考;第二,過去那種「畫成功率忽高忽低」的隨機感大幅降低,prompt 寫清楚的話幾乎一次就能對。
文字渲染與多語言
這代被社群討論最多的就是把字寫對。DALL-E 3 時代生出來的招牌、菜單、海報十之八九會出現「TACBO」「FRIES」拼錯的尷尬,現在 GPT Image 2 不只英文穩,中文、日文、韓文、Hindi、Bengali 這類非拉丁字母的腳本也能正確渲染,包含手寫筆記、招牌、UI 標籤、海報文字、QR Code。對需要做品牌素材、行銷視覺、簡報插圖的工作流,這一點影響非常大——以前要交給設計師後製貼字的步驟,現在可以由模型一次完成。
實測下來中文比 Gemini 系列穩定一些,但繁體與簡體的辨別偶爾還是會混;如果要明確指定繁體字,prompt 直接寫「使用繁體中文」效果最好。
網路搜尋整合
第三個跟過去生圖模型完全不同的地方是可以連網查資料再畫。過去要畫某個近期才出現的人物、產品、事件,模型只能憑訓練資料硬猜,常常畫成完全不存在的東西。GPT Image 2 會在思考階段呼叫 web search,先確認對象長什麼樣,再下筆。例如「畫 2026 年 NVIDIA GB300 的伺服器外觀」「畫某新車款的儀表板」這類 knowledge-cutoff 後的題材,現在比較有機會畫得貼近事實。
網路搜尋目前主要在 ChatGPT 端有效——配合 GPT-5.5 等 thinking 模型才會被觸發;API 端是否預設啟用,OpenAI 官方文件沒講得很清楚,這部分等之後實測會再追蹤。
三種入口怎麼用
跟前面 GPT-5.5 的安排類似,GPT Image 2 也是依入口不同有些差異:
| 入口 | 可用方案 | 使用方式 | 限制 |
|---|---|---|---|
| ChatGPT | 所有 ChatGPT、Codex 用戶(含 Free) | 對話內直接請模型畫圖;付費方案可用更高品質與解析度 | Free 有每日次數限制,Plus/Pro 額度寬鬆 |
| Codex | Plus、Pro、Business、Enterprise、Edu | 跟 ChatGPT 一樣的對話介面,可在程式相關情境直接請出圖 | 多用於 mockup、icon 等開發場景 |
| API | 已開通帳號 | gpt-image-2 模型名,依品質與解析度計費 | API 開放時間與分階段政策請看 OpenAI Help Center |
對一般使用者最直接的路徑就是打開 ChatGPT,輸入想畫的內容;模型會自動切到 GPT Image 2,不需要從 model picker 切換。Free 方案也能用,只是次數受限,付費方案除了次數寬鬆之外還能解鎖 2K/4K 與 high quality 等較高層級的輸出。
ChatGPT 介面的尺寸與品質控制
ChatGPT 端不必像 API 那樣自己塞參數,對話框右側會有一個面板,提供四個控制項:
| 控制項 | 選項 | 說明 |
|---|---|---|
| Size mode | Auto / Aspect ratio / Custom pixels | 讓模型自己決定、選預設比例、或直接給 pixel 尺寸 |
| Aspect ratio | 1:1、3:2、2:3、16:9、9:16、3:1、1:3 | 從正方形到超寬/超高都支援 |
| Quality | Low / Medium / High | 對應 API 的三檔品質,影響細節與成本 |
| Batch count(n) | 1 – 10 | 一次出幾張 |
Custom pixels 模式下兩邊長度都必須是 16 的倍數,最大邊上限 3840px、總像素 65 萬到 830 萬之間,比例不能超過 3:1。生成完還可以直接點圖打開編輯器,框出特定區塊請模型補畫或修改。
注意:Free 方案能看到完整的控制項,但實際可用的解析度與品質有限制——2K/4K 與 high quality 主要保留給 Plus 以上的付費方案,Free 用戶切到這些選項時通常會被自動降階或提示升級。
API 價格
API 端走的是 token-based 計費,跟一般文字模型一樣,但圖片本身會被換算成 image token。官方公布的單價如下(台幣以 1 USD ≈ 32 TWD 換算,僅供參考):
| 類型 | USD / 1M tokens | TWD / 1M tokens |
|---|---|---|
| Text input | $5.00 | NT$160 |
| Text input(cached) | $1.25 | NT$40 |
| Image input | $8.00 | NT$256 |
| Image input(cached) | $2.00 | NT$64 |
| Image output | $30.00 | NT$960 |
實際每張圖的成本依解析度與品質階層而定,OpenAI 給的常見數字大約是:
| 解析度 | Low | Medium | High |
|---|---|---|---|
| 1024×1024 | ~$0.006(NT$0.2) | ~$0.053(NT$1.7) | ~$0.211(NT$6.8) |
| 1024×1536 / 1536×1024 | ~$0.005(NT$0.16) | ~$0.041(NT$1.3) | ~$0.165(NT$5.3) |
| 2K(最高品質) | — | — | ~$0.30(NT$9.6)起跳 |
跟 DALL-E 3 的固定 $0.04(standard)/$0.08(HD)相比,GPT Image 2 在 low 階位反而更便宜,但高品質與 2K 的價位明顯高出一截。實務上對 SaaS 產品做頭貼、商品圖這種大量需求,可以走 low / medium 控制成本;對印刷、行銷視覺等需要交付的場景再切到 high quality 與 2K。
注意:API 上線是分階段釋出,部分地區或帳號可能要等 waitlist 通過。實際上線狀態以 OpenAI Platform 文件 為準。
提示詞範例
下面整理幾組能突顯 GPT Image 2 新能力的提示詞,全部都是繁體中文撰寫,可以直接複製貼到 ChatGPT 對話視窗,或包裝成 API 的 prompt 欄位送出。每一組會說明這個提示詞主要在測什麼能力,以及實務上可以怎麼改寫成自己用的版本。
範例一:含繁體中文招牌的城市夜景
這組主要是測多語言文字渲染。過去的生圖模型畫繁體中文招牌幾乎都會變成亂碼,是 GPT Image 2 最被看好的能力之一。
畫一張台北信義區的夜晚街景,由低角度斜上拍攝。
畫面中央是一間小巷裡的拉麵店,木質暖色招牌上寫著繁體中文「光譜拉麵」四個大字,
旁邊有較小的繁體中文標語「招牌豚骨.每日限量五十碗」。
店門口紅燈籠掛著「營業中」三個字。背景遠處是模糊的霓虹招牌與行人,
鏡頭風格偏電影感,低光、淺景深、些微底片顆粒。提示詞重點:先指定場景與視角(信義區、低角度斜上)、再指定每一塊文字內容(招牌、副標、燈籠),最後給視覺風格(電影感、底片顆粒)。把要寫的字明確列出來,比寫「上面有些招牌」效果好非常多。

範例二:技術部落格的封面 banner
這組主要是測排版與英文文字渲染,是部落格作者最常用的場景之一。
設計一張 1792×1024 的技術部落格封面 banner,主題是「GPT Image 2 介紹」。
左側 60% 區域是主視覺:一顆懸浮的稜面玻璃立方體在畫面中央偏左下,
表面有清透的折射與反射,內部透出青綠(#0AA889)與珊瑚橘(#FF8A4C)
柔和漸層光,光線從立方體裡溫和地擴散出去,像晨光穿過水晶。
立方體周圍漂浮著數十個半透明的小型圖示(相機、字母 A、繁體中文「字」、
日文假名、emoji),帶輕微景深,象徵多語言與多媒材生成。
背景是明亮清新的科技感空間:米白漸層底(#FFFFFF → #F2F6FA),
覆蓋一層極淺的等距點陣網格與細微紙質紋理。畫面四角有低調點綴:
左上角一團 8% 不透明度的青綠柔光暈、右下角一團 8% 不透明度的珊瑚橘柔光暈,
遠處有少量微小的程式碼字元(0、1、{、}、繁中漢字)以非常淺的灰色(不超過
12% 不透明度)散布,營造科技氛圍但不搶過主視覺。整體調性像是 Stripe、
Linear、Vercel 的官網插畫。
右側 40% 是文字區,搭配淺灰描邊的白色卡片,帶柔和投影:
最上方一行小字「OPENAI · 2026-04-22」(中灰色),
中間是粗體大標「GPT Image 2」(深炭灰 #1F2937),
下方是副標「ChatGPT Images 2.0:會思考的生圖模型」(青綠色)。
整體配色:米白底 + 青綠/珊瑚橘雙色點綴 + 深炭灰主文字。
Sans-serif 無襯線幾何字體,風格明亮、乾淨、商務專業,避免任何賽博龐克元素。提示詞重點:明確指定畫面比例(1792×1024)、區域分配(左 60% / 右 40%)、每一塊文字的內容與層級(小字/大標/副標),以及配色與字體類型。這種結構化指示對 GPT Image 2 的 reasoning 特別友善。

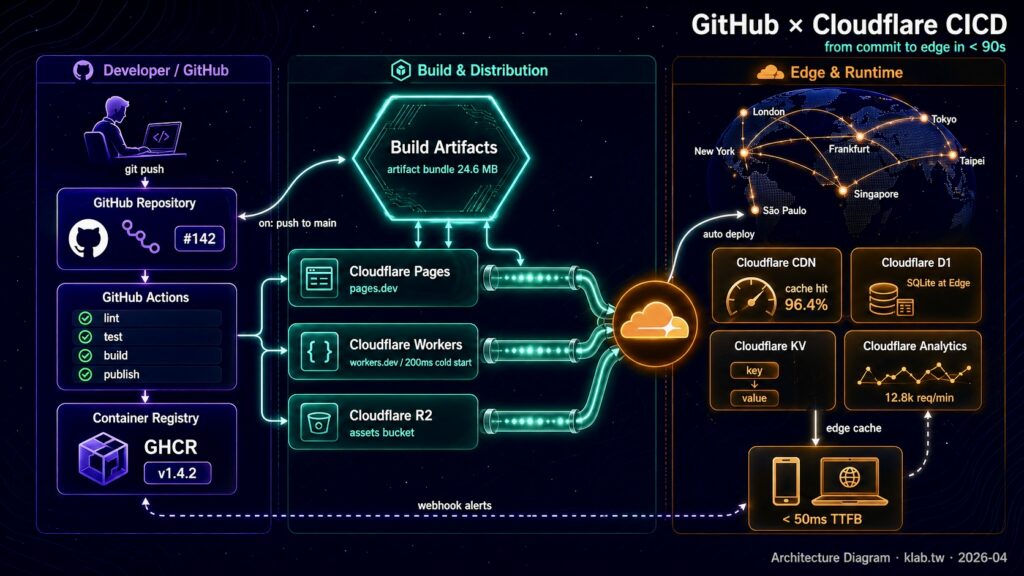
範例三:CICD 系統架構圖(GitHub + Cloudflare)
這組測多區塊 infographic + 多服務一致性 + 大量文字標籤,畫一張現代 SaaS 常見的 GitHub × Cloudflare CICD 架構圖。元件多、連線交錯,是生圖模型過去最容易畫崩的場景,也最能凸顯 reasoning 的價值。
設計一張 2560×1440 的橫向系統架構圖,主題「GitHub × Cloudflare CICD Pipeline」。
深藍黑漸層背景(#0A0F1F → #1A2340),覆蓋一層細密的等高線網格與微弱的星塵粒子,
營造科技感但不要喧賓奪主。整張圖分為三個垂直 swim lane(泳道),
泳道之間用半透明分隔線與標籤區分:
【左側泳道:Developer / GitHub】淺紫色(#7A5CFF)強調色。
- 最上方一個「Developer」icon(坐在筆電前的剪影),底下標籤「git push」。
- 下方依序三個圓角卡片:
1. GitHub Repository(含 GitHub octocat logo、分支圖示、PR badge「#142」)
2. GitHub Actions(含 workflow 步驟列表:lint → test → build → publish,每行有 ✓ 綠勾)
3. Container Registry(GHCR,含一個 Docker image tag「v1.4.2」)
【中間泳道:Build & Distribution】青綠色(#00FFAA)強調色,是整張圖的主軸。
- 最上方一個大型「Build Artifacts」六邊形 hub,內部寫「artifact bundle 24.6 MB」。
- 中間放三條平行的傳輸管線(pipe),每條管線上有移動中的資料光點:
Pipe A → Cloudflare Pages(靜態網站,標籤「pages.dev」)
Pipe B → Cloudflare Workers(邊緣函式,標籤「workers.dev / 200ms cold start」)
Pipe C → Cloudflare R2(物件儲存,標籤「assets bucket」)
- 三條管線匯聚成一個發光的 Cloudflare 橘色 logo(雲朵造型)。
【右側泳道:Edge & Runtime】橘色(#F38020)強調色,Cloudflare 官方品牌色。
- 最上方畫一個地球,地球上散布七個發光節點(東京、台北、新加坡、法蘭克福、
倫敦、紐約、聖保羅),節點之間有細弧光線連接,代表全球 CDN。
- 地球下方四個圓角卡片並排兩列:
- Cloudflare CDN(含 cache hit 96.4% 的迷你儀表板)
- Cloudflare D1(SQLite at Edge,含一個 mini schema icon)
- Cloudflare KV(key-value store)
- Cloudflare Analytics(含 sparkline 折線圖,數值「12.8k req/min」)
- 最下方一個「End User」icon(手機 + 筆電),標籤「< 50ms TTFB」。
【跨泳道箭頭】用霓虹白色(#FFFFFF)帶光暈的弧形箭頭連接:
- GitHub Actions → Build Artifacts(標籤「on: push to main」)
- Build Artifacts → 三條 pipe 分別到 Pages / Workers / R2
- Cloudflare 雲朵 → CDN 地球(標籤「auto deploy」)
- CDN → End User(標籤「edge cache」)
- Cloudflare Analytics → GitHub(虛線回饋箭頭,標籤「webhook alerts」)
【右上角】放整張圖標題「GitHub × Cloudflare CICD」(大標,白色粗體)
與副標「from commit to edge in < 90s」(青綠色細體)。
【右下角】小字「Architecture Diagram · klab.tw · 2026-04」浮水印。
整體風格:扁平 + 微立體陰影、清晰標籤、賽博龐克配色但保留商務專業感,
所有圖示與標籤的對齊嚴謹,確保即使縮到 50% 仍能看清楚每個元件名稱。提示詞重點:用泳道(swim lane)切分階段,模型在 reasoning 時會更容易把元件分組擺放;每個元件除了名稱還補上具體可寫的數字或標籤(artifact 大小、cache hit 率、TTFB 時間),讓圖看起來像真的 dashboard 而不是空殼示意;連線一律用「箭頭 + 標籤」的格式描述,並指定弧形或虛線等樣式區分業務流與監控回饋;最後在每個泳道指定一個強調色(紫 / 青綠 / 橘),整張圖視覺層次會非常清楚。這種寫法在 DALL-E 3 時代幾乎不可能穩定產出,現在 GPT Image 2 一次就能畫到接近能直接放進技術簡報的程度。
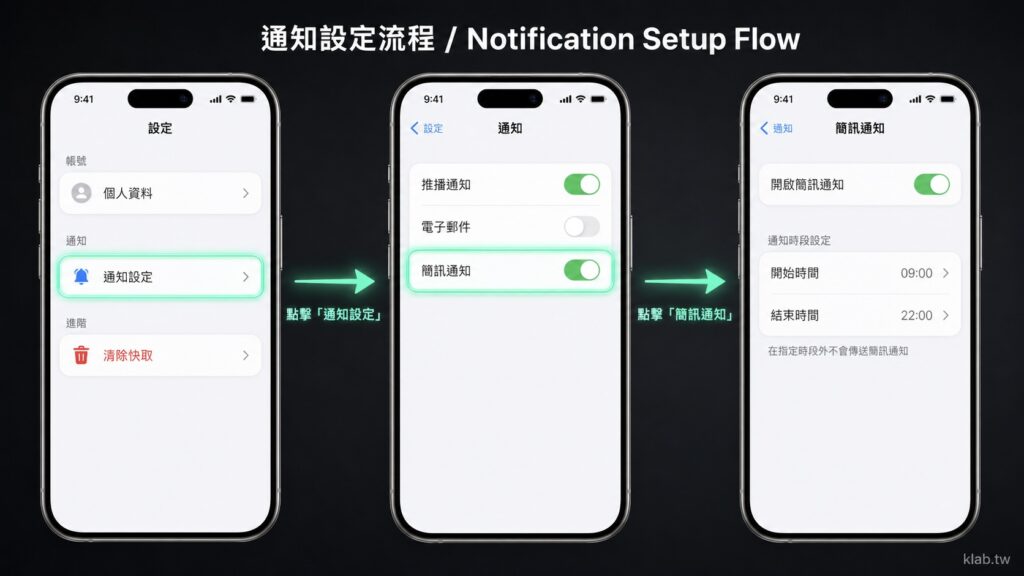
範例四:UI 流程 mockup(三畫面依序點選)
這組測多畫面一致性 + 介面精細元件 + 流程指示,一次出三張 iPhone 截圖,模擬使用者從設定首頁逐步點進通知設定的完整 flow,是 GPT Image 2 reasoning 強項才能穩定畫出的構圖。
設計一張 3840×2160 的 UI 流程示意圖,深灰漸層背景,
三支 iPhone 15 Pro 從左到右等距並排,每支手機都帶細緻金屬邊框與島形 Dynamic Island。
三個畫面共用同一個 iOS 18 淺色主題、繁體中文介面,並在手機之間用霓虹青綠色(#00FFAA)
箭頭連接,箭頭中央標示「點擊」與對應元件名稱。
【畫面 1:設定首頁】
頂部 Navigation Bar 標題「設定」。下方分三個 section:
- 帳號:一列「個人資料」帶右側 chevron。
- 通知:一列「通知設定」帶右側 chevron,這列要用霓虹青綠色光暈外框強調,
代表使用者即將點擊的對象。
- 進階:一列「清除快取」(紅色文字)。
【箭頭 1】指向畫面 2,標籤「點擊『通知設定』」。
【畫面 2:通知設定列表】
頂部 Navigation Bar 標題「通知」、左上角返回箭頭與小字「設定」。
下方一個 section 列出三列:
- 推播通知(開關 ON)
- 電子郵件(開關 OFF)
- 簡訊通知(開關 ON)— 這列用霓虹青綠色光暈外框強調。
【箭頭 2】指向畫面 3,標籤「點擊『簡訊通知』」。
【畫面 3:簡訊通知細節】
頂部 Navigation Bar 標題「簡訊通知」、左上角返回箭頭與小字「通知」。
畫面分兩個 section:
- 開啟簡訊通知(開關 ON)
- 通知時段:兩列「開始時間 09:00」「結束時間 22:00」,右側帶 chevron。
畫面下方有一行說明文字「在指定時段外不會傳送簡訊通知」(淺灰小字)。
整張圖最上方放標題「通知設定流程 / Notification Setup Flow」,
最下方右側放浮水印「klab.tw」。配色保持淺色 UI、深灰背景、霓虹青綠強調。提示詞重點:把每個畫面當成獨立區塊用方括號標題分段、每個畫面內部再用 bullet 列出元件與狀態;用霓虹色光暈外框標出「即將被點擊」的元件,再用箭頭與標籤連接畫面,模型才會把流程關係畫出來。前後兩個畫面的 navigation bar 標題與返回鍵互相呼應,能讓 reasoning 階段把「這是同一個 App 的不同層」這件事抓住,產出的細節一致性會比一張一張分開畫穩定許多。
範例五:多角色一致性插畫
最後一組測多角色佈局與細節一致性。
畫一張爽朗有精神的插畫,五位開發者圍著一張長桌共同討論程式碼,氣氛積極投入。
從左到右:
1. 戴黑框眼鏡、穿淺灰帽 T 的女生,正在用筆電,臉上帶輕鬆的微笑。
2. 短髮俐落、穿天藍色襯衫的中年男子,手上拿著筆記本,神情專注但有朝氣。
3. 短髮、穿亮黃色 T-shirt 的年輕男生,正比手畫腳,眼神自信明亮。
4. 戴耳機、穿白襯衫的女生,看著螢幕快速打字,姿態輕快。
5. 穿薄荷綠 hoodie 的男生,舉手提問,笑容開朗。
桌上有筆電、玻璃水杯、便利貼、白板筆,整體乾淨整齊。
背景是辦公室落地窗,外面是晴朗的早晨藍天與遠方城市天際線,
有溫和的自然光從左側灑進室內。
風格採用扁平向量插畫,配色清爽明亮(天藍、白、薄荷綠、檸檬黃做點綴),
線條俐落、色塊分明,整體傳達朝氣與專業感。提示詞重點:把每個角色的外觀特徵與動作分點列出,這樣模型 reasoning 時可以個別處理;場景物件也要列清楚,不然桌上常常會少掉一兩樣。GPT Image 2 對「五位以上同框」的處理已經比 DALL-E 3 穩定許多,但要寫得越具體效果越好。

範例六:夜市美食宣傳海報
這組測攝影級寫實風格 + 大量繁體中文文字渲染 + 多商品排版。台灣夜市場景的氛圍、招牌、價格牌過去都是生圖模型的重災區,也是 GPT Image 2 文字能力最能展現價值的題材。
設計一張直式 1080×1620 的宣傳海報,主題「台灣夜市美食特輯」,
風格寫實攝影 + 設計排版混搭,整體要有夜晚的熱鬧氛圍與食物的香氣感。
【主視覺】畫面上半 60% 是一張俯角廣角的夜市街景照片:
台灣傳統夜市的窄巷,兩側擁擠的攤車與紅黃招牌,
攤位上飄起淡淡白色蒸氣,地上有反光的水痕,遠處模糊的人潮,
配色以暖橘、紅、黃為主,搭配少量霓虹藍綠點綴,
鏡頭風格類似台灣電影夜景的質感,淺景深、柔和顆粒。
注意:所有招牌與攤位文字使用虛構的台式店名或泛用美食字樣
(例如「老王麵店」「香脆雞排」「古早味」),不要出現任何真實品牌或店家名稱。
【主標題】壓在街景照片中央的暖色半透明色塊上:
最上一行小字(白色細體)「TAIWAN NIGHT MARKET · 2026」,
中間極大的繁體中文書法風格主標「台灣夜市美食特輯」(金黃色,帶細描邊),
副標「八樣經典 · 一次吃個夠」(白色細體)。
【下半 40%】排版區是奶油色(#FFF7E6)背景,
切成 2 欄 4 列共八個美食卡片,每張卡片含:
- 一張該料理的小型寫實照片(圓角方塊,保持風格一致)
- 上方一行繁體中文菜名(深咖啡色粗體)
- 下方一行小字描述(中灰色)
- 右下角橘色圓形價格 badge
八個美食依序:
1. 蚵仔煎 / 鮮蚵 + 雞蛋 + 太白粉 / NT$80
2. 大腸包小腸 / 糯米腸夾香腸 / NT$70
3. 青蛙下蛋 / 粉圓奶茶 / NT$60
4. 胡椒餅 / 現烤肉餡餅 / NT$65
5. 滷味拼盤 / 滷豆干雞翅米血 / NT$120
6. 雞排 / 香雞排加九層塔 / NT$80
7. 牛肉麵 / 紅燒清燉皆有 / NT$180
8. 芋圓豆花 / 古早味甜湯 / NT$65
【底部 footer】中央一行細字「2026 春季夜市特輯」,深咖啡色細體。
不需要 QR Code、不需要地址、不需要任何網址或網域名稱。
整體配色:暖橘紅 + 金黃 + 奶油色 + 深咖啡色字體,
營造熱鬧、溫暖、食慾感,所有繁體中文字務必清晰、無拼錯、
排版整齊;菜名與價格欄位對齊俐落,看起來像出自設計師之手。提示詞重點:用明確的版面比例切分(上 60% 主視覺、下 40% 排版區、footer),讓 reasoning 階段先把版面骨架想好;菜名、描述、價格三欄分點列出(八個品項一目了然),模型才會知道要做成等距卡片;指定具體的攝影風格參考(孤味、艋舺)比寫「電影感」還精準;最後重複叮嚀「文字必須無拼錯、排版整齊」,是這代模型才有辦法穩定達成的指令——DALL-E 3 時代寫了也是白寫。實際做出來常常一次就能交件,是想驗證 GPT Image 2 文字渲染能力最直觀的題目。

適合與不適合的場景
ChatGPT 用戶不管是免費還是付費版,都直接用最新版就好了(應該也沒辦法挑選),以下討論 API 用戶。
適合切過來的情境
- 需要在圖內寫對文字:招牌、菜單、海報、UI mockup、infographic,這代差距最有感
- 多語言素材:中日韓、Hindi、Bengali 等非拉丁文字場景,GPT Image 2 是目前少數能寫對的選項
- 結構複雜的 layout:多區塊、多角色、多元件的圖,受惠於 reasoning
- 需要連網的時事題材:近期人物、產品、事件相關的視覺,搭配 ChatGPT thinking 模型有 web search 加成
可以先不換的情境
- 單純的 stock photo 風格:DALL-E 3 與 SDXL 早就夠用,沒必要為了多花成本切過來
- 對速度敏感的即時生成:reasoning 會多吃時間,如果是 chatbot 內 inline 出圖,使用體感會比 DALL-E 3 慢一些
- 單張 2K 大量批次:成本會比預期高出許多,建議先用 medium 跑出滿意的構圖再升 high 細修
- 純風格化插畫:Midjourney v7、Black Forest Labs FLUX 在某些藝術風格上仍有更獨特的味道,看品牌定位再選
小結
GPT Image 2 是這幾年生圖模型升級裡最有「世代差」感受的一次,背後的改變不只是把畫質拉到 2K,而是把 reasoning 第一次帶進生圖流程,讓模型有時間自己思考要怎麼下筆。對日常做技術部落格、做簡報、做 UI mockup、行銷素材的開發者來說,「能把字寫對」這件事直接省掉了一整段後製流程,這個體感比任何 benchmark 數字都更直接。
不過 reasoning 的代價是更慢、更貴,對成本與延遲敏感的產品端不見得要全面切過來,可以走 portfolio 思路:日常 stock 用 DALL-E 3 或 SDXL、需要文字與精準排版時切 GPT Image 2、純藝術風格交給 Midjourney 或 FLUX。本文上面的提示詞範例都可以直接拿去 ChatGPT 試試看,如果做出有趣的成果歡迎分享回來。